 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound and Music Biases in Deep Music Transcription Models: A Systematic Analysis
Dec 16, 2025Automatic Music Transcription (AMT) -- the task of converting music audio into note representations -- has seen rapid progress, driven largely by deep learning systems. Due to the limited availability of richly annotated music datasets, much of the progress in AMT has been concentrated on classical piano music, and even a few very specific datasets. Whether these systems can generalize effectively to other musical contexts remains an open question. Complementing recent studies on distribution shifts in sound (e.g., recording conditions), in this work we investigate the musical dimension -- specifically, variations in genre, dynamics, and polyphony levels. To this end, we introduce the MDS corpus, comprising three distinct subsets -- (1) Genre, (2) Random, and (3) MAEtest -- to emulate different axes of distribution shift. We evaluate the performance of several state-of-the-art AMT systems on the MDS corpus using both traditional information-retrieval and musically-informed performance metrics. Our extensive evaluation isolates and exposes varying degrees of performance degradation under specific distribution shifts. In particular, we measure a note-level F1 performance drop of 20 percentage points due to sound, and 14 due to genre. Generally, we find that dynamics estimation proves more vulnerable to musical variation than onset prediction. Musically informed evaluation metrics, particularly those capturing harmonic structure, help identify potential contributing factors. Furthermore, experiments with randomly generated, non-musical sequences reveal clear limitations in system performance under extreme musical distribution shifts. Altogether, these findings offer new evidence of the persistent impact of the Corpus Bias problem in deep AMT systems.
Exploring System Adaptations For Minimum Latency Real-Time Piano Transcription
Sep 09, 2025Advances in neural network design and the availability of large-scale labeled datasets have driven major improvements in piano transcription. Existing approaches target either offline applications, with no restrictions on computational demands, or online transcription, with delays of 128-320 ms. However, most real-time musical applications require latencies below 30 ms. In this work, we investigate whether and how the current state-of-the-art online transcription model can be adapted for real-time piano transcription. Specifically, we eliminate all non-causal processing, and reduce computational load through shared computations across core model components and variations in model size. Additionally, we explore different pre- and postprocessing strategies, and related label encoding schemes, and discuss their suitability for real-time transcription. Evaluating the adaptions on the MAESTRO dataset, we find a drop in transcription accuracy due to strictly causal processing as well as a tradeoff between the preprocessing latency and prediction accuracy. We release our system as a baseline to support researchers in designing models towards minimum latency real-time transcription.
Pairing Real-Time Piano Transcription with Symbol-level Tracking for Precise and Robust Score Following
May 08, 2025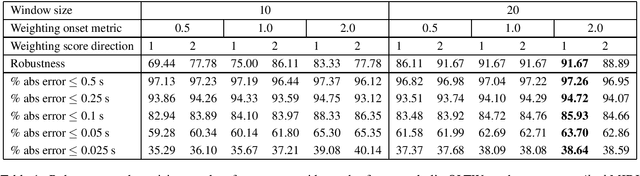
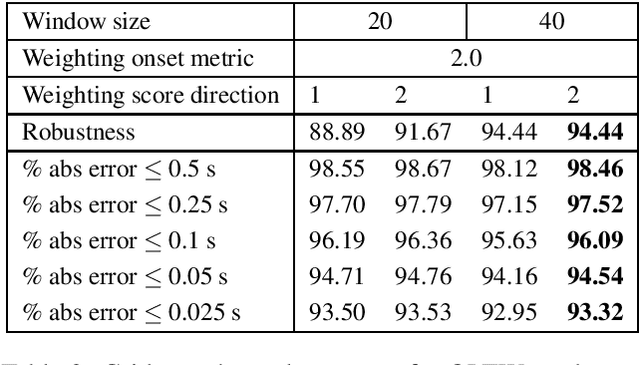
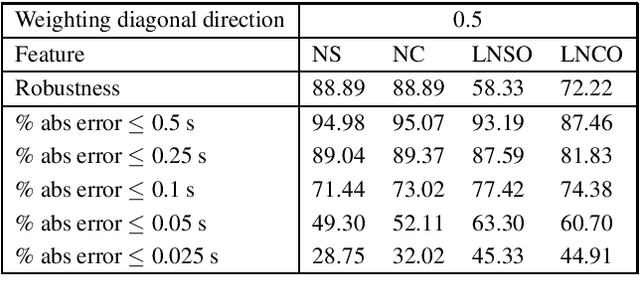
Real-time music tracking systems follow a musical performance and at any time report the current position in a corresponding score. Most existing methods approach this problem exclusively in the audio domain, typically using online time warping (OLTW) techniques on incoming audio and an audio representation of the score. Audio OLTW techniques have seen incremental improvements both in features and model heuristics which reached a performance plateau in the past ten years. We argue that converting and representing the performance in the symbolic domain -- thereby transforming music tracking into a symbolic task -- can be a more effective approach, even when the domain transformation is imperfect. Our music tracking system combines two real-time components: one handling audio-to-note transcription and the other a novel symbol-level tracker between transcribed input and score. We compare the performance of this mixed audio-symbolic approach with its equivalent audio-only counterpart, and demonstrate that our method outperforms the latter in terms of both precision, i.e., absolute tracking error, and robustness, i.e., tracking success.
