 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoisesdb: A dataset for source separation beyond 4-stems
Jul 29, 2023In this paper, we introduce the MoisesDB dataset for musical source separation. It consists of 240 tracks from 45 artists, covering twelve musical genres. For each song, we provide its individual audio sources, organized in a two-level hierarchical taxonomy of stems. This will facilitate building and evaluating fine-grained source separation systems that go beyond the limitation of using four stems (drums, bass, other, and vocals) due to lack of data. To facilitate the adoption of this dataset, we publish an easy-to-use Python library to download, process and use MoisesDB. Alongside a thorough documentation and analysis of the dataset contents, this work provides baseline results for open-source separation models for varying separation granularities (four, five, and six stems), and discuss their results.
Supervised and Unsupervised Learning of Audio Representations for Music Understanding
Oct 07, 2022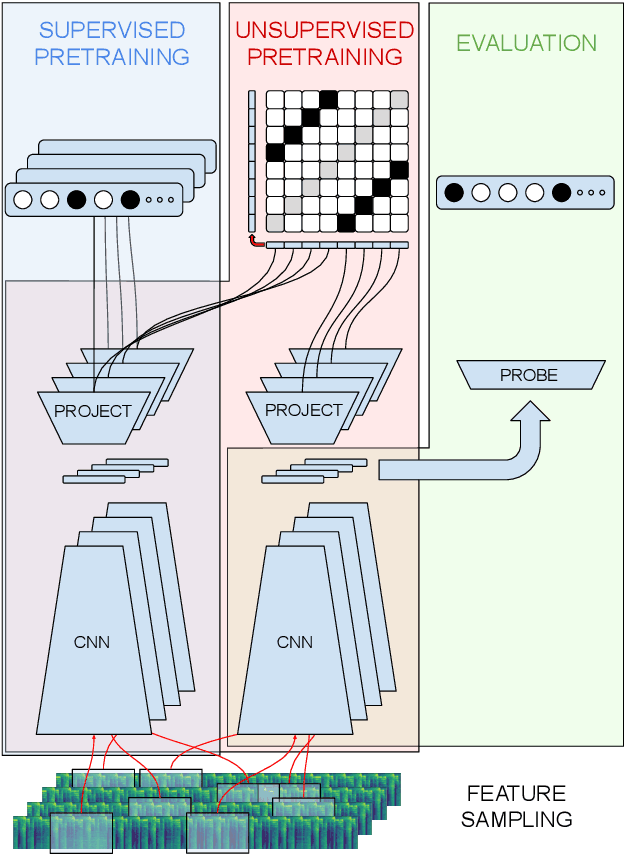
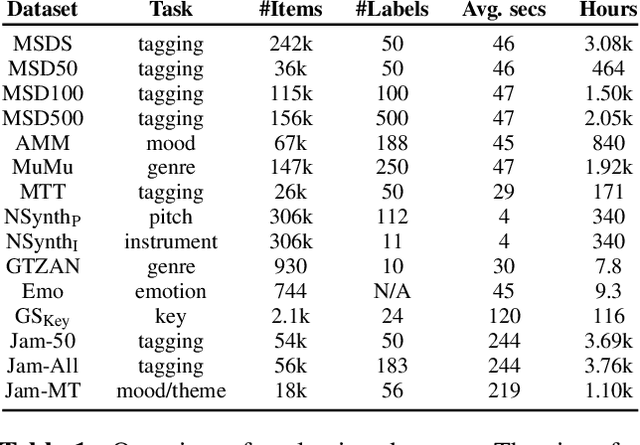
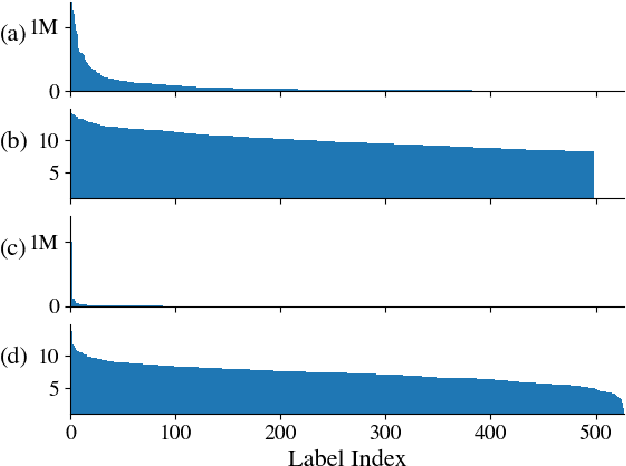
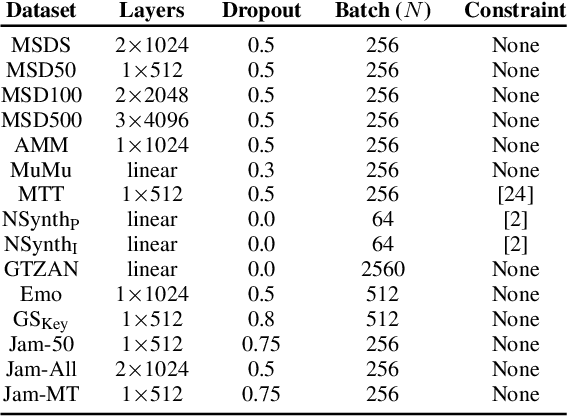
In this work, we provide a broad comparative analysis of strategies for pre-training audio understanding models for several tasks in the music domain, including labelling of genre, era, origin, mood, instrumentation, key, pitch, vocal characteristics, tempo and sonority. Specifically, we explore how the domain of pre-training datasets (music or generic audio) and the pre-training methodology (supervised or unsupervised) affects the adequacy of the resulting audio embeddings for downstream tasks. We show that models trained via supervised learning on large-scale expert-annotated music datasets achieve state-of-the-art performance in a wide range of music labelling tasks, each with novel content and vocabularies. This can be done in an efficient manner with models containing less than 100 million parameters that require no fine-tuning or