 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound and Music Biases in Deep Music Transcription Models: A Systematic Analysis
Dec 16, 2025Automatic Music Transcription (AMT) -- the task of converting music audio into note representations -- has seen rapid progress, driven largely by deep learning systems. Due to the limited availability of richly annotated music datasets, much of the progress in AMT has been concentrated on classical piano music, and even a few very specific datasets. Whether these systems can generalize effectively to other musical contexts remains an open question. Complementing recent studies on distribution shifts in sound (e.g., recording conditions), in this work we investigate the musical dimension -- specifically, variations in genre, dynamics, and polyphony levels. To this end, we introduce the MDS corpus, comprising three distinct subsets -- (1) Genre, (2) Random, and (3) MAEtest -- to emulate different axes of distribution shift. We evaluate the performance of several state-of-the-art AMT systems on the MDS corpus using both traditional information-retrieval and musically-informed performance metrics. Our extensive evaluation isolates and exposes varying degrees of performance degradation under specific distribution shifts. In particular, we measure a note-level F1 performance drop of 20 percentage points due to sound, and 14 due to genre. Generally, we find that dynamics estimation proves more vulnerable to musical variation than onset prediction. Musically informed evaluation metrics, particularly those capturing harmonic structure, help identify potential contributing factors. Furthermore, experiments with randomly generated, non-musical sequences reveal clear limitations in system performance under extreme musical distribution shifts. Altogether, these findings offer new evidence of the persistent impact of the Corpus Bias problem in deep AMT systems.
Quantifying the Corpus Bias Problem in Automatic Music Transcription Systems
Aug 08, 2024Automatic Music Transcription (AMT) is the task of recognizing notes in audio recordings of music. The State-of-the-Art (SotA) benchmarks have been dominated by deep learning systems. Due to the scarcity of high quality data, they are usually trained and evaluated exclusively or predominantly on classical piano music. Unfortunately, that hinders our ability to understand how they generalize to other music. Previous works have revealed several aspects of memorization and overfitting in these systems. We identify two primary sources of distribution shift: the music, and the sound. Complementing recent results on the sound axis (i.e. acoustics, timbre), we investigate the musical one (i.e. note combinations, dynamics, genre). We evaluate the performance of several SotA AMT systems on two new experimental test sets which we carefully construct to emulate different levels of musical distribution shift. Our results reveal a stark performance gap, shedding further light on the Corpus Bias problem, and the extent to which it continues to trouble these systems.
Towards Musically Informed Evaluation of Piano Transcription Models
Jun 12, 2024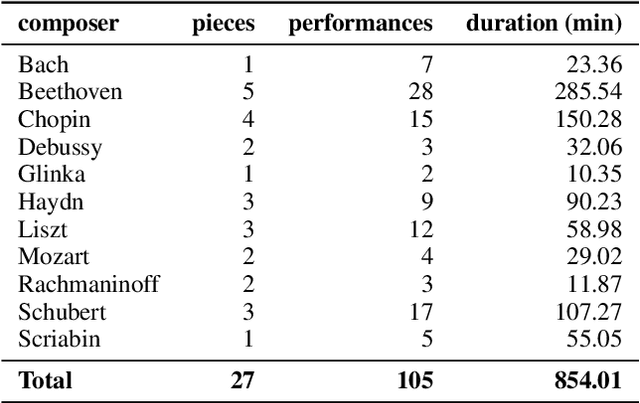
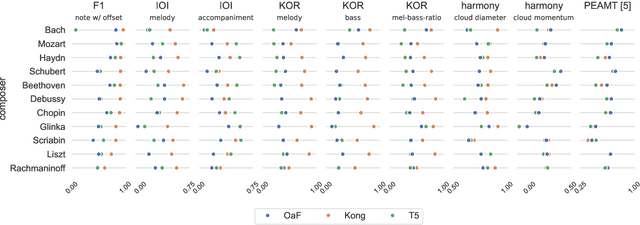
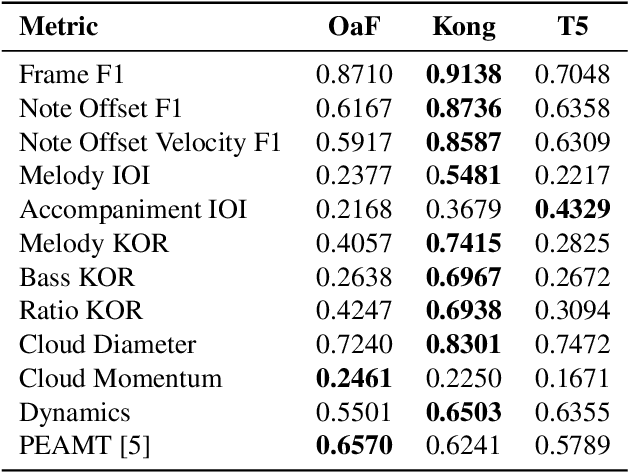
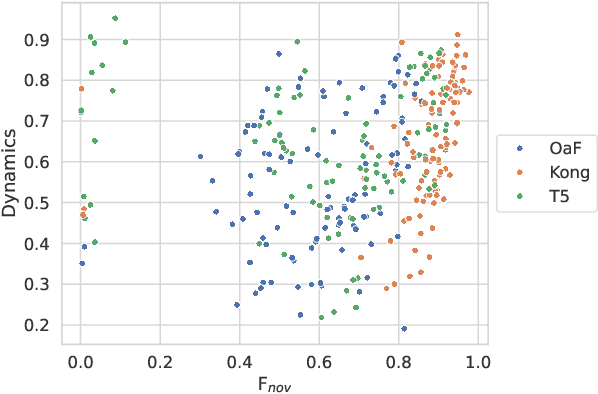