How to Infer Repeat Structures in MIDI Performances
May 08, 2025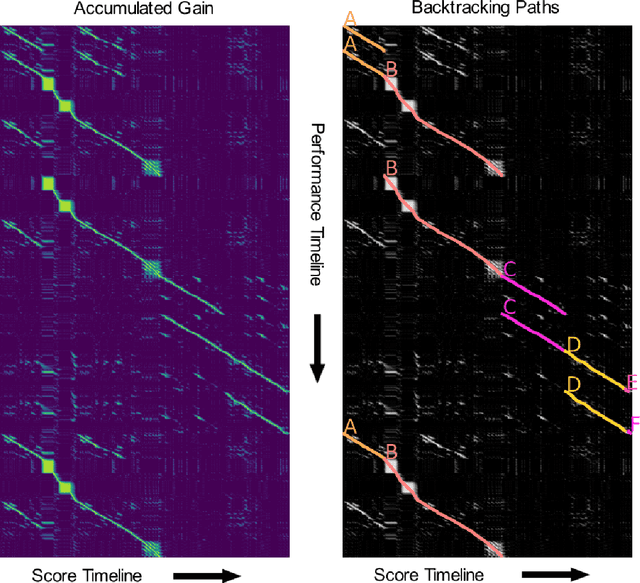

MIDI performances are generally expedient in performance research and music information retrieval, and even more so if they can be connected to a score. This connection is usually established by means of alignment, linking either notes or time points between the score and the performance. The first obstacle when trying to establish such an alignment is that a performance realizes one (out of many) structural versions of the score that can plausibly result from instructions such as repeats, variations, and navigation markers like 'dal segno/da capo al coda'. A score needs to be unfolded, that is, its repeats and navigation markers need to be explicitly written out to create a single timeline without jumps matching the performance, before alignment algorithms can be applied. In the curation of large performance corpora this process is carried out manually, as no tools are available to infer the repeat structure of the performance. To ease this process, we develop a method to automatically infer the repeat structure of a MIDI performance, given a symbolically encoded score including repeat and navigation markers. The intuition guiding our design is: 1) local alignment of every contiguous section of the score with a section of a performance containing the same material should receive high alignment gain, whereas local alignment with any other performance section should accrue a low or zero gain. And 2) stitching local alignments together according to a valid structural version of the score should result in an approximate full alignment and correspondingly high global accumulated gain if the structural version corresponds to the performance, and low gain for all other, ill-fitting structural versions.
Quantifying the Corpus Bias Problem in Automatic Music Transcription Systems
Aug 08, 2024Automatic Music Transcription (AMT) is the task of recognizing notes in audio recordings of music. The State-of-the-Art (SotA) benchmarks have been dominated by deep learning systems. Due to the scarcity of high quality data, they are usually trained and evaluated exclusively or predominantly on classical piano music. Unfortunately, that hinders our ability to understand how they generalize to other music. Previous works have revealed several aspects of memorization and overfitting in these systems. We identify two primary sources of distribution shift: the music, and the sound. Complementing recent results on the sound axis (i.e. acoustics, timbre), we investigate the musical one (i.e. note combinations, dynamics, genre). We evaluate the performance of several SotA AMT systems on two new experimental test sets which we carefully construct to emulate different levels of musical distribution shift. Our results reveal a stark performance gap, shedding further light on the Corpus Bias problem, and the extent to which it continues to trouble these systems.
