 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulticlass ROC
Apr 19, 2024

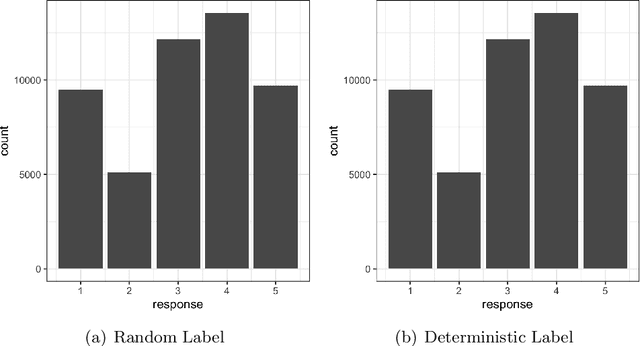
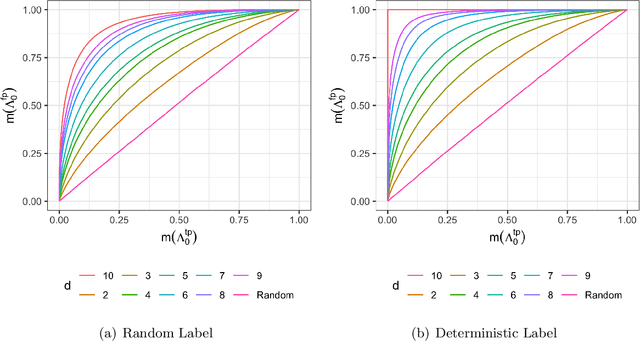
Model evaluation is of crucial importance in modern statistics application. The construction of ROC and calculation of AUC have been widely used for binary classification evaluation. Recent research generalizing the ROC/AUC analysis to multi-class classification has problems in at least one of the four areas: 1. failure to provide sensible plots 2. being sensitive to imbalanced data 3. unable to specify mis-classification cost and 4. unable to provide evaluation uncertainty quantification. Borrowing from a binomial matrix factorization model, we provide an evaluation metric summarizing the pair-wise multi-class True Positive Rate (TPR) and False Positive Rate (FPR) with one-dimensional vector representation. Visualization on the representation vector measures the relative speed of increment between TPR and FPR across all the classes pairs, which in turns provides a ROC plot for the multi-class counterpart. An integration over those factorized vector provides a binary AUC-equivalent summary on the classifier performance. Mis-clasification weights specification and bootstrapped confidence interval are also enabled to accommodate a variety of of evaluation criteria. To support our findings, we conducted extensive simulation studies and compared our method to the pair-wise averaged AUC statistics on benchmark datasets.
Self-Supervised Contrastive Learning for Robust Audio-Sheet Music Retrieval Systems
Sep 21, 2023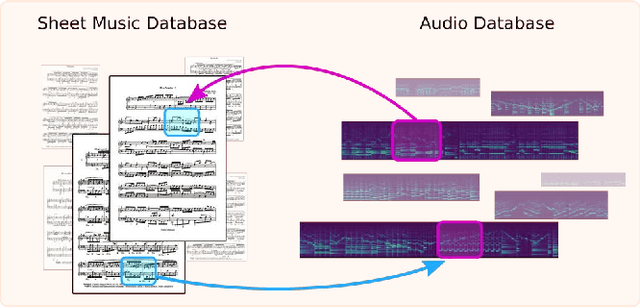
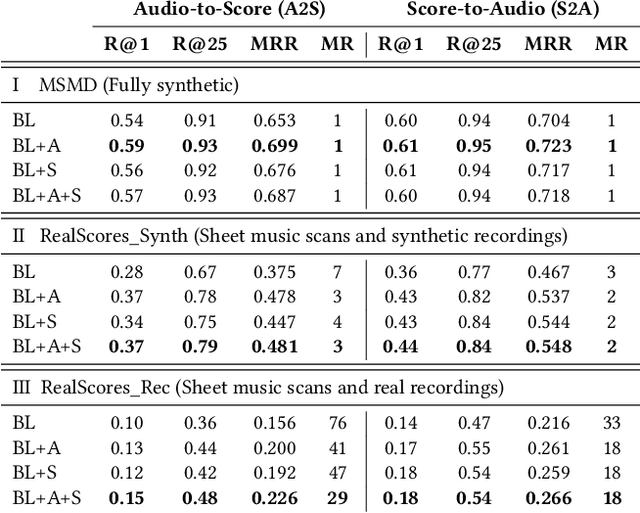
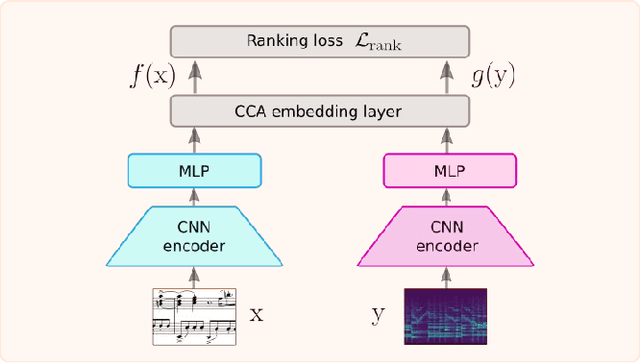
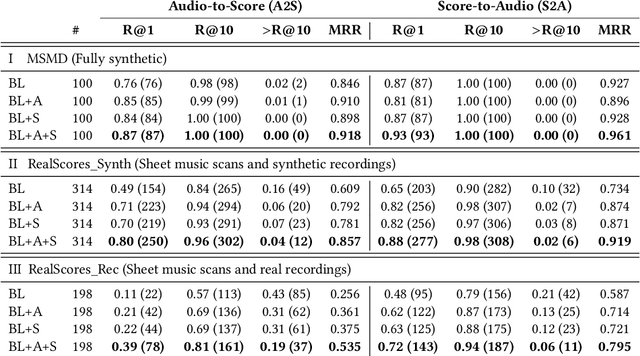
Linking sheet music images to audio recordings remains a key problem for the development of efficient cross-modal music retrieval systems. One of the fundamental approaches toward this task is to learn a cross-modal embedding space via deep neural networks that is able to connect short snippets of audio and sheet music. However, the scarcity of annotated data from real musical content affects the capability of such methods to generalize to real retrieval scenarios. In this work, we investigate whether we can mitigate this limitation with