 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Based Power Grid Day-Ahead Planning and AI-Assisted Control
Feb 15, 2023



The ongoing transition to renewable energy is increasing the share of fluctuating power sources like wind and solar, raising power grid volatility and making grid operation increasingly complex and costly. In our prior work, we have introduced a congestion management approach consisting of a redispatching optimizer combined with a machine learning-based topology optimization agent. Compared to a typical redispatching-only agent, it was able to keep a simulated grid in operation longer while at the same time reducing operational cost. Our approach also ranked 1st in the L2RPN 2022 competition initiated by RTE, Europe's largest grid operator. The aim of this paper is to bring this promising technology closer to the real world of power grid operation. We deploy RL-based agents in two settings resembling established workflows, AI-assisted day-ahead planning and realtime control, in an attempt to show the benefits and caveats of this new technology. We then analyse congestion, redispatching and switching profiles, and elementary sensitivity analysis providing a glimpse of operation robustness. While there is still a long way to a real control room, we believe that this paper and the associated prototypes help to narrow the gap and pave the way for a safe deployment of RL agents in tomorrow's power grids.
Power Grid Congestion Management via Topology Optimization with AlphaZero
Nov 10, 2022



The energy sector is facing rapid changes in the transition towards clean renewable sources. However, the growing share of volatile, fluctuating renewable generation such as wind or solar energy has already led to an increase in power grid congestion and network security concerns. Grid operators mitigate these by modifying either generation or demand (redispatching, curtailment, flexible loads). Unfortunately, redispatching of fossil generators leads to excessive grid operation costs and higher emissions, which is in direct opposition to the decarbonization of the energy sector. In this paper, we propose an AlphaZero-based grid topology optimization agent as a non-costly, carbon-free congestion management alternative. Our experimental evaluation confirms the potential of topology optimization for power grid operation, achieves a reduction of the average amount of required redispatching by 60%, and shows the interoperability with traditional congestion management methods. Our approach also ranked 1st in the WCCI 2022 Learning to Run a Power Network (L2RPN) competition. Based on our findings, we identify and discuss open research problems as well as technical challenges for a productive system on a real power grid.
Align-RUDDER: Learning From Few Demonstrations by Reward Redistribution
Sep 29, 2020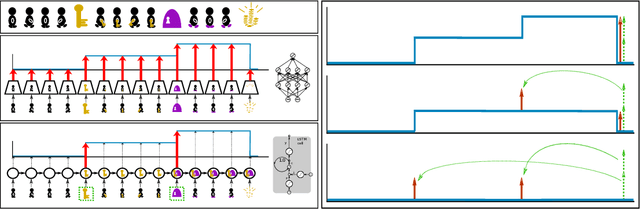


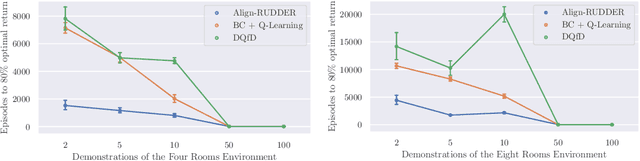
