 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Decision Transformer: External Memory for In-context RL
Oct 09, 2024



In-context learning (ICL) is the ability of a model to learn a new task by observing a few exemplars in its context. While prevalent in NLP, this capability has recently also been observed in Reinforcement Learning (RL) settings. Prior in-context RL methods, however, require entire episodes in the agent's context. Given that complex environments typically lead to long episodes with sparse rewards, these methods are constrained to simple environments with short episodes. To address these challenges, we introduce Retrieval-Augmented Decision Transformer (RA-DT). RA-DT employs an external memory mechanism to store past experiences from which it retrieves only sub-trajectories relevant for the current situation. The retrieval component in RA-DT does not require training and can be entirely domain-agnostic. We evaluate the capabilities of RA-DT on grid-world environments, robotics simulations, and procedurally-generated video games. On grid-worlds, RA-DT outperforms baselines, while using only a fraction of their context length. Furthermore, we illuminate the limitations of current in-context RL methods on complex environments and discuss future directions. To facilitate future research, we release datasets for four of the considered environments.
Contrastive Abstraction for Reinforcement Learning
Oct 01, 2024



Learning agents with reinforcement learning is difficult when dealing with long trajectories that involve a large number of states. To address these learning problems effectively, the number of states can be reduced by abstract representations that cluster states. In principle, deep reinforcement learning can find abstract states, but end-to-end learning is unstable. We propose contrastive abstraction learning to find abstract states, where we assume that successive states in a trajectory belong to the same abstract state. Such abstract states may be basic locations, achieved subgoals, inventory, or health conditions. Contrastive abstraction learning first constructs clusters of state representations by contrastive learning and then applies modern Hopfield networks to determine the abstract states. The first phase of contrastive abstraction learning is self-supervised learning, where contrastive learning forces states with sequential proximity to have similar representations. The second phase uses modern Hopfield networks to map similar state representations to the same fixed point, i.e.\ to an abstract state. The level of abstraction can be adjusted by determining the number of fixed points of the modern Hopfield network. Furthermore, \textit{contrastive abstraction learning} does not require rewards and facilitates efficient reinforcement learning for a wide range of downstream tasks. Our experiments demonstrate the effectiveness of contrastive abstraction learning for reinforcement learning.
Large Language Models Can Self-Improve At Web Agent Tasks
May 30, 2024



