 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign-RUDDER: Learning From Few Demonstrations by Reward Redistribution
Sep 29, 2020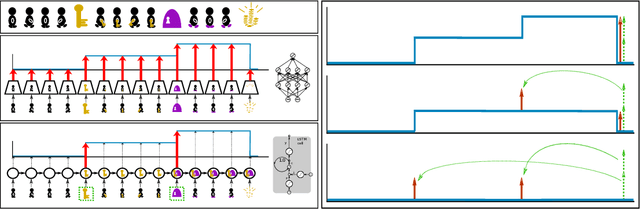


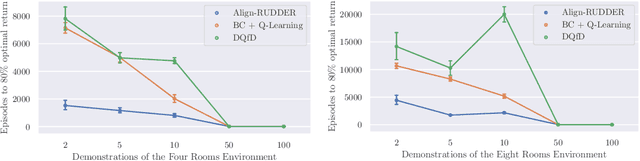
Reinforcement Learning algorithms require a large number of samples to solve complex tasks with sparse and delayed rewards. Complex tasks can often be hierarchically decomposed into sub-tasks. A step in the Q-function can be associated with solving a sub-task, where the expectation of the return increases. RUDDER has been introduced to identify these steps and then redistribute reward to them, thus immediately giving reward if sub-tasks are solved. Since the problem of delayed rewards is mitigated, learning is considerably sped up. However, for complex tasks, current exploration strategies as deployed in RUDDER struggle with discovering episodes with high rewards. Therefore, we assume that episodes with high rewards are given as demonstrations and do not have to be discovered by exploration. Typically the number of demonstrations is small and RUDDER's LSTM model as a deep learning method does not learn well. Hence, we introduce Align-RUDDER, which is RUDDER with two major modifications. First, Align-RUDDER assumes that episodes with high rewards are given as demonstrations, replacing RUDDER's safe exploration and lessons replay buffer. Second, we replace RUDDER's LSTM model by a profile model that is obtained from multiple sequence alignment of demonstrations. Profile models can be constructed from as few as two demonstrations as known from bioinformatics. Align-RUDDER inherits the concept of reward redistribution, which considerably reduces the delay of rewards, thus speeding up learning. Align-RUDDER outperforms competitors on complex artificial tasks with delayed reward and few demonstrations. On the MineCraft ObtainDiamond task, Align-RUDDER is able to mine a diamond, though not frequently. Github: https://github.com/ml-jku/align-rudder, YouTube: https://youtu.be/HO-_8ZUl-UY
Explaining and Interpreting LSTMs
Sep 25, 2019

