 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexLSTM 7B: A Recurrent LLM for Fast and Efficient Inference
Mar 17, 2025Recent breakthroughs in solving reasoning, math and coding problems with Large Language Models (LLMs) have been enabled by investing substantial computation budgets at inference time. Therefore, inference speed is one of the most critical properties of LLM architectures, and there is a growing need for LLMs that are efficient and fast at inference. Recently, LLMs built on the xLSTM architecture have emerged as a powerful alternative to Transformers, offering linear compute scaling with sequence length and constant memory usage, both highly desirable properties for efficient inference. However, such xLSTM-based LLMs have yet to be scaled to larger models and assessed and compared with respect to inference speed and efficiency. In this work, we introduce xLSTM 7B, a 7-billion-parameter LLM that combines xLSTM's architectural benefits with targeted optimizations for fast and efficient inference. Our experiments demonstrate that xLSTM 7B achieves performance on downstream tasks comparable to other similar-sized LLMs, while providing significantly faster inference speeds and greater efficiency compared to Llama- and Mamba-based LLMs. These results establish xLSTM 7B as the fastest and most efficient 7B LLM, offering a solution for tasks that require large amounts of test-time computation. Our work highlights xLSTM's potential as a foundational architecture for methods building on heavy use of LLM inference. Our model weights, model code and training code are open-source.
Reinforcement Learning Based Power Grid Day-Ahead Planning and AI-Assisted Control
Feb 15, 2023



The ongoing transition to renewable energy is increasing the share of fluctuating power sources like wind and solar, raising power grid volatility and making grid operation increasingly complex and costly. In our prior work, we have introduced a congestion management approach consisting of a redispatching optimizer combined with a machine learning-based topology optimization agent. Compared to a typical redispatching-only agent, it was able to keep a simulated grid in operation longer while at the same time reducing operational cost. Our approach also ranked 1st in the L2RPN 2022 competition initiated by RTE, Europe's largest grid operator. The aim of this paper is to bring this promising technology closer to the real world of power grid operation. We deploy RL-based agents in two settings resembling established workflows, AI-assisted day-ahead planning and realtime control, in an attempt to show the benefits and caveats of this new technology. We then analyse congestion, redispatching and switching profiles, and elementary sensitivity analysis providing a glimpse of operation robustness. While there is still a long way to a real control room, we believe that this paper and the associated prototypes help to narrow the gap and pave the way for a safe deployment of RL agents in tomorrow's power grids.
Power Grid Congestion Management via Topology Optimization with AlphaZero
Nov 10, 2022



The energy sector is facing rapid changes in the transition towards clean renewable sources. However, the growing share of volatile, fluctuating renewable generation such as wind or solar energy has already led to an increase in power grid congestion and network security concerns. Grid operators mitigate these by modifying either generation or demand (redispatching, curtailment, flexible loads). Unfortunately, redispatching of fossil generators leads to excessive grid operation costs and higher emissions, which is in direct opposition to the decarbonization of the energy sector. In this paper, we propose an AlphaZero-based grid topology optimization agent as a non-costly, carbon-free congestion management alternative. Our experimental evaluation confirms the potential of topology optimization for power grid operation, achieves a reduction of the average amount of required redispatching by 60%, and shows the interoperability with traditional congestion management methods. Our approach also ranked 1st in the WCCI 2022 Learning to Run a Power Network (L2RPN) competition. Based on our findings, we identify and discuss open research problems as well as technical challenges for a productive system on a real power grid.
Align-RUDDER: Learning From Few Demonstrations by Reward Redistribution
Sep 29, 2020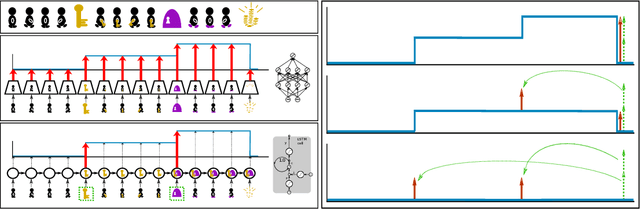


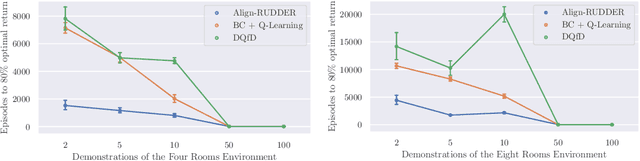
Reinforcement Learning algorithms require a large number of samples to solve complex tasks with sparse and delayed rewards. Complex tasks can often be hierarchically decomposed into sub-tasks. A step in the Q-function can be associated with solving a sub-task, where the expectation of the return increases. RUDDER has been introduced to identify these steps and then redistribute reward to them, thus immediately giving reward if sub-tasks are solved. Since the problem of delayed rewards is mitigated, learning is considerably sped up. However, for complex tasks, current exploration strategies as deployed in RUDDER struggle with discovering episodes with high rewards. Therefore, we assume that episodes with high rewards are given as demonstrations and do not have to be discovered by exploration. Typically the number of demonstrations is small and RUDDER's LSTM model as a deep learning method does not learn well. Hence, we introduce Align-RUDDER, which is RUDDER with two major modifications. First, Align-RUDDER assumes that episodes with high rewards are given as demonstrations, replacing RUDDER's safe exploration and lessons replay buffer. Second, we replace RUDDER's LSTM model by a profile model that is obtained from multiple sequence alignment of demonstrations. Profile models can be constructed from as few as two demonstrations as known from bioinformatics. Align-RUDDER inherits the concept of reward redistribution, which considerably reduces the delay of rewards, thus speeding up learning. Align-RUDDER outperforms competitors on complex artificial tasks with delayed reward and few demonstrations. On the MineCraft ObtainDiamond task, Align-RUDDER is able to mine a diamond, though not frequently. Github: https://github.com/ml-jku/align-rudder, YouTube: https://youtu.be/HO-_8ZUl-UY