reparameterization for downstream tasks, making this approach practical for industry-scale audio catalogs. Within the class of unsupervised learning strategies, we show that the domain of the training dataset can significantly impact the performance of representations learned by the model. We find that restricting the domain of the pre-training dataset to music allows for training with smaller batch sizes while achieving state-of-the-art in unsupervised learning -- and in some cases, supervised learning -- for music understanding. We also corroborate that, while achieving state-of-the-art performance on many tasks, supervised learning can cause models to specialize to the supervised information provided, somewhat compromising a model's generality.
Artist Similarity with Graph Neural Networks
Jul 30, 2021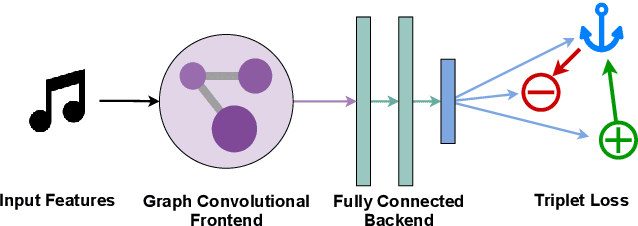

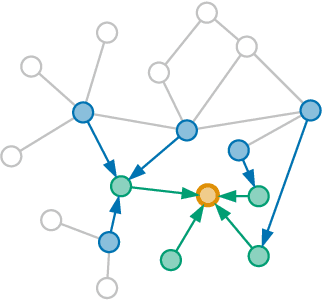
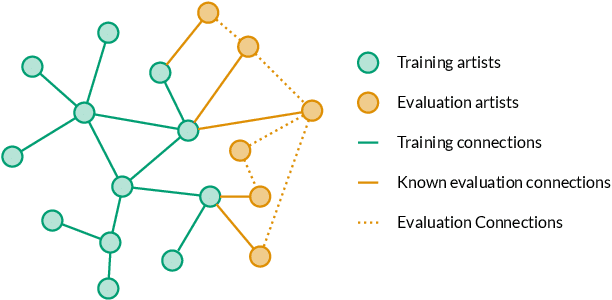
Artist similarity plays an important role in organizing, understanding, and subsequently, facilitating discovery in large collections of music. In this paper, we present a hybrid approach to computing similarity between artists using graph neural networks trained with triplet loss. The novelty of using a graph neural network architecture is to combine the topology of a graph of artist connections with content features to embed artists into a vector space that encodes similarity. To evaluate the proposed method, we compile the new OLGA dataset, which contains artist similarities from AllMusic, together with content features from AcousticBrainz. With 17,673 artists, this is the largest academic artist similarity dataset that includes content-based features to date. Moreover, we also showcase the scalability of our approach by experimenting with a much larger proprietary dataset. Results show the superiority of the proposed approach over current state-of-the-art methods for music similarity. Finally, we hope that the OLGA dataset will facilitate research on data-driven models for artist similarity.