Towards Musically Informed Evaluation of Piano Transcription Models
Jun 12, 2024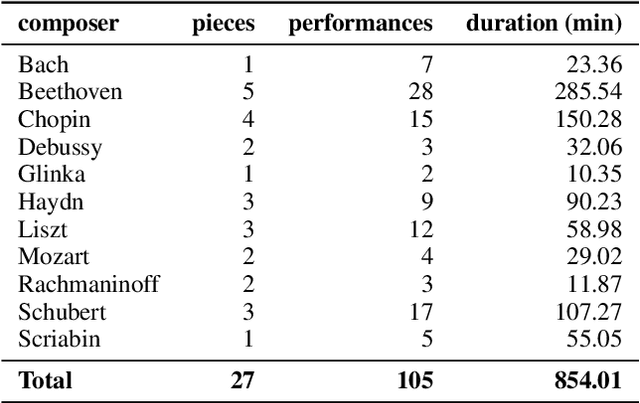
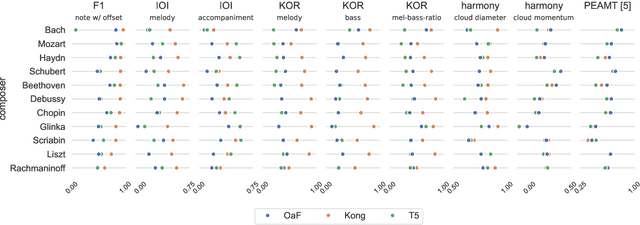
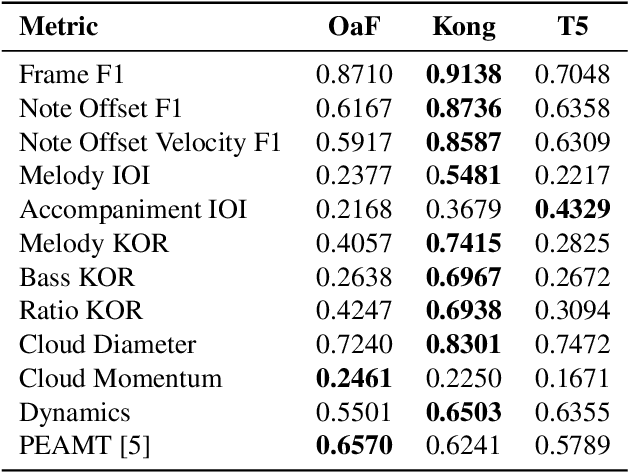
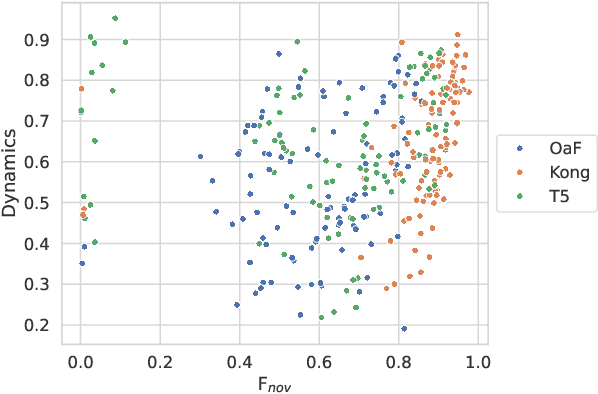
Automatic piano transcription models are typically evaluated using simple frame- or note-wise information retrieval (IR) metrics. Such benchmark metrics do not provide insights into the transcription quality of specific musical aspects such as articulation, dynamics, or rhythmic precision of the output, which are essential in the context of expressive performance analysis. Furthermore, in recent years, MAESTRO has become the de-facto training and evaluation dataset for such models. However, inference performance has been observed to deteriorate substantially when applied on out-of-distribution data, thereby questioning the suitability and reliability of transcribed outputs from such models for specific MIR tasks. In this work, we investigate the performance of three state-of-the-art piano transcription models in two experiments. In the first one, we propose a variety of musically informed evaluation metrics which, in contrast to the IR metrics, offer more detailed insight into the musical quality of the transcriptions. In the second experiment, we compare inference performance on real-world and perturbed audio recordings, and highlight musical dimensions which our metrics can help explain. Our experimental results highlight the weaknesses of existing piano transcription metrics and contribute to a more musically sound error analysis of transcription outputs.
The Batik-plays-Mozart Corpus: Linking Performance to Score to Musicological Annotations
Sep 06, 2023We present the Batik-plays-Mozart Corpus, a piano performance dataset combining professional Mozart piano sonata performances with expert-labelled scores at a note-precise level. The performances originate from a recording by Viennese pianist Roland Batik on a computer-monitored B\"osendorfer grand piano, and are available both as MIDI files and audio recordings. They have been precisely aligned, note by note, with a current standard edition of the corresponding scores (the New Mozart Edition) in such a way that they can further be connected to the musicological annotations (harmony, cadences, phrases) on these scores that were recently published by Hentschel et al. (2021). The result is a high-quality, high-precision corpus mapping scores and musical structure annotations to precise note-level professional performance information. As the first of its kind, it can serve as a valuable resource for studying various facets of expressive performance and their relationship with structural aspects. In the paper, we outline the curation process of the alignment and conduct two exploratory experiments to demonstrate its usefulness in analyzing expressive performance.
The ACCompanion: Combining Reactivity, Robustness, and Musical Expressivity in an Automatic Piano Accompanist
Apr 24, 2023This paper introduces the ACCompanion, an expressive accompaniment system. Similarly to a musician who accompanies a soloist playing a given musical piece, our system can produce a human-like rendition of the accompaniment part that follows the soloist's choices in terms of tempo, dynamics, and articulation. The ACCompanion works in the symbolic domain, i.e., it needs a musical instrument capable of producing and playing MIDI data, with explicitly encoded onset, offset, and pitch for each played note. We describe the components that go into such a system, from real-time score following and prediction to expressive performance generation and online adaptation to the expressive choices of the human player. Based on our experience with repeated live demonstrations in front of various audiences, we offer an analysis of the challenges of combining these components into a system that is highly reactive and precise, while still a reliable musical partner, robust to possible performance errors and responsive to expressive variations.