self-supervised contrastive learning, by exposing a network to a large amount of real music data as a pre-training step, by contrasting randomly augmented views of snippets of both modalities, namely audio and sheet images. Through a number of experiments on synthetic and real piano data, we show that pre-trained models are able to retrieve snippets with better precision in all scenarios and pre-training configurations. Encouraged by these results, we employ the snippet embeddings in the higher-level task of cross-modal piece identification and conduct more experiments on several retrieval configurations. In this task, we observe that the retrieval quality improves from 30% up to 100% when real music data is present. We then conclude by arguing for the potential of self-supervised contrastive learning for alleviating the annotated data scarcity in multi-modal music retrieval models.
Towards Robust and Truly Large-Scale Audio-Sheet Music Retrieval
Sep 21, 2023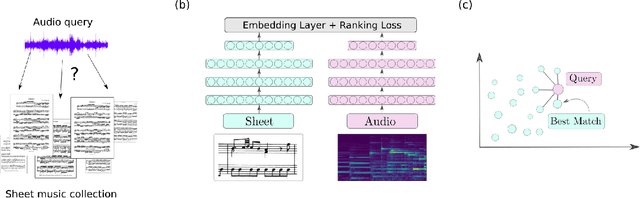

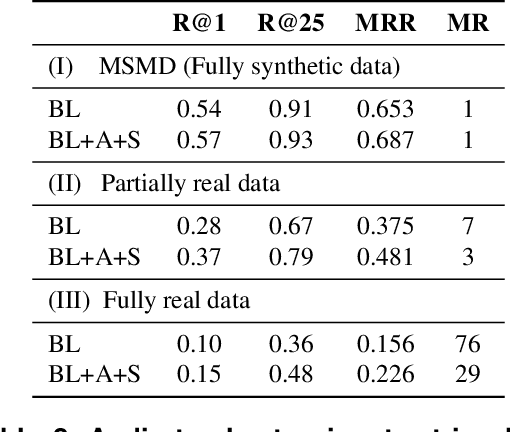
A range of applications of multi-modal music information retrieval is centred around the problem of connecting large collections of sheet music (images) to corresponding audio recordings, that is, identifying pairs of audio and score excerpts that refer to the same musical content. One of the typical and most recent approaches to this task employs cross-modal deep learning architectures to learn joint embedding spaces that link the two distinct modalities - audio and sheet music images. While there has been steady improvement on this front over the past years, a number of open problems still prevent large-scale employment of this methodology. In this article we attempt to provide an insightful examination of the current developments on audio-sheet music retrieval via deep learning methods. We first identify a set of main challenges on the road towards robust and large-scale cross-modal music retrieval in real scenarios. We then highlight the steps we have taken so far to address some of these challenges, documenting step-by-step improvement along several dimensions. We conclude by analysing the remaining challenges and present ideas for solving these, in order to pave the way to a unified and robust methodology for cross-modal music retrieval.
