 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Parallel Audio Recordings to Enforce Device Invariance in CNN-based Acoustic Scene Classification
Sep 04, 2019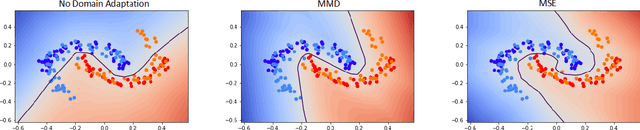
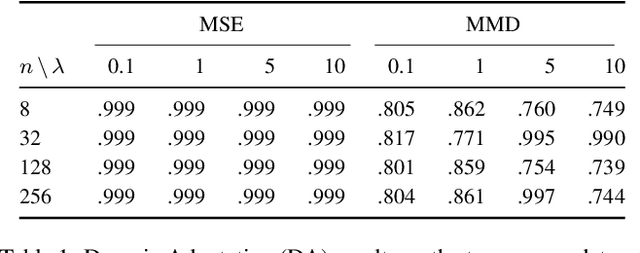

Distribution mismatches between the data seen at training and at application time remain a major challenge in all application areas of machine learning. We study this problem in the context of machine listening (Task 1b of the DCASE 2019 Challenge). We propose a novel approach to learn domain-invariant classifiers in an end-to-end fashion by enforcing equal hidden layer representations for domain-parallel samples, i.e. time-aligned recordings from different recording devices. No classification labels are needed for our domain adaptation (DA) method, which makes the data collection process cheaper.
Learning Complex Basis Functions for Invariant Representations of Audio
Jul 13, 2019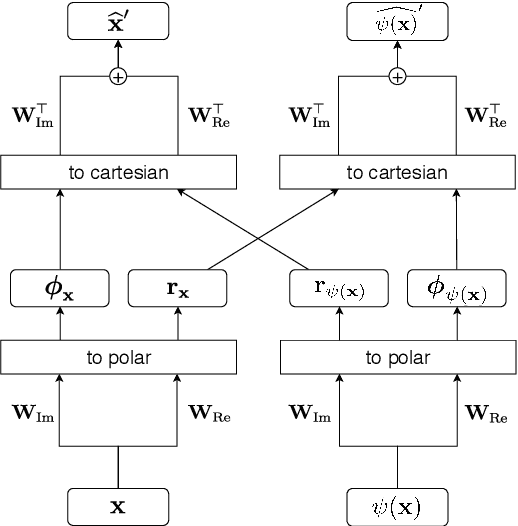


Learning features from data has shown to be more successful than using hand-crafted features for many machine learning tasks. In music information retrieval (MIR), features learned from windowed spectrograms are highly variant to transformations like transposition or time-shift. Such variances are undesirable when they are irrelevant for the respective MIR task. We propose an architecture called Complex Autoencoder (CAE) which learns features invariant to orthogonal transformations. Mapping signals onto complex basis functions learned by the CAE results in a transformation-invariant "magnitude space" and a transformation-variant "phase space". The phase space is useful to infer transformations between data pairs. When exploiting the invariance-property of the magnitude space, we achieve state-of-the-art results in audio-to-score alignment and repeated section discovery for audio. A PyTorch implementation of the CAE, including the repeated section discovery method, is available online.
Learning Soft-Attention Models for Tempo-invariant Audio-Sheet Music Retrieval
Jun 26, 2019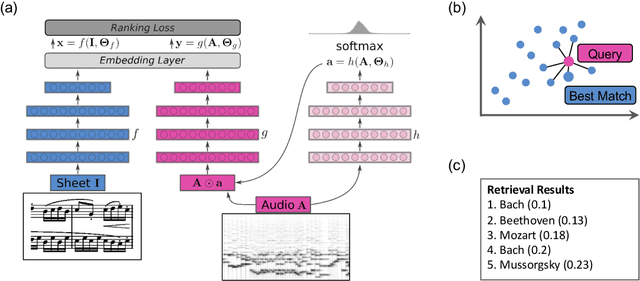
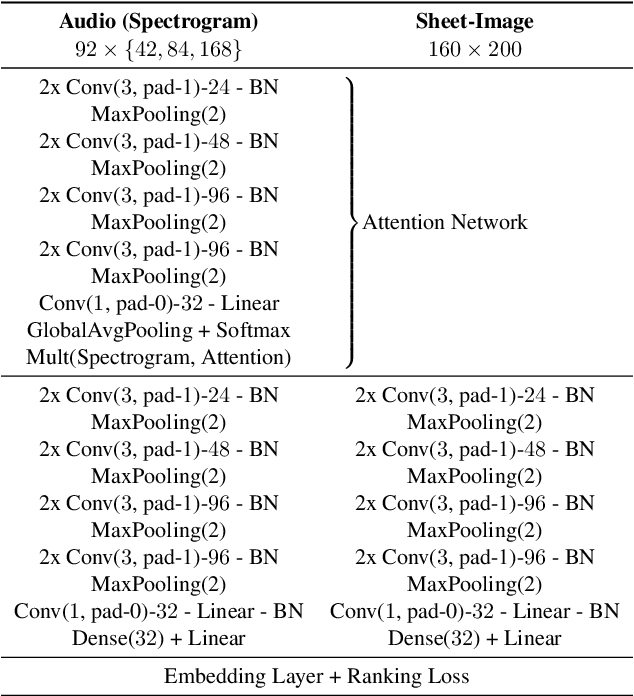
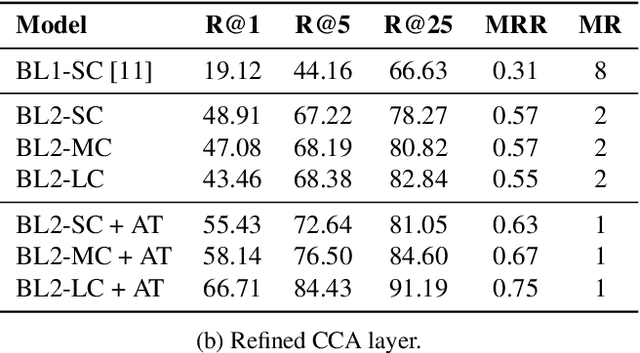