Training models to act as agents that can effectively navigate and perform actions in a complex environment, such as a web browser, has typically been challenging due to lack of training data. Large language models (LLMs) have recently demonstrated some capability to navigate novel environments as agents in a zero-shot or few-shot fashion, purely guided by natural language instructions as prompts. Recent research has also demonstrated LLMs have the capability to exceed their base performance through self-improvement, i.e. fine-tuning on data generated by the model itself. In this work, we explore the extent to which LLMs can self-improve their performance as agents in long-horizon tasks in a complex environment using the WebArena benchmark. In WebArena, an agent must autonomously navigate and perform actions on web pages to achieve a specified objective. We explore fine-tuning on three distinct synthetic training data mixtures and achieve a 31\% improvement in task completion rate over the base model on the WebArena benchmark through a self-improvement procedure. We additionally contribute novel evaluation metrics for assessing the performance, robustness, capabilities, and quality of trajectories of our fine-tuned agent models to a greater degree than simple, aggregate-level benchmark scores currently used to measure self-improvement.
SITTA: A Semantic Image-Text Alignment for Image Captioning
Jul 10, 2023Textual and semantic comprehension of images is essential for generating proper captions. The comprehension requires detection of objects, modeling of relations between them, an assessment of the semantics of the scene and, finally, representing the extracted knowledge in a language space. To achieve rich language capabilities while ensuring good image-language mappings, pretrained language models (LMs) were conditioned on pretrained multi-modal (image-text) models that allow for image inputs. This requires an alignment of the image representation of the multi-modal model with the language representations of a generative LM. However, it is not clear how to best transfer semantics detected by the vision encoder of the multi-modal model to the LM. We introduce two novel ways of constructing a linear mapping that successfully transfers semantics between the embedding spaces of the two pretrained models. The first aligns the embedding space of the multi-modal language encoder with the embedding space of the pretrained LM via token correspondences. The latter leverages additional data that consists of image-text pairs to construct the mapping directly from vision to language space. Using our semantic mappings, we unlock image captioning for LMs without access to gradient information. By using different sources of data we achieve strong captioning performance on MS-COCO and Flickr30k datasets. Even in the face of limited data, our method partly exceeds the performance of other zero-shot and even finetuned competitors. Our ablation studies show that even LMs at a scale of merely 250M parameters can generate decent captions employing our semantic mappings. Our approach makes image captioning more accessible for institutions with restricted computational resources.
Learning to Modulate pre-trained Models in RL
Jun 26, 2023Reinforcement Learning (RL) has been successful in various domains like robotics, game playing, and simulation. While RL agents have shown impressive capabilities in their specific tasks, they insufficiently adapt to new tasks. In supervised learning, this adaptation problem is addressed by large-scale pre-training followed by fine-tuning to new down-stream tasks. Recently, pre-training on multiple tasks has been gaining traction in RL. However, fine-tuning a pre-trained model often suffers from catastrophic forgetting, that is, the performance on the pre-training tasks deteriorates when fine-tuning on new tasks. To investigate the catastrophic forgetting phenomenon, we first jointly pre-train a model on datasets from two benchmark suites, namely Meta-World and DMControl. Then, we evaluate and compare a variety of fine-tuning methods prevalent in natural language processing, both in terms of performance on new tasks, and how well performance on pre-training tasks is retained. Our study shows that with most fine-tuning approaches, the performance on pre-training tasks deteriorates significantly. Therefore, we propose a novel method, Learning-to-Modulate (L2M), that avoids the degradation of learned skills by modulating the information flow of the frozen pre-trained model via a learnable modulation pool. Our method achieves state-of-the-art performance on the Continual-World benchmark, while retaining performance on the pre-training tasks. Finally, to aid future research in this area, we release a dataset encompassing 50 Meta-World and 16 DMControl tasks.
Semantic HELM: An Interpretable Memory for Reinforcement Learning
Jun 15, 2023Reinforcement learning agents deployed in the real world often have to cope with partially observable environments. Therefore, most agents employ memory mechanisms to approximate the state of the environment. Recently, there have been impressive success stories in mastering partially observable environments, mostly in the realm of computer games like Dota 2, StarCraft II, or MineCraft. However, none of these methods are interpretable in the sense that it is not comprehensible for humans how the agent decides which actions to take based on its inputs. Yet, human understanding is necessary in order to deploy such methods in high-stake domains like autonomous driving or medical applications. We propose a novel memory mechanism that operates on human language to illuminate the decision-making process. First, we use CLIP to associate visual inputs with language tokens. Then we feed these tokens to a pretrained language model that serves the agent as memory and provides it with a coherent and interpretable representation of the past. Our memory mechanism achieves state-of-the-art performance in environments where memorizing the past is crucial to solve tasks. Further, we present situations where our memory component excels or fails to demonstrate strengths and weaknesses of our new approach.
Understanding the Effects of Dataset Characteristics on Offline Reinforcement Learning
Nov 08, 2021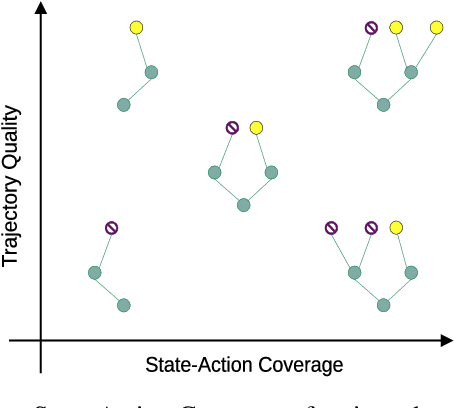
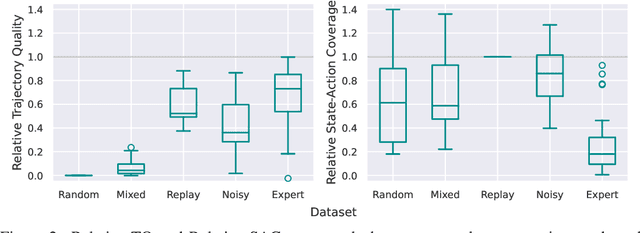
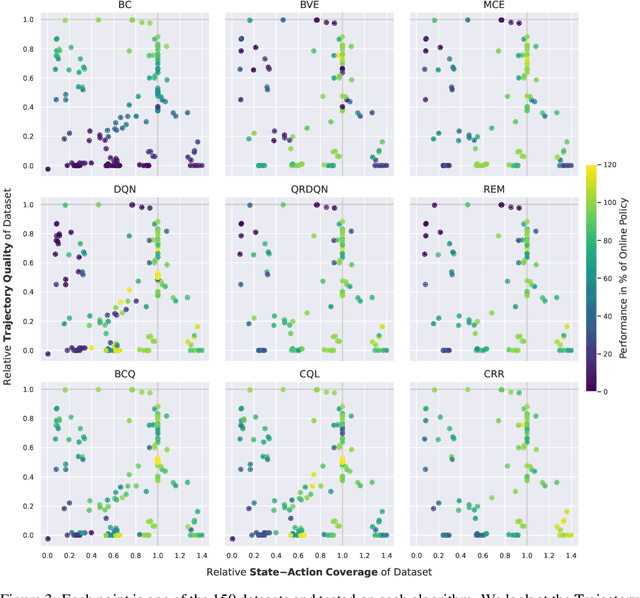

