 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign-RUDDER: Learning From Few Demonstrations by Reward Redistribution
Paper and Code
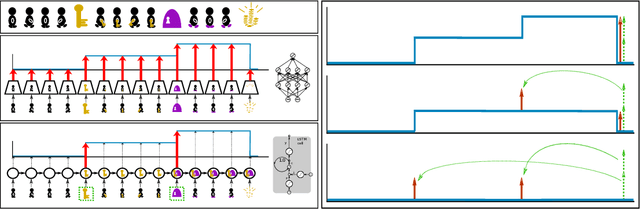


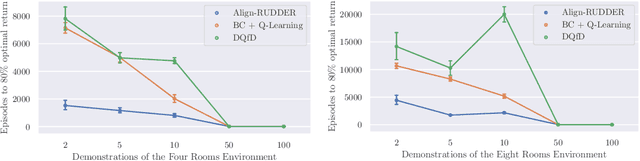
Reinforcement Learning algorithms require a large number of samples to solve complex tasks with sparse and delayed rewards. Complex tasks can often be hierarchically decomposed into sub-tasks. A step in the Q-function can be associated with solving a sub-task, where the expectation of the return increases. RUDDER has been introduced to identify these steps and then redistribute reward to them, thus immediately giving reward if sub-tasks are solved. Since the problem of delayed rewards is mitigated, learning is considerably sped up. However, for complex tasks, current exploration strategies as deployed in RUDDER struggle with discovering episodes with high rewards. Therefore, we assume that episodes with high rewards are given as demonstrations and do not have to be discovered by exploration. Typically the number of demonstrations is small and RUDDER's LSTM model as a deep learning method does not learn well. Hence, we introduce Align-RUDDER, which is RUDDER with two major modifications. First, Align-RUDDER assumes that episodes with high rewards are given as demonstrations, replacing RUDDER's safe exploration and lessons replay buffer. Second, we replace RUDDER's LSTM model by a profile model that is obtained from multiple sequence alignment of demonstrations. Profile models can be constructed from as few as two demonstrations as known from bioinformatics. Align-RUDDER inherits the concept of reward redistribution, which considerably reduces the delay of rewards, thus speeding up learning. Align-RUDDER outperforms competitors on complex artificial tasks with delayed reward and few demonstrations. On the MineCraft ObtainDiamond task, Align-RUDDER is able to mine a diamond, though not frequently. Github: https://github.com/ml-jku/align-rudder, YouTube: https://youtu.be/HO-_8ZUl-UY