 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Dictionary Search: Integrating Linear Mixing with Deep Non-Linear Modelling for Audio Source Separation
Nov 28, 2022

This paper describes several improvements to a new method for signal decomposition that we recently formulated under the name of Differentiable Dictionary Search (DDS). The fundamental idea of DDS is to exploit a class of powerful deep invertible density estimators called normalizing flows, to model the dictionary in a linear decomposition method such as NMF, effectively creating a bijection between the space of dictionary elements and the associated probability space, allowing a differentiable search through the dictionary space, guided by the estimated densities. As the initial formulation was a proof of concept with some practical limitations, we will present several steps towards making it scalable, hoping to improve both the computational complexity of the method and its signal decomposition capabilities. As a testbed for experimental evaluation, we choose the task of frame-level piano transcription, where the signal is to be decomposed into sources whose activity is attributed to individual piano notes. To highlight the impact of improved non-linear modelling of sources, we compare variants of our method to a linear overcomplete NMF baseline. Experimental results will show that even in the absence of additional constraints, our models produce increasingly sparse and precise decompositions, according to two pertinent evaluation measures.
Probabilistic Modelling of Signal Mixtures with Differentiable Dictionaries
Nov 28, 2022We introduce a novel way to incorporate prior information into (semi-) supervised non-negative matrix factorization, which we call differentiable dictionary search. It enables general, highly flexible and principled modelling of mixtures where non-linear sources are linearly mixed. We study its behavior on an audio decomposition task, and conduct an extensive, highly controlled study of its modelling capabilities.
Learning to Read and Follow Music in Complete Score Sheet Images
Jul 21, 2020

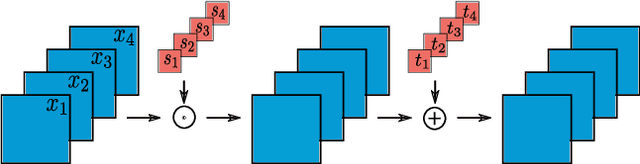
This paper addresses the task of score following in sheet music given as unprocessed images. While existing work either relies on OMR software to obtain a computer-readable score representation, or crucially relies on prepared sheet image excerpts, we propose the first system that directly performs score following in full-page, completely unprocessed sheet images. Based on incoming audio and a given image of the score, our system directly predicts the most likely position within the page that matches the audio, outperforming current state-of-the-art image-based score followers in terms of alignment precision. We also compare our method to an OMR-based approach and empirically show that it can be a viable alternative to such a system.
Audio-Conditioned U-Net for Position Estimation in Full Sheet Images
Oct 16, 2019


The goal of score following is to track a musical performance, usually in the form of audio, in a corresponding score representation. Established methods mainly rely on computer-readable scores in the form of MIDI or MusicXML and achieve robust and reliable tracking results. Recently, multimodal deep learning methods have been used to follow along musical performances in raw sheet images. Among the current limits of these systems is that they require a non trivial amount of preprocessing steps that unravel the raw sheet image into a single long system of staves. The current work is an attempt at removing this particular limitation. We propose an architecture capable of estimating matching score positions directly within entire unprocessed sheet images. We argue that this is a necessary first step towards a fully integrated score following system that does not rely on any preprocessing steps such as optical music recognition.
Learning to Transcribe by Ear
May 29, 2018

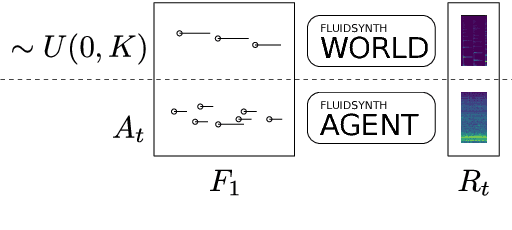
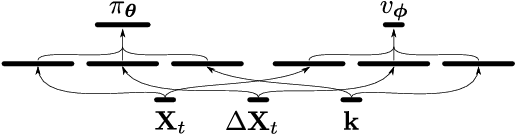
Rethinking how to model polyphonic transcription formally, we frame it as a reinforcement learning task. Such a task formulation encompasses the notion of a musical agent and an environment containing an instrument as well as the sound source to be transcribed. Within this conceptual framework, the transcription process can be described as the agent interacting with the instrument in the environment, and obtaining reward by playing along with what it hears. Choosing from a discrete set of actions - the notes to play on its instrument - the amount of reward the agent experiences depends on which notes it plays and when. This process resembles how a human musician might approach the task of transcription, and the satisfaction she achieves by closely mimicking the sound source to transcribe on her instrument. Following a discussion of the theoretical framework and the benefits of modelling the problem in this way, we focus our attention on several practical considerations and address the difficulties in training an agent to acceptable performance on a set of tasks with increasing difficulty. We demonstrate promising results in partially constrained environments.
Investigating Label Noise Sensitivity of Convolutional Neural Networks for Fine Grained Audio Signal Labelling
May 28, 2018