Reinforcement Learning algorithms require a large number of samples to solve complex tasks with sparse and delayed rewards. Complex tasks can often be hierarchically decomposed into sub-tasks. A step in the Q-function can be associated with solving a sub-task, where the expectation of the return increases. RUDDER has been introduced to identify these steps and then redistribute reward to them, thus immediately giving reward if sub-tasks are solved. Since the problem of delayed rewards is mitigated, learning is considerably sped up. However, for complex tasks, current exploration strategies as deployed in RUDDER struggle with discovering episodes with high rewards. Therefore, we assume that episodes with high rewards are given as demonstrations and do not have to be discovered by exploration. Typically the number of demonstrations is small and RUDDER's LSTM model as a deep learning method does not learn well. Hence, we introduce Align-RUDDER, which is RUDDER with two major modifications. First, Align-RUDDER assumes that episodes with high rewards are given as demonstrations, replacing RUDDER's safe exploration and lessons replay buffer. Second, we replace RUDDER's LSTM model by a profile model that is obtained from multiple sequence alignment of demonstrations. Profile models can be constructed from as few as two demonstrations as known from bioinformatics. Align-RUDDER inherits the concept of reward redistribution, which considerably reduces the delay of rewards, thus speeding up learning. Align-RUDDER outperforms competitors on complex artificial tasks with delayed reward and few demonstrations. On the MineCraft ObtainDiamond task, Align-RUDDER is able to mine a diamond, though not frequently. Github: https://github.com/ml-jku/align-rudder, YouTube: https://youtu.be/HO-_8ZUl-UY
The Receptive Field as a Regularizer in Deep Convolutional Neural Networks for Acoustic Scene Classification
Jul 03, 2019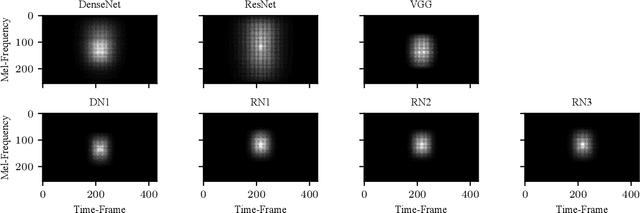
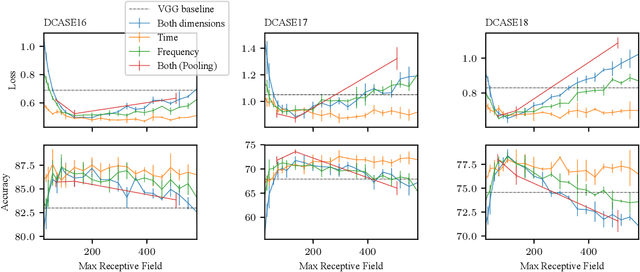
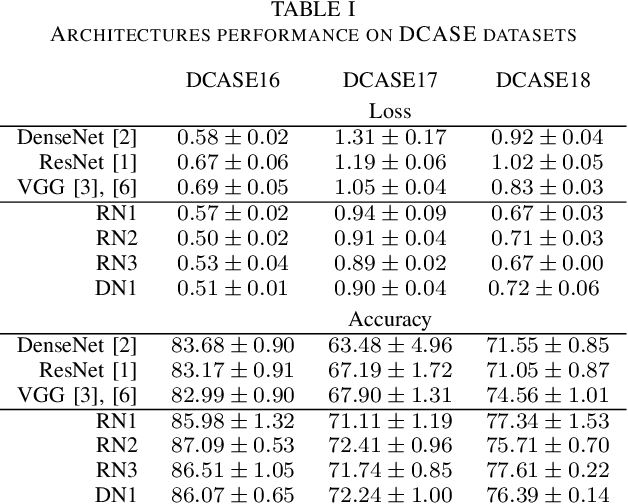

Convolutional Neural Networks (CNNs) have had great success in many machine vision as well as machine audition tasks. Many image recognition network architectures have consequently been adapted for audio processing tasks. However, despite some successes, the performance of many of these did not translate from the image to the audio domain. For example, very deep architectures such as ResNet and DenseNet, which significantly outperform VGG in image recognition, do not perform better in audio processing tasks such as Acoustic Scene Classification (ASC). In this paper, we investigate the reasons why such powerful architectures perform worse in ASC compared to simpler models (e.g., VGG). To this end, we analyse the receptive field (RF) of these CNNs and demonstrate the importance of the RF to the generalization capability of the models. Using our receptive field analysis, we adapt both ResNet and DenseNet, achieving state-of-the-art performance and eventually outperforming the VGG-based models. We introduce systematic ways of adapting the RF in CNNs, and present results on three data sets that show how changing the RF over the time and frequency dimensions affects a model's performance. Our experimental results show that very small or very large RFs can cause performance degradation, but deep models can be made to generalize well by carefully choosing an appropriate RF size within a certain range.