Passage Summarization with Recurrent Models for Audio-Sheet Music Retrieval
Sep 21, 2023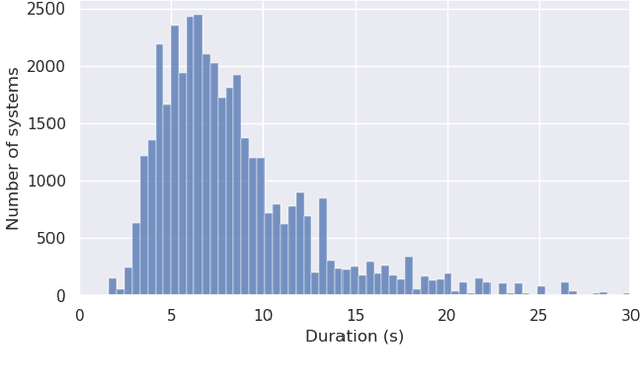
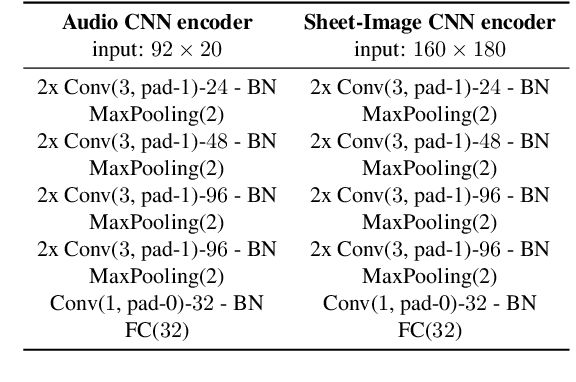
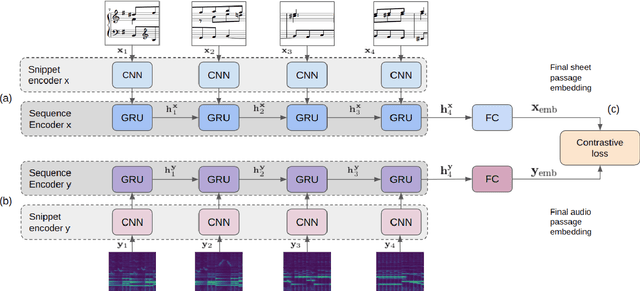
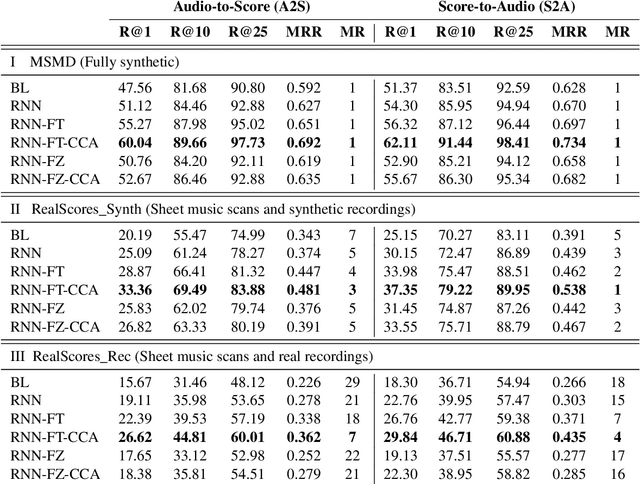
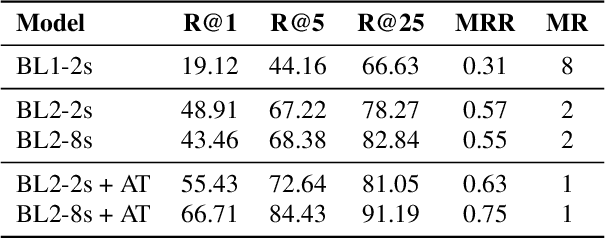
Many applications of cross-modal music retrieval are related to connecting sheet music images to audio recordings. A typical and recent approach to this is to learn, via deep neural networks, a joint embedding space that correlates short fixed-size snippets of audio and sheet music by means of an appropriate similarity structure. However, two challenges that arise out of this strategy are the requirement of strongly aligned data to train the networks, and the inherent discrepancies of musical content between audio and sheet music snippets caused by local and global tempo differences. In this paper, we address these two shortcomings by designing a cross-modal recurrent network that learns joint embeddings that can summarize longer passages of corresponding audio and sheet music. The benefits of our method are that it only requires weakly aligned audio-sheet music pairs, as well as that the recurrent network handles the non-linearities caused by tempo variations between audio and sheet music. We conduct a number of experiments on synthetic and real piano data and scores, showing that our proposed recurrent method leads to more accurate retrieval in all possible configurations.