In real world, affecting the environment by a weak policy can be expensive or very risky, therefore hampers real world applications of reinforcement learning. Offline Reinforcement Learning (RL) can learn policies from a given dataset without interacting with the environment. However, the dataset is the only source of information for an Offline RL algorithm and determines the performance of the learned policy. We still lack studies on how dataset characteristics influence different Offline RL algorithms. Therefore, we conducted a comprehensive empirical analysis of how dataset characteristics effect the performance of Offline RL algorithms for discrete action environments. A dataset is characterized by two metrics: (1) the average dataset return measured by the Trajectory Quality (TQ) and (2) the coverage measured by the State-Action Coverage (SACo). We found that variants of the off-policy Deep Q-Network family require datasets with high SACo to perform well. Algorithms that constrain the learned policy towards the given dataset perform well for datasets with high TQ or SACo. For datasets with high TQ, Behavior Cloning outperforms or performs similarly to the best Offline RL algorithms.
Align-RUDDER: Learning From Few Demonstrations by Reward Redistribution
Sep 29, 2020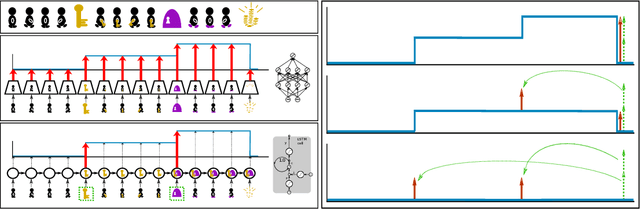