Learning Soft-Attention Models for Tempo-invariant Audio-Sheet Music Retrieval
Jun 26, 2019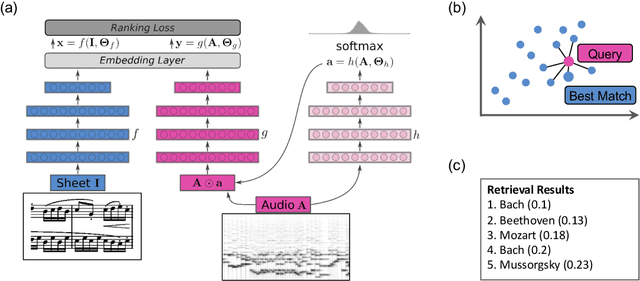
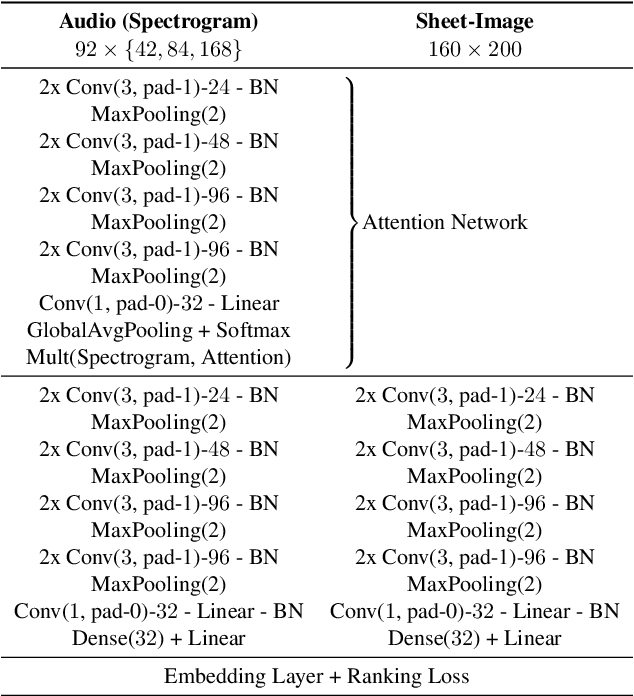
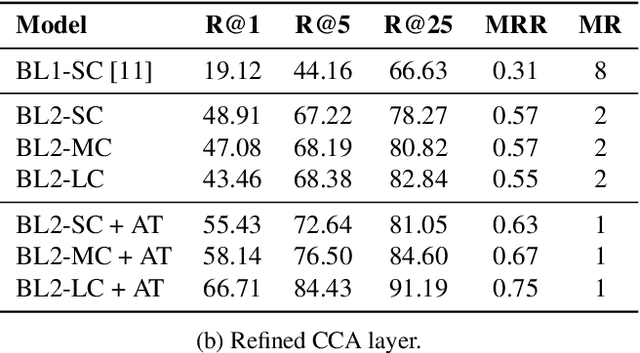

Connecting large libraries of digitized audio recordings to their corresponding sheet music images has long been a motivation for researchers to develop new cross-modal retrieval systems. In recent years, retrieval systems based on embedding space learning with deep neural networks got a step closer to fulfilling this vision. However, global and local tempo deviations in the music recordings still require careful tuning of the amount of temporal context given to the system. In this paper, we address this problem by introducing an additional soft-attention mechanism on the audio input. Quantitative and qualitative results on synthesized piano data indicate that this attention increases the robustness of the retrieval system by focusing on different parts of the input representation based on the tempo of the audio. Encouraged by these results, we argue for the potential of attention models as a very general tool for many MIR tasks.
