 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineInstructions: Scaling Synthetic Instructions to Pre-Training Scale
Jan 29, 2026Due to limited supervised training data, large language models (LLMs) are typically pre-trained via a self-supervised "predict the next word" objective on a vast amount of unstructured text data. To make the resulting model useful to users, it is further trained on a far smaller amount of "instruction-tuning" data comprised of supervised training examples of instructions and responses. To overcome the limited amount of supervised data, we propose a procedure that can transform the knowledge in internet-scale pre-training documents into billions of synthetic instruction and answer training pairs. The resulting dataset, called FineInstructions, uses ~18M instruction templates created from real user-written queries and prompts. These instruction templates are matched to and instantiated with human-written source documents from unstructured pre-training corpora. With "supervised" synthetic training data generated at this scale, an LLM can be pre-trained from scratch solely with the instruction-tuning objective, which is far more in-distribution with the expected downstream usage of LLMs (responding to user prompts). We conduct controlled token-for-token training experiments and find pre-training on FineInstructions outperforms standard pre-training and other proposed synthetic pre-training techniques on standard benchmarks measuring free-form response quality. Our resources can be found at https://huggingface.co/fineinstructions .
mStyleDistance: Multilingual Style Embeddings and their Evaluation
Feb 21, 2025Style embeddings are useful for stylistic analysis and style transfer; however, only English style embeddings have been made available. We introduce Multilingual StyleDistance (mStyleDistance), a multilingual style embedding model trained using synthetic data and contrastive learning. We train the model on data from nine languages and create a multilingual STEL-or-Content benchmark (Wegmann et al., 2022) that serves to assess the embeddings' quality. We also employ our embeddings in an authorship verification task involving different languages. Our results show that mStyleDistance embeddings outperform existing models on these multilingual style benchmarks and generalize well to unseen features and languages. We make our model publicly available at https://huggingface.co/StyleDistance/mstyledistance .
Scaling Text-Rich Image Understanding via Code-Guided Synthetic Multimodal Data Generation
Feb 20, 2025Reasoning about images with rich text, such as charts and documents, is a critical application of vision-language models (VLMs). However, VLMs often struggle in these domains due to the scarcity of diverse text-rich vision-language data. To address this challenge, we present CoSyn, a framework that leverages the coding capabilities of text-only large language models (LLMs) to automatically create synthetic text-rich multimodal data. Given input text describing a target domain (e.g., "nutrition fact labels"), CoSyn prompts an LLM to generate code (Python, HTML, LaTeX, etc.) for rendering synthetic images. With the underlying code as textual representations of the synthetic images, CoSyn can generate high-quality instruction-tuning data, again relying on a text-only LLM. Using CoSyn, we constructed a dataset comprising 400K images and 2.7M rows of vision-language instruction-tuning data. Comprehensive experiments on seven benchmarks demonstrate that models trained on our synthetic data achieve state-of-the-art performance among competitive open-source models, including Llama 3.2, and surpass proprietary models such as GPT-4V and Gemini 1.5 Flash. Furthermore, CoSyn can produce synthetic pointing data, enabling VLMs to ground information within input images, showcasing its potential for developing multimodal agents capable of acting in real-world environments.
StyleDistance: Stronger Content-Independent Style Embeddings with Synthetic Parallel Examples
Oct 16, 2024



Style representations aim to embed texts with similar writing styles closely and texts with different styles far apart, regardless of content. However, the contrastive triplets often used for training these representations may vary in both style and content, leading to potential content leakage in the representations. We introduce StyleDistance, a novel approach to training stronger content-independent style embeddings. We use a large language model to create a synthetic dataset of near-exact paraphrases with controlled style variations, and produce positive and negative examples across 40 distinct style features for precise contrastive learning. We assess the quality of our synthetic data and embeddings through human and automatic evaluations. StyleDistance enhances the content-independence of style embeddings, which generalize to real-world benchmarks and outperform leading style representations in downstream applications. Our model can be found at https://huggingface.co/StyleDistance/styledistance .