Mood Classification Using Listening Data
Oct 22, 2020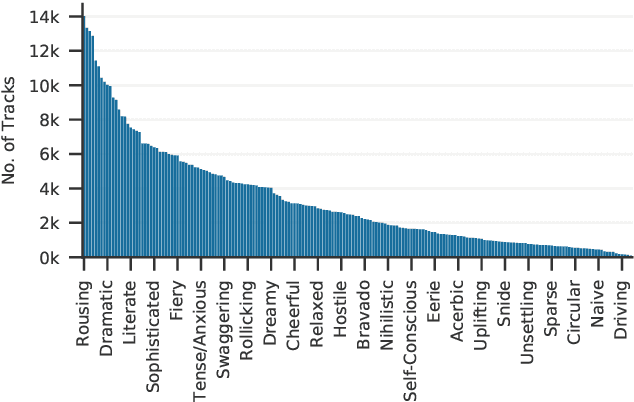
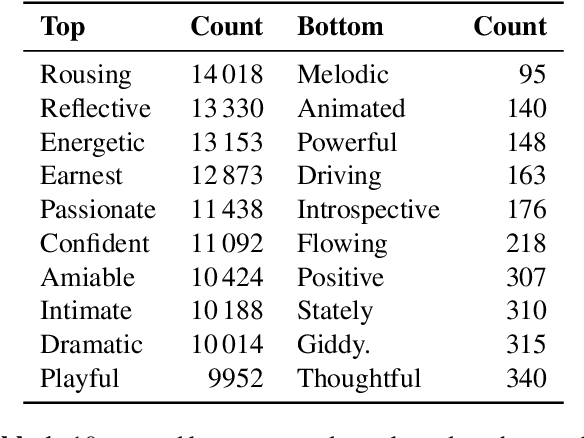
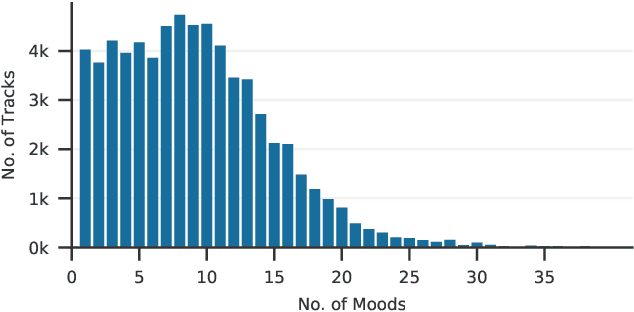
The mood of a song is a highly relevant feature for exploration and recommendation in large collections of music. These collections tend to require automatic methods for predicting such moods. In this work, we show that listening-based features outperform content-based ones when classifying moods: embeddings obtained through matrix factorization of listening data appear to be more informative of a track mood than embeddings based on its audio content. To demonstrate this, we compile a subset of the Million Song Dataset, totalling 67k tracks, with expert annotations of 188 different moods collected from AllMusic. Our results on this novel dataset not only expose the limitations of current audio-based models, but also aim to foster further reproducible research on this timely topic.