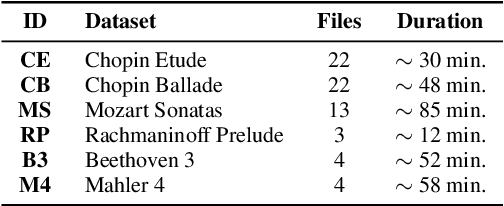
Connecting large libraries of digitized audio recordings to their corresponding sheet music images has long been a motivation for researchers to develop new cross-modal retrieval systems. In recent years, retrieval systems based on embedding space learning with deep neural networks got a step closer to fulfilling this vision. However, global and local tempo deviations in the music recordings still require careful tuning of the amount of temporal context given to the system. In this paper, we address this problem by introducing an additional soft-attention mechanism on the audio input. Quantitative and qualitative results on synthesized piano data indicate that this attention increases the robustness of the retrieval system by focusing on different parts of the input representation based on the tempo of the audio. Encouraged by these results, we argue for the potential of attention models as a very general tool for many MIR tasks.
On the Potential of Simple Framewise Approaches to Piano Transcription
Dec 15, 2016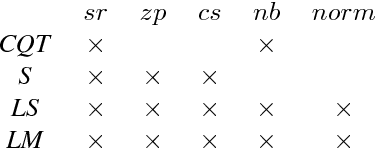
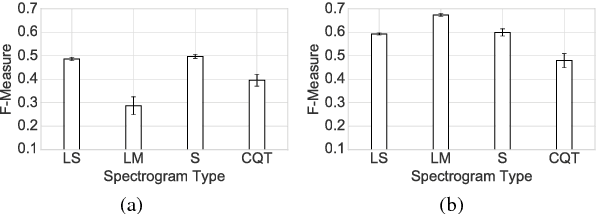
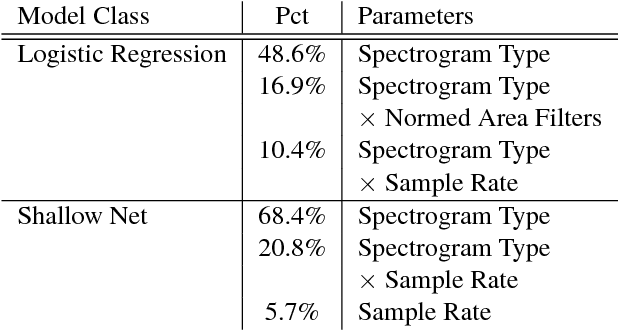
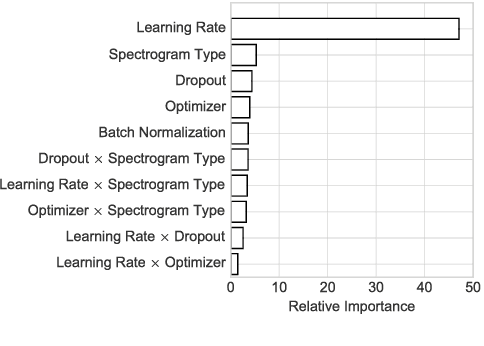
In an attempt at exploring the limitations of simple approaches to the task of piano transcription (as usually defined in MIR), we conduct an in-depth analysis of neural network-based framewise transcription. We systematically compare different popular input representations for transcription systems to determine the ones most suitable for use with neural networks. Exploiting recent advances in training techniques and new regularizers, and taking into account hyper-parameter tuning, we show that it is possible, by simple bottom-up frame-wise processing, to obtain a piano transcriber that outperforms the current published state of the art on the publicly available MAPS dataset -- without any complex post-processing steps. Thus, we propose this simple approach as a new baseline for this dataset, for future transcription research to build on and improve.
Towards End-to-End Audio-Sheet-Music Retrieval
Dec 15, 2016