Soft-SVM Regression For Binary Classification
May 24, 2022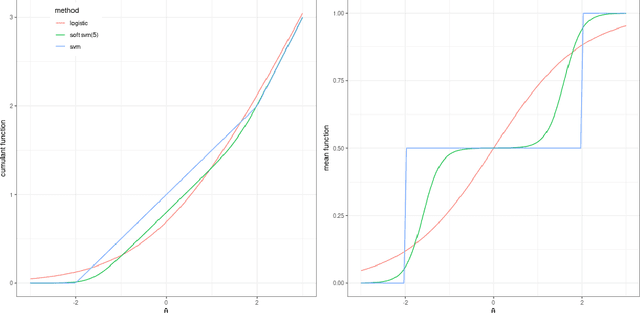
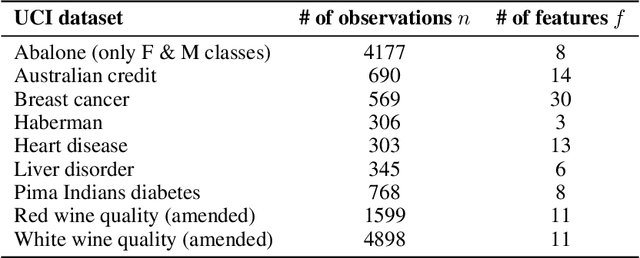
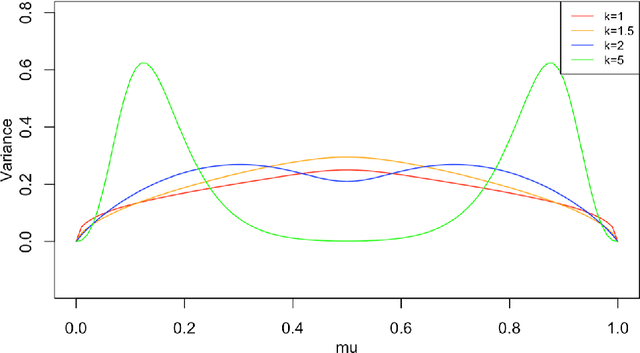
The binomial deviance and the SVM hinge loss functions are two of the most widely used loss functions in machine learning. While there are many similarities between them, they also have their own strengths when dealing with different types of data. In this work, we introduce a new exponential family based on a convex relaxation of the hinge loss function using softness and class-separation parameters. This new family, denoted Soft-SVM, allows us to prescribe a generalized linear model that effectively bridges between logistic regression and SVM classification. This new model is interpretable and avoids data separability issues, attaining good fitting and predictive performance by automatically adjusting for data label separability via the softness parameter. These results are confirmed empirically through simulations and case studies as we compare regularized logistic, SVM, and Soft-SVM regressions and conclude that the proposed model performs well in terms of both classification and prediction errors.