Automatic piano transcription models are typically evaluated using simple frame- or note-wise information retrieval (IR) metrics. Such benchmark metrics do not provide insights into the transcription quality of specific musical aspects such as articulation, dynamics, or rhythmic precision of the output, which are essential in the context of expressive performance analysis. Furthermore, in recent years, MAESTRO has become the de-facto training and evaluation dataset for such models. However, inference performance has been observed to deteriorate substantially when applied on out-of-distribution data, thereby questioning the suitability and reliability of transcribed outputs from such models for specific MIR tasks. In this work, we investigate the performance of three state-of-the-art piano transcription models in two experiments. In the first one, we propose a variety of musically informed evaluation metrics which, in contrast to the IR metrics, offer more detailed insight into the musical quality of the transcriptions. In the second experiment, we compare inference performance on real-world and perturbed audio recordings, and highlight musical dimensions which our metrics can help explain. Our experimental results highlight the weaknesses of existing piano transcription metrics and contribute to a more musically sound error analysis of transcription outputs.
Differentiable Dictionary Search: Integrating Linear Mixing with Deep Non-Linear Modelling for Audio Source Separation
Nov 28, 2022

This paper describes several improvements to a new method for signal decomposition that we recently formulated under the name of Differentiable Dictionary Search (DDS). The fundamental idea of DDS is to exploit a class of powerful deep invertible density estimators called normalizing flows, to model the dictionary in a linear decomposition method such as NMF, effectively creating a bijection between the space of dictionary elements and the associated probability space, allowing a differentiable search through the dictionary space, guided by the estimated densities. As the initial formulation was a proof of concept with some practical limitations, we will present several steps towards making it scalable, hoping to improve both the computational complexity of the method and its signal decomposition capabilities. As a testbed for experimental evaluation, we choose the task of frame-level piano transcription, where the signal is to be decomposed into sources whose activity is attributed to individual piano notes. To highlight the impact of improved non-linear modelling of sources, we compare variants of our method to a linear overcomplete NMF baseline. Experimental results will show that even in the absence of additional constraints, our models produce increasingly sparse and precise decompositions, according to two pertinent evaluation measures.
Probabilistic Modelling of Signal Mixtures with Differentiable Dictionaries
Nov 28, 2022We introduce a novel way to incorporate prior information into (semi-) supervised non-negative matrix factorization, which we call differentiable dictionary search. It enables general, highly flexible and principled modelling of mixtures where non-linear sources are linearly mixed. We study its behavior on an audio decomposition task, and conduct an extensive, highly controlled study of its modelling capabilities.