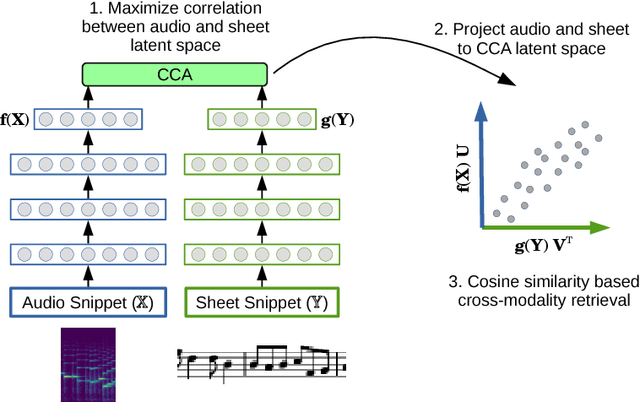
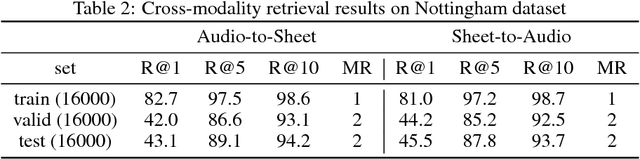
This paper demonstrates the feasibility of learning to retrieve short snippets of sheet music (images) when given a short query excerpt of music (audio) -- and vice versa --, without any symbolic representation of music or scores. This would be highly useful in many content-based musical retrieval scenarios. Our approach is based on Deep Canonical Correlation Analysis (DCCA) and learns correlated latent spaces allowing for cross-modality retrieval in both directions. Initial experiments with relatively simple monophonic music show promising results.
Towards Score Following in Sheet Music Images
Dec 15, 2016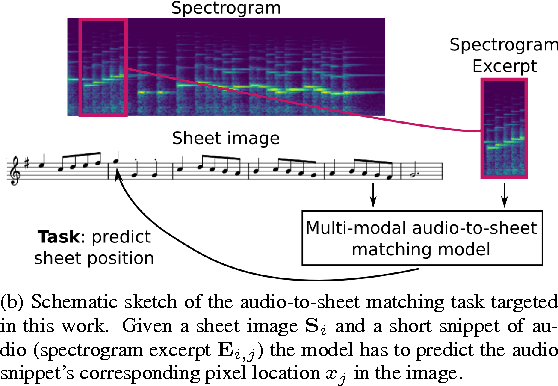

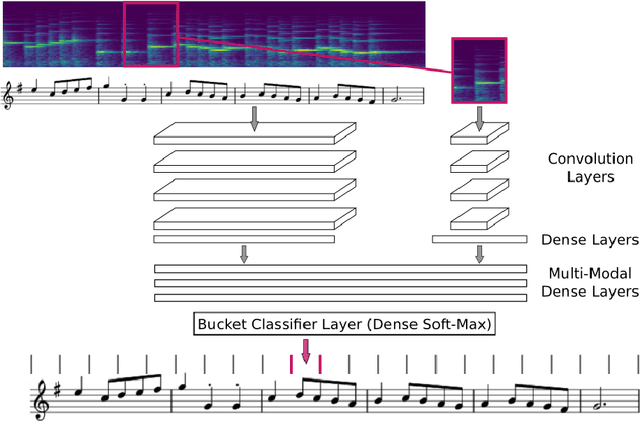
This paper addresses the matching of short music audio snippets to the corresponding pixel location in images of sheet music. A system is presented that simultaneously learns to read notes, listens to music and matches the currently played music to its corresponding notes in the sheet. It consists of an end-to-end multi-modal convolutional neural network that takes as input images of sheet music and spectrograms of the respective audio snippets. It learns to predict, for a given unseen audio snippet (covering approximately one bar of music), the corresponding position in the respective score line. Our results suggest that with the use of (deep) neural networks -- which have proven to be powerful image processing models -- working with sheet music becomes feasible and a promising future research direction.