Automatic Chord Recognition with Higher-Order Harmonic Language Modelling
Aug 16, 2018



Common temporal models for automatic chord recognition model chord changes on a frame-wise basis. Due to this fact, they are unable to capture musical knowledge about chord progressions. In this paper, we propose a temporal model that enables explicit modelling of chord changes and durations. We then apply N-gram models and a neural-network-based acoustic model within this framework, and evaluate the effect of model overconfidence. Our results show that model overconfidence plays only a minor role (but target smoothing still improves the acoustic model), and that stronger chord language models do improve recognition results, however their effects are small compared to other domains.
Genre-Agnostic Key Classification With Convolutional Neural Networks
Aug 16, 2018

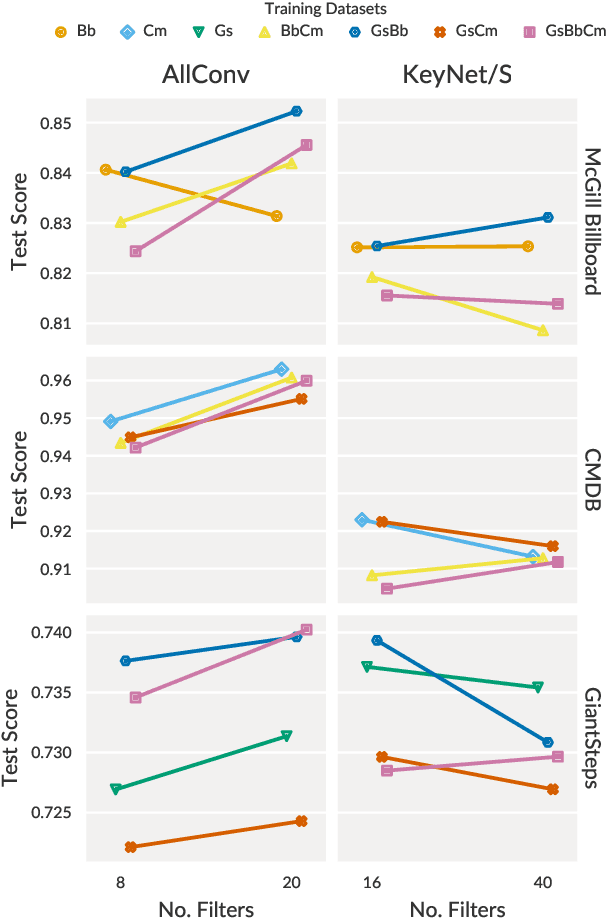

We propose modifications to the model structure and training procedure to a recently introduced Convolutional Neural Network for musical key classification. These modifications enable the network to learn a genre-independent model that performs better than models trained for specific music styles, which has not been the case in existing work. We analyse this generalisation capability on three datasets comprising distinct genres. We then evaluate the model on a number of unseen data sets, and show its superior performance compared to the state of the art. Finally, we investigate the model's performance on short excerpts of audio. From these experiments, we conclude that models need to consider the harmonic coherence of the whole piece when classifying the local key of short segments of audio.