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
Latent Space Interpretation for Stylistic Analysis and Explainable Authorship Attribution
Sep 11, 2024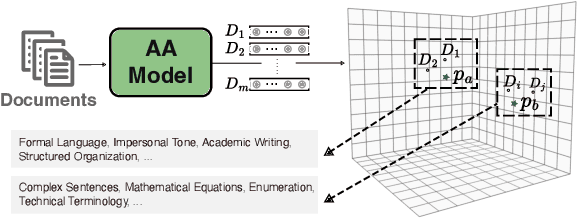
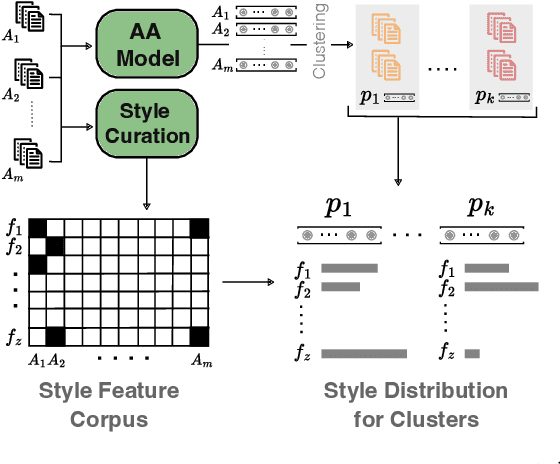

Recent state-of-the-art authorship attribution methods learn authorship representations of texts in a latent, non-interpretable space, hindering their usability in real-world applications. Our work proposes a novel approach to interpreting these learned embeddings by identifying representative points in the latent space and utilizing LLMs to generate informative natural language descriptions of the writing style of each point. We evaluate the alignment of our interpretable space with the latent one and find that it achieves the best prediction agreement compared to other baselines. Additionally, we conduct a human evaluation to assess the quality of these style descriptions, validating their utility as explanations for the latent space. Finally, we investigate whether human performance on the challenging AA task improves when aided by our system's explanations, finding an average improvement of around +20% in accuracy.
TinyStyler: Efficient Few-Shot Text Style Transfer with Authorship Embeddings
Jun 21, 2024
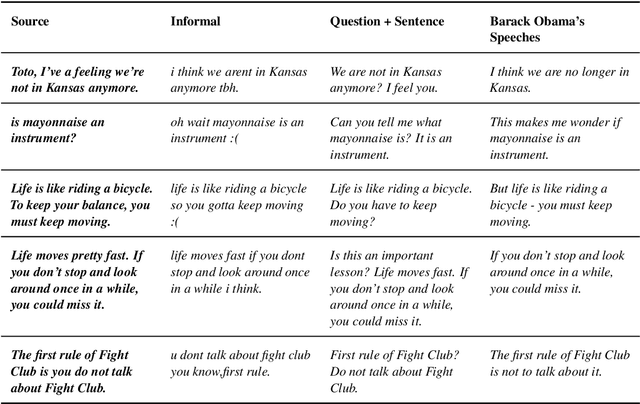
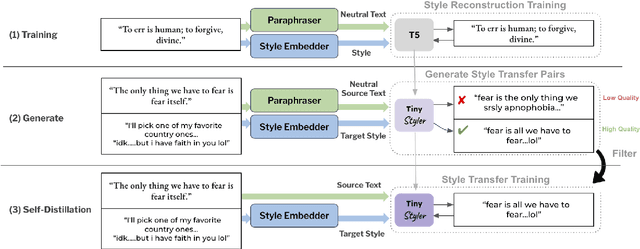
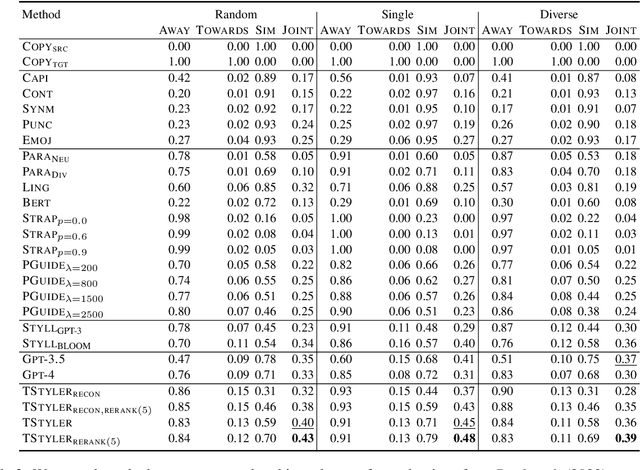
The goal of text style transfer is to transform the style of texts while preserving their original meaning, often with only a few examples of the target style. Existing style transfer methods generally rely on the few-shot capabilities of large language models or on complex controllable text generation approaches that are inefficient and underperform on fluency metrics. We introduce TinyStyler, a lightweight but effective approach, which leverages a small language model (800M params) and pre-trained authorship embeddings to perform efficient, few-shot text style transfer. We evaluate on the challenging task of authorship style transfer and find TinyStyler outperforms strong approaches such as GPT-4. We also evaluate TinyStyler's ability to perform text attribute style transfer (formal $\leftrightarrow$ informal) with automatic and human evaluations and find that the approach outperforms recent controllable text generation methods. Our model has been made publicly available at https://huggingface.co/tinystyler/tinystyler .