Attention as a Perspective for Learning Tempo-invariant Audio Queries
Sep 15, 2018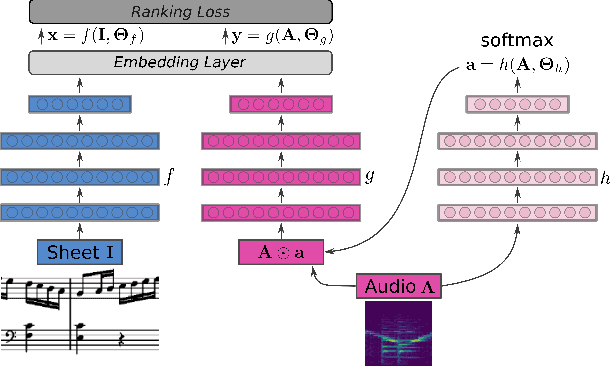


Current models for audio--sheet music retrieval via multimodal embedding space learning use convolutional neural networks with a fixed-size window for the input audio. Depending on the tempo of a query performance, this window captures more or less musical content, while notehead density in the score is largely tempo-independent. In this work we address this disparity with a soft attention mechanism, which allows the model to encode only those parts of an audio excerpt that are most relevant with respect to efficient query codes. Empirical results on classical piano music indicate that attention is beneficial for retrieval performance, and exhibits intuitively appealing behavior.
Learning to Listen, Read, and Follow: Score Following as a Reinforcement Learning Game
Jul 17, 2018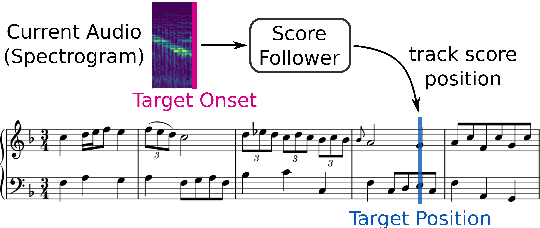


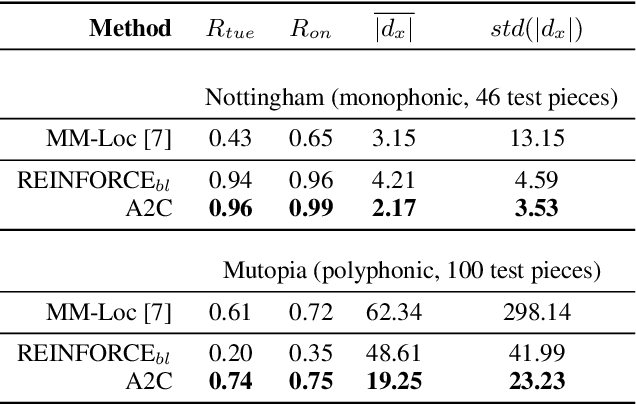
Score following is the process of tracking a musical performance (audio) with respect to a known symbolic representation (a score). We start this paper by formulating score following as a multimodal Markov Decision Process, the mathematical foundation for sequential decision making. Given this formal definition, we address the score following task with state-of-the-art deep reinforcement learning (RL) algorithms such as synchronous advantage actor critic (A2C). In particular, we design multimodal RL agents that simultaneously learn to listen to music, read the scores from images of sheet music, and follow the audio along in the sheet, in an end-to-end fashion. All this behavior is learned entirely from scratch, based on a weak and potentially delayed reward signal that indicates to the agent how close it is to the correct position in the score. Besides discussing the theoretical advantages of this learning paradigm, we show in experiments that it is in fact superior compared to previously proposed methods for score following in raw sheet music images.