Deviance Matrix Factorization
Oct 12, 2021
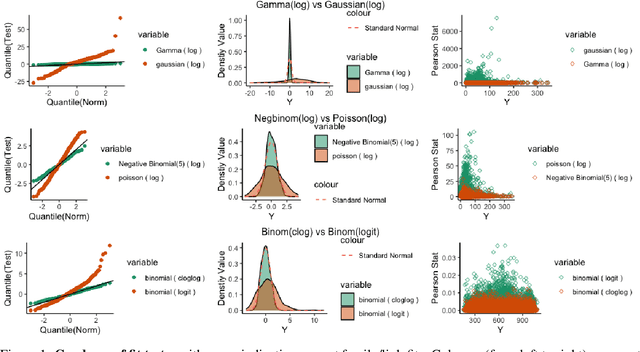
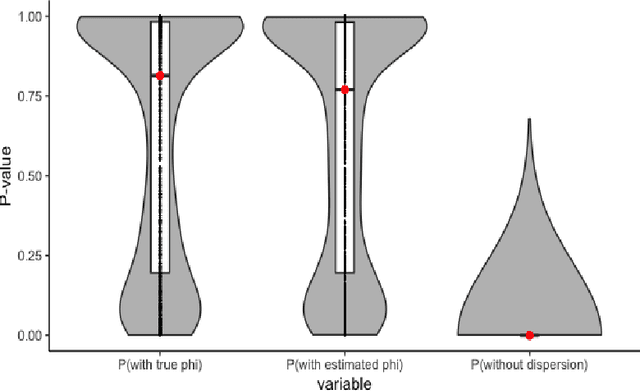

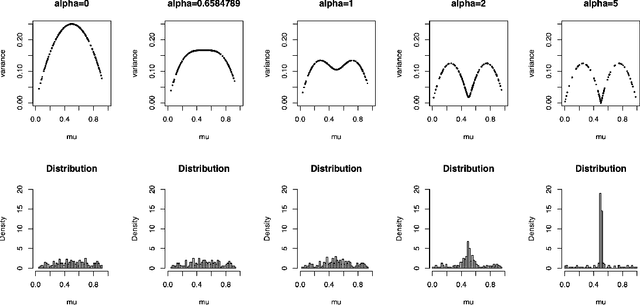
We investigate a general matrix factorization for deviance-based losses, extending the ubiquitous singular value decomposition beyond squared error loss. While similar approaches have been explored before, here we propose an efficient algorithm that is flexible enough to allow for structural zeros and entry weights. Moreover, we provide theoretical support for these decompositions by (i) showing strong consistency under a generalized linear model setup, (ii) checking the adequacy of a chosen exponential family via a generalized Hosmer-Lemeshow test, and (iii) determining the rank of the decomposition via a maximum eigenvalue gap method. To further support our findings, we conduct simulation studies to assess robustness to decomposition assumptions and extensive case studies using benchmark datasets from image face recognition, natural language processing, network analysis, and biomedical studies. Our theoretical and empirical results indicate that the proposed decomposition is more flexible, general, and can provide improved performance when compared to traditional methods.
Exploiting Temporal Dependencies for Cross-Modal Music Piece Identification
May 26, 2021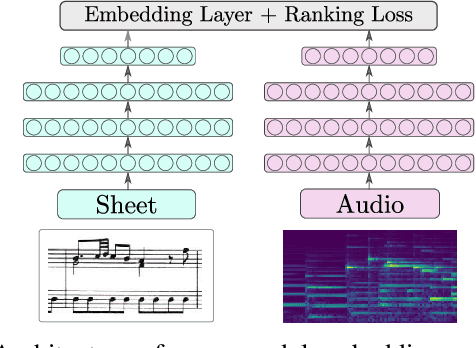
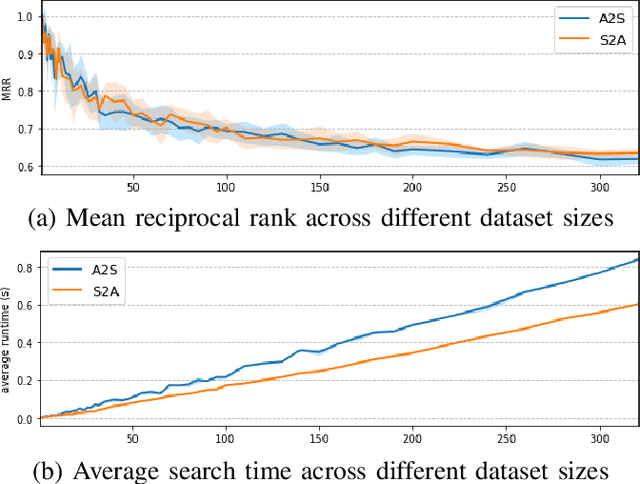
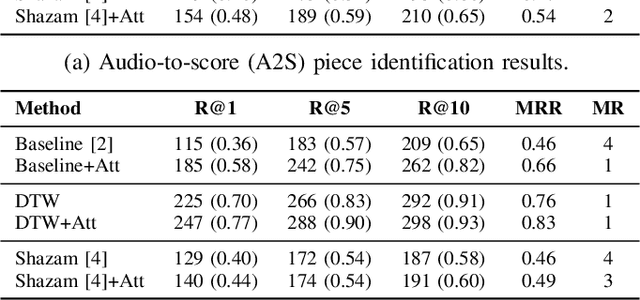
This paper addresses the problem of cross-modal musical piece identification and retrieval: finding the appropriate recording(s) from a database given a sheet music query, and vice versa, working directly with audio and scanned sheet music images. The fundamental approach to this is to learn a cross-modal embedding space with a suitable similarity structure for audio and sheet image snippets, using a deep neural network, and identifying candidate pieces by cross-modal near neighbour search in this space. However, this method is oblivious of temporal aspects of music. In this paper, we introduce two strategies that address this shortcoming. First, we present a strategy that aligns sequences of embeddings learned from sheet music scans and audio snippets. A series of experiments on whole piece and fragment-level retrieval on 24 hours worth of classical piano recordings demonstrates significant improvement. Second, we show that the retrieval can be further improved by introducing an attention mechanism to the embedding learning model that reduces the effects of tempo variations in music. To conclude, we assess the scalability of our method and discuss potential measures to make it suitable for truly large-scale applications.