Large Language Models Can Self-Improve At Web Agent Tasks
May 30, 2024



Training models to act as agents that can effectively navigate and perform actions in a complex environment, such as a web browser, has typically been challenging due to lack of training data. Large language models (LLMs) have recently demonstrated some capability to navigate novel environments as agents in a zero-shot or few-shot fashion, purely guided by natural language instructions as prompts. Recent research has also demonstrated LLMs have the capability to exceed their base performance through self-improvement, i.e. fine-tuning on data generated by the model itself. In this work, we explore the extent to which LLMs can self-improve their performance as agents in long-horizon tasks in a complex environment using the WebArena benchmark. In WebArena, an agent must autonomously navigate and perform actions on web pages to achieve a specified objective. We explore fine-tuning on three distinct synthetic training data mixtures and achieve a 31\% improvement in task completion rate over the base model on the WebArena benchmark through a self-improvement procedure. We additionally contribute novel evaluation metrics for assessing the performance, robustness, capabilities, and quality of trajectories of our fine-tuned agent models to a greater degree than simple, aggregate-level benchmark scores currently used to measure self-improvement.
DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows
Feb 16, 2024Large language models (LLMs) have become a dominant and important tool for NLP researchers in a wide range of tasks. Today, many researchers use LLMs in synthetic data generation, task evaluation, fine-tuning, distillation, and other model-in-the-loop research workflows. However, challenges arise when using these models that stem from their scale, their closed source nature, and the lack of standardized tooling for these new and emerging workflows. The rapid rise to prominence of these models and these unique challenges has had immediate adverse impacts on open science and on the reproducibility of work that uses them. In this paper, we introduce DataDreamer, an open source Python library that allows researchers to write simple code to implement powerful LLM workflows. DataDreamer also helps researchers adhere to best practices that we propose to encourage open science and reproducibility. The library and documentation are available at https://github.com/datadreamer-dev/DataDreamer .
ParaGuide: Guided Diffusion Paraphrasers for Plug-and-Play Textual Style Transfer
Sep 04, 2023



Textual style transfer is the task of transforming stylistic properties of text while preserving meaning. Target "styles" can be defined in numerous ways, ranging from single attributes (e.g, formality) to authorship (e.g, Shakespeare). Previous unsupervised style-transfer approaches generally rely on significant amounts of labeled data for only a fixed set of styles or require large language models. In contrast, we introduce a novel diffusion-based framework for general-purpose style transfer that can be flexibly adapted to arbitrary target styles at inference time. Our parameter-efficient approach, ParaGuide, leverages paraphrase-conditioned diffusion models alongside gradient-based guidance from both off-the-shelf classifiers and strong existing style embedders to transform the style of text while preserving semantic information. We validate the method on the Enron Email Corpus, with both human and automatic evaluations, and find that it outperforms strong baselines on formality, sentiment, and even authorship style transfer.