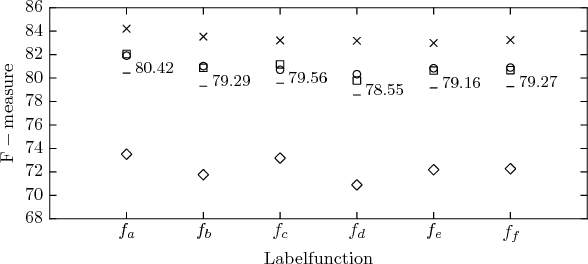
We measure the effect of small amounts of systematic and random label noise caused by slightly misaligned ground truth labels in a fine grained audio signal labeling task. The task we choose to demonstrate these effects on is also known as framewise polyphonic transcription or note quantized multi-f0 estimation, and transforms a monaural audio signal into a sequence of note indicator labels. It will be shown that even slight misalignments have clearly apparent effects, demonstrating a great sensitivity of convolutional neural networks to label noise. The implications are clear: when using convolutional neural networks for fine grained audio signal labeling tasks, great care has to be taken to ensure that the annotations have precise timing, and are free from systematic or random error as much as possible - even small misalignments will have a noticeable impact.
On the Potential of Simple Framewise Approaches to Piano Transcription
Dec 15, 2016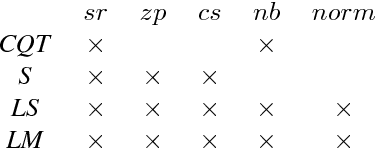
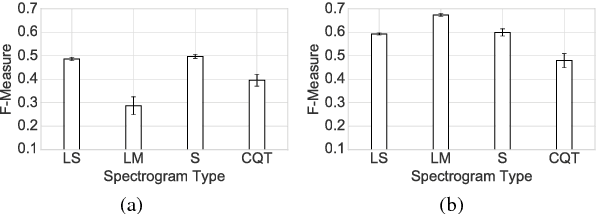
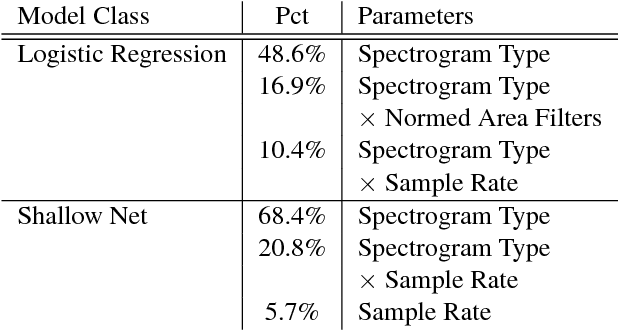
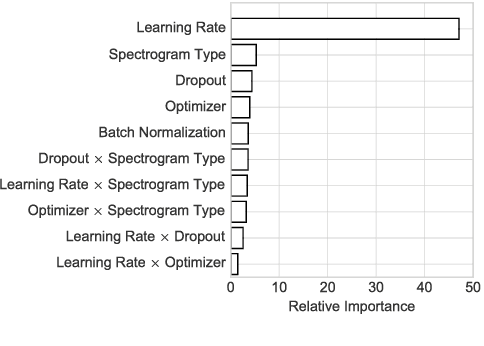
In an attempt at exploring the limitations of simple approaches to the task of piano transcription (as usually defined in MIR), we conduct an in-depth analysis of neural network-based framewise transcription. We systematically compare different popular input representations for transcription systems to determine the ones most suitable for use with neural networks. Exploiting recent advances in training techniques and new regularizers, and taking into account hyper-parameter tuning, we show that it is possible, by simple bottom-up frame-wise processing, to obtain a piano transcriber that outperforms the current published state of the art on the publicly available MAPS dataset -- without any complex post-processing steps. Thus, we propose this simple approach as a new baseline for this dataset, for future transcription research to build on and improve.
Deep Linear Discriminant Analysis
Feb 17, 2016



We introduce Deep Linear Discriminant Analysis (DeepLDA) which learns linearly separable latent representations in an end-to-end fashion. Classic LDA extracts features which preserve class separability and is used for dimensionality reduction for many classification problems. The central idea of this paper is to put LDA on top of a deep neural network. This can be seen as a non-linear extension of classic LDA. Instead of maximizing the likelihood of target labels for individual samples, we propose an objective function that pushes the network to produce feature distributions which: (a) have low variance within the same class and (b) high variance between different classes. Our objective is derived from the general LDA eigenvalue problem and still allows to train with stochastic gradient descent and back-propagation. For evaluation we test our approach on three different benchmark datasets (MNIST, CIFAR-10 and STL-10). DeepLDA produces competitive results on MNIST and CIFAR-10 and outperforms a network trained with categorical cross entropy (same architecture) on a supervised setting of STL-10.