* 5 pages, 3 figures
Learning Soft-Attention Models for Tempo-invariant Audio-Sheet Music Retrieval
Jun 26, 2019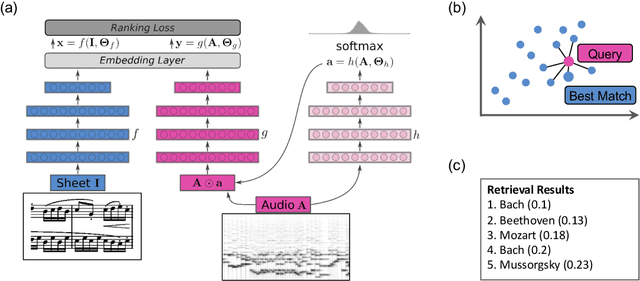
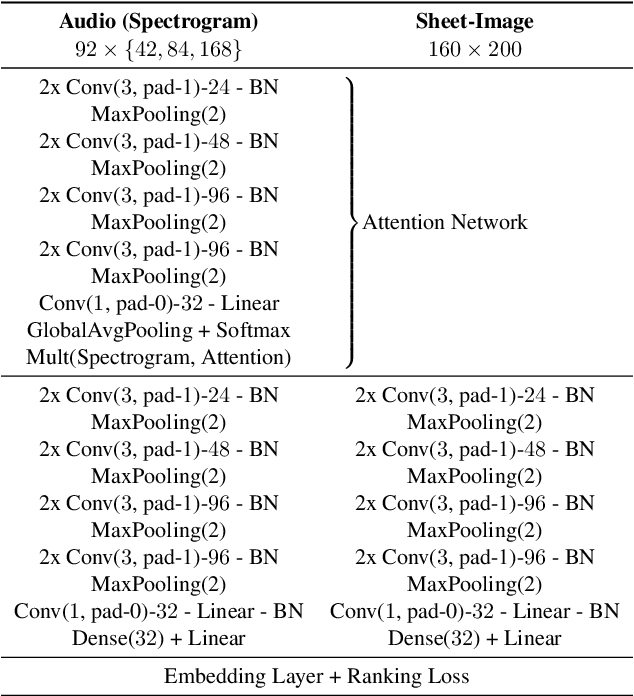
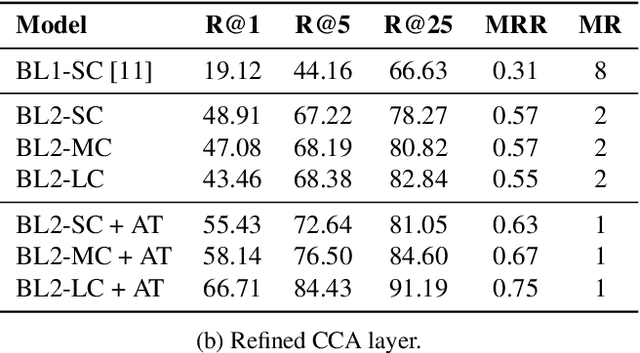

Connecting large libraries of digitized audio recordings to their corresponding sheet music images has long been a motivation for researchers to develop new cross-modal retrieval systems. In recent years, retrieval systems based on embedding space learning with deep neural networks got a step closer to fulfilling this vision. However, global and local tempo deviations in the music recordings still require careful tuning of the amount of temporal context given to the system. In this paper, we address this problem by introducing an additional soft-attention mechanism on the audio input. Quantitative and qualitative results on synthesized piano data indicate that this attention increases the robustness of the retrieval system by focusing on different parts of the input representation based on the tempo of the audio. Encouraged by these results, we argue for the potential of attention models as a very general tool for many MIR tasks.