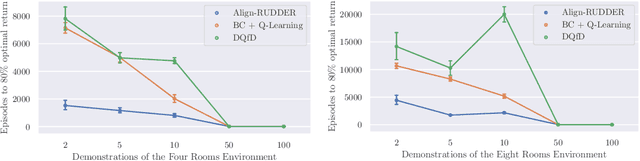
Reinforcement Learning algorithms require a large number of samples to solve complex tasks with sparse and delayed rewards. Complex tasks can often be hierarchically decomposed into sub-tasks. A step in the Q-function can be associated with solving a sub-task, where the expectation of the return increases. RUDDER has been introduced to identify these steps and then redistribute reward to them, thus immediately giving reward if sub-tasks are solved. Since the problem of delayed rewards is mitigated, learning is considerably sped up. However, for complex tasks, current exploration strategies as deployed in RUDDER struggle with discovering episodes with high rewards. Therefore, we assume that episodes with high rewards are given as demonstrations and do not have to be discovered by exploration. Typically the number of demonstrations is small and RUDDER's LSTM model as a deep learning method does not learn well. Hence, we introduce Align-RUDDER, which is RUDDER with two major modifications. First, Align-RUDDER assumes that episodes with high rewards are given as demonstrations, replacing RUDDER's safe exploration and lessons replay buffer. Second, we replace RUDDER's LSTM model by a profile model that is obtained from multiple sequence alignment of demonstrations. Profile models can be constructed from as few as two demonstrations as known from bioinformatics. Align-RUDDER inherits the concept of reward redistribution, which considerably reduces the delay of rewards, thus speeding up learning. Align-RUDDER outperforms competitors on complex artificial tasks with delayed reward and few demonstrations. On the MineCraft ObtainDiamond task, Align-RUDDER is able to mine a diamond, though not frequently. Github: https://github.com/ml-jku/align-rudder, YouTube: https://youtu.be/HO-_8ZUl-UY
Large-scale ligand-based virtual screening for SARS-CoV-2 inhibitors using deep neural networks
Apr 03, 2020


Due to the current severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) pandemic, there is an urgent need for novel therapies and drugs. We conducted a large-scale virtual screening for small molecules that are potential CoV-2 inhibitors. To this end, we utilized "ChemAI", a deep neural network trained on more than 220M data points across 3.6M molecules from three public drug-discovery databases. With ChemAI, we screened and ranked one billion molecules from the ZINC database for favourable effects against CoV-2. We then reduced the result to the 30,000 top-ranked compounds, which are readily accessible and purchasable via the ZINC database. Additionally, we screened the DrugBank using ChemAI to allow for drug repurposing, which would be a fast way towards a therapy. We provide these top-ranked compounds of ZINC and DrugBank as a library for further screening with bioassays at https://github.com/ml-jku/sars-cov-inhibitors-chemai.
Detecting cutaneous basal cell carcinomas in ultra-high resolution and weakly labelled histopathological images
Dec 02, 2019

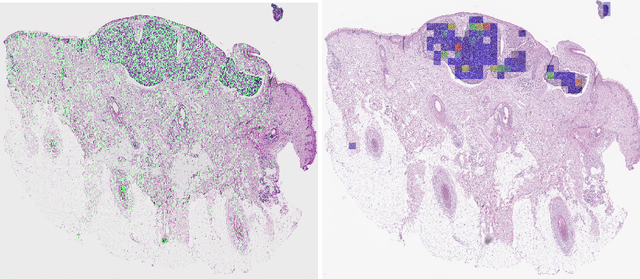
Diagnosing basal cell carcinomas (BCC), one of the most common cutaneous malignancies in humans, is a task regularly performed by pathologists and dermato-pathologists. Improving histological diagnosis by providing diagnosis suggestions, i.e. computer-assisted diagnoses is actively researched to improve safety, quality and efficiency. Increasingly, machine learning methods are applied due to their superior performance. However, typical images obtained by scanning histological sections often have a resolution that is prohibitive for processing with current state-of-the-art neural networks. Furthermore, the data pose a problem of weak labels, since only a tiny fraction of the image is indicative of the disease class, whereas a large fraction of the image is highly similar to the non-disease class. The aim of this study is to evaluate whether it is possible to detect basal cell carcinomas in histological sections using attention-based deep learning models and to overcome the ultra-high resolution and the weak labels of whole slide images. We demonstrate that attention-based models can indeed yield almost perfect classification performance with an AUC of 0.99.