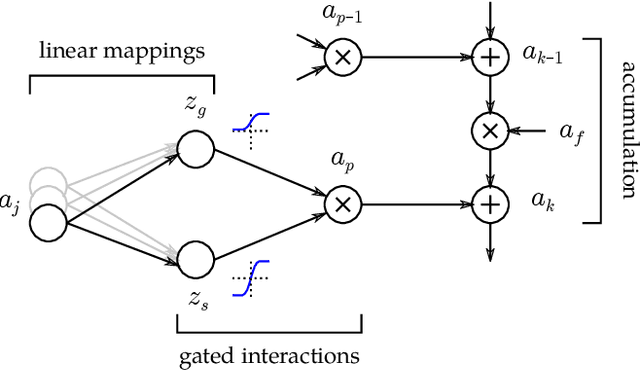
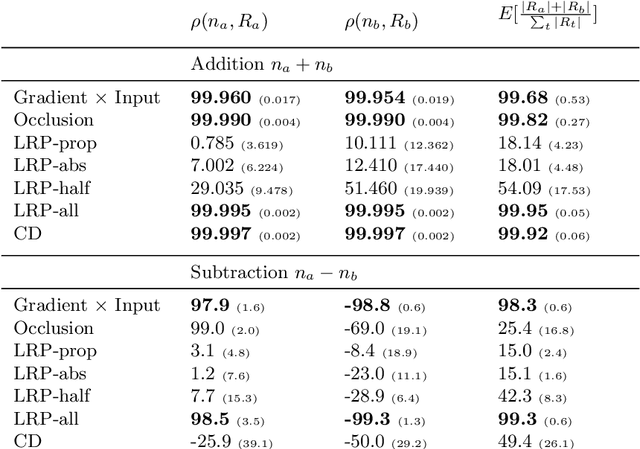
While neural networks have acted as a strong unifying force in the design of modern AI systems, the neural network architectures themselves remain highly heterogeneous due to the variety of tasks to be solved. In this chapter, we explore how to adapt the Layer-wise Relevance Propagation (LRP) technique used for explaining the predictions of feed-forward networks to the LSTM architecture used for sequential data modeling and forecasting. The special accumulators and gated interactions present in the LSTM require both a new propagation scheme and an extension of the underlying theoretical framework to deliver faithful explanations.
RUDDER: Return Decomposition for Delayed Rewards
Jun 20, 2018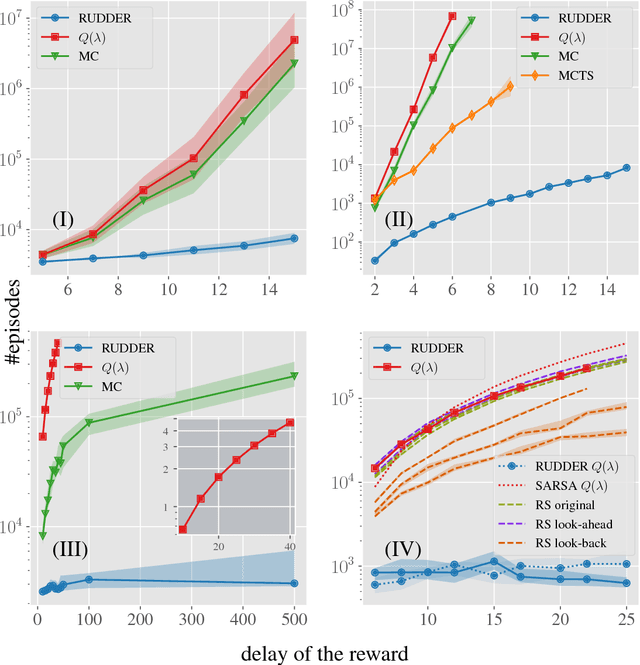

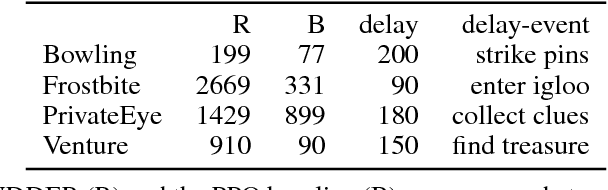
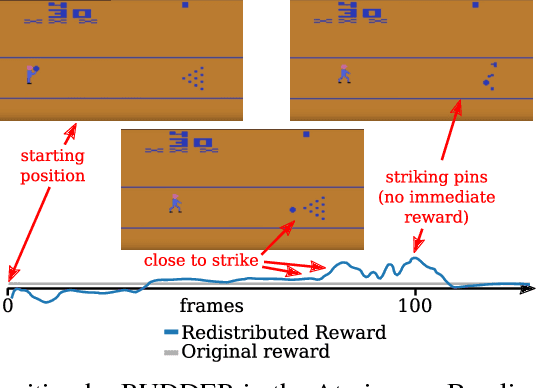
We propose a novel reinforcement learning approach for finite Markov decision processes (MDPs) with delayed rewards. In this work, biases of temporal difference (TD) estimates are proved to be corrected only exponentially slowly in the number of delay steps. Furthermore, variances of Monte Carlo (MC) estimates are proved to increase the variance of other estimates, the number of which can exponentially grow in the number of delay steps. We introduce RUDDER, a return decomposition method, which creates a new MDP with same optimal policies as the original MDP but with redistributed rewards that have largely reduced delays. If the return decomposition is optimal, then the new MDP does not have delayed rewards and TD estimates are unbiased. In this case, the rewards track Q-values so that the future expected reward is always zero. We experimentally confirm our theoretical results on bias and variance of TD and MC estimates. On artificial tasks with different lengths of reward delays, we show that RUDDER is exponentially faster than TD, MC, and MC Tree Search (MCTS). RUDDER outperforms rainbow, A3C, DDQN, Distributional DQN, Dueling DDQN, Noisy DQN, and Prioritized DDQN on the delayed reward Atari game Venture in only a fraction of the learning time. RUDDER considerably improves the state-of-the-art on the delayed reward Atari game Bowling in much less learning time. Source code is available at https://github.com/ml-jku/baselines-rudder, with demonstration videos at https://goo.gl/EQerZV.