Deep Within-Class Covariance Analysis for Acoustic Scene Classification
Nov 10, 2017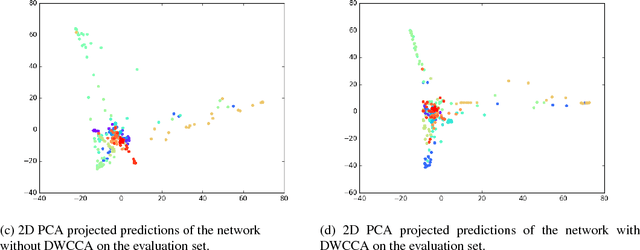

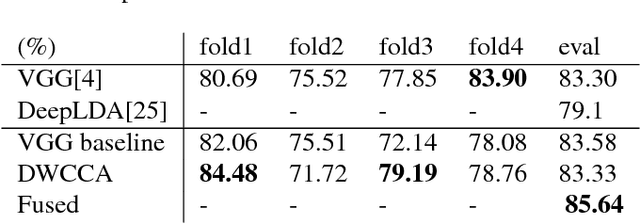
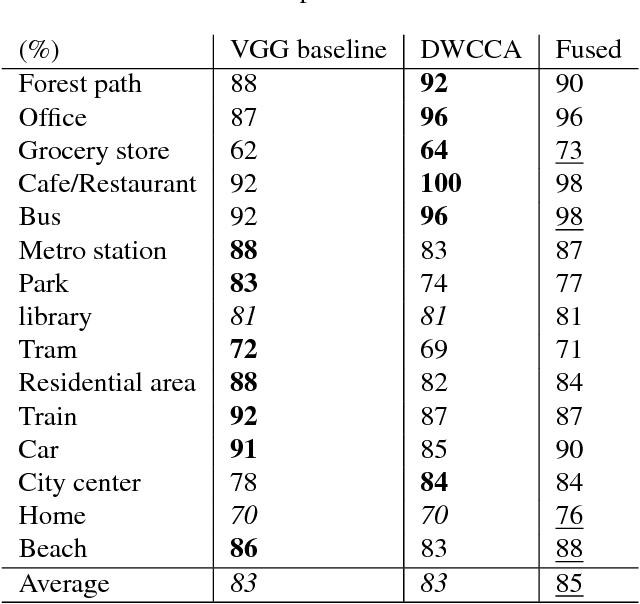
Within-Class Covariance Normalization (WCCN) is a powerful post-processing method for normalizing the within-class covariance of a set of data points. WCCN projects the observations into a linear sub-space where the within-class variability is reduced. This property has proven to be beneficial in subsequent recognition tasks. The central idea of this paper is to reformulate the classic WCCN as a Deep Neural Network (DNN) compatible version. We propose the Deep WithinClass Covariance Analysis (DWCCA) which can be incorporated in a DNN architecture. This formulation enables us to exploit the beneficial properties of WCCN, and still allows for training with Stochastic Gradient Descent (SGD) in an end-to-end fashion. We investigate the advantages of DWCCA on deep neural networks with convolutional layers for supervised learning. Our results on Acoustic Scene Classification show that via DWCCA we can achieves equal or superior performance in a VGG-style deep neural network.
A Hybrid Approach with Multi-channel I-Vectors and Convolutional Neural Networks for Acoustic Scene Classification
Jun 20, 2017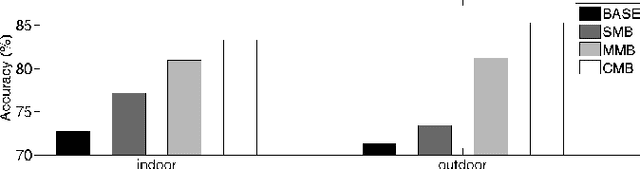

In Acoustic Scene Classification (ASC) two major approaches have been followed . While one utilizes engineered features such as mel-frequency-cepstral-coefficients (MFCCs), the other uses learned features that are the outcome of an optimization algorithm. I-vectors are the result of a modeling technique that usually takes engineered features as input. It has been shown that standard MFCCs extracted from monaural audio signals lead to i-vectors that exhibit poor performance, especially on indoor acoustic scenes. At the same time, Convolutional Neural Networks (CNNs) are well known for their ability to learn features by optimizing their filters. They have been applied on ASC and have shown promising results. In this paper, we first propose a novel multi-channel i-vector extraction and scoring scheme for ASC, improving their performance on indoor and outdoor scenes. Second, we propose a CNN architecture that achieves promising ASC results. Further, we show that i-vectors and CNNs capture complementary information from acoustic scenes. Finally, we propose a hybrid system for ASC using multi-channel i-vectors and CNNs by utilizing a score fusion technique. Using our method, we participated in the ASC task of the DCASE-2016 challenge. Our hybrid approach achieved 1 st rank among 49 submissions, substantially improving the previous state of the art.
On the Potential of Simple Framewise Approaches to Piano Transcription
Dec 15, 2016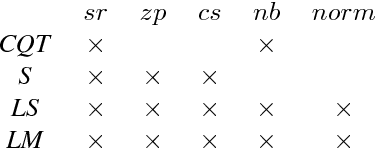
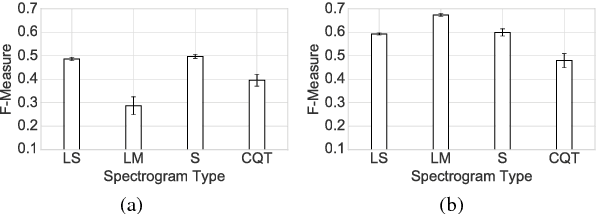
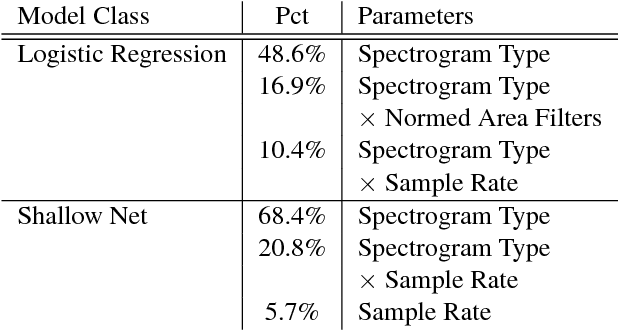
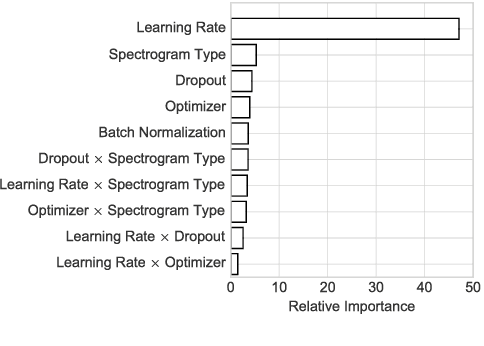
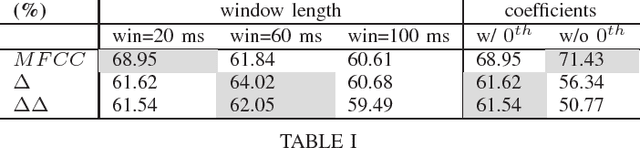
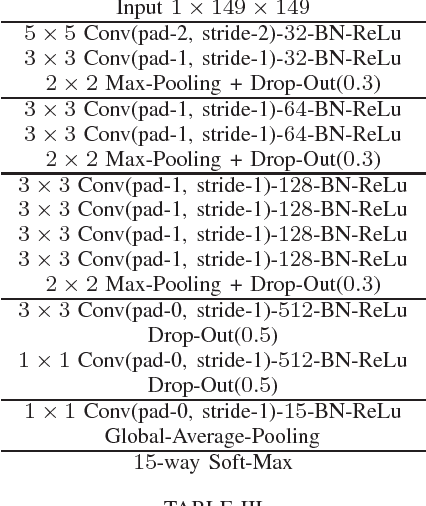
In an attempt at exploring the limitations of simple approaches to the task of piano transcription (as usually defined in MIR), we conduct an in-depth analysis of neural network-based framewise transcription. We systematically compare different popular input representations for transcription systems to determine the ones most suitable for use with neural networks. Exploiting recent advances in training techniques and new regularizers, and taking into account hyper-parameter tuning, we show that it is possible, by simple bottom-up frame-wise processing, to obtain a piano transcriber that outperforms the current published state of the art on the publicly available MAPS dataset -- without any complex post-processing steps. Thus, we propose this simple approach as a new baseline for this dataset, for future transcription research to build on and improve.