Improved Chord Recognition by Combining Duration and Harmonic Language Models
Aug 16, 2018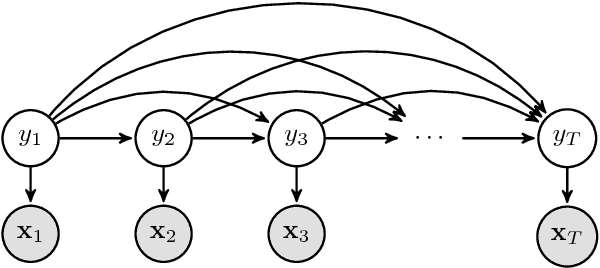

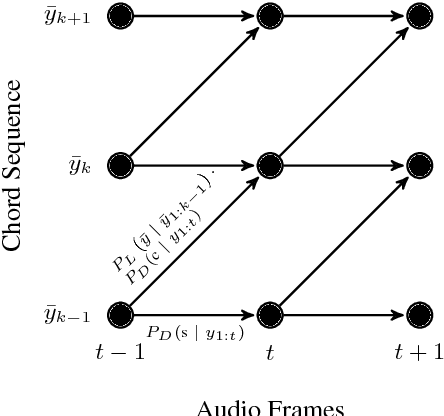

Chord recognition systems typically comprise an acoustic model that predicts chords for each audio frame, and a temporal model that casts these predictions into labelled chord segments. However, temporal models have been shown to only smooth predictions, without being able to incorporate musical information about chord progressions. Recent research discovered that it might be the low hierarchical level such models have been applied to (directly on audio frames) which prevents learning musical relationships, even for expressive models such as recurrent neural networks (RNNs). However, if applied on the level of chord sequences, RNNs indeed can become powerful chord predictors. In this paper, we disentangle temporal models into a harmonic language model---to be applied on chord sequences---and a chord duration model that connects the chord-level predictions of the language model to the frame-level predictions of the acoustic model. In our experiments, we explore the impact of each model on the chord recognition score, and show that using harmonic language and duration models improves the results.
A Large-Scale Study of Language Models for Chord Prediction
Apr 05, 2018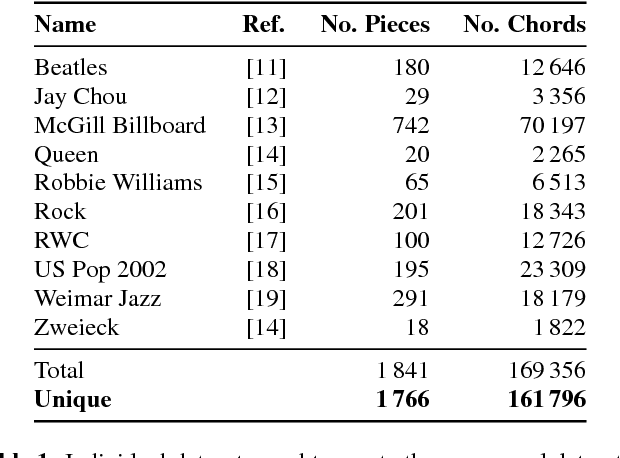
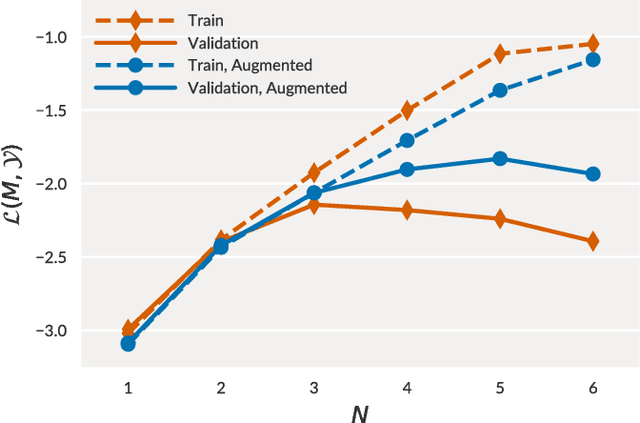


We conduct a large-scale study of language models for chord prediction. Specifically, we compare N-gram models to various flavours of recurrent neural networks on a comprehensive dataset comprising all publicly available datasets of annotated chords known to us. This large amount of data allows us to systematically explore hyper-parameter settings for the recurrent neural networks---a crucial step in achieving good results with this model class. Our results show not only a quantitative difference between the models, but also a qualitative one: in contrast to static N-gram models, certain RNN configurations adapt to the songs at test time. This finding constitutes a further step towards the development of chord recognition systems that are more aware of local musical context than what was previously possible.
End-to-End Musical Key Estimation Using a Convolutional Neural Network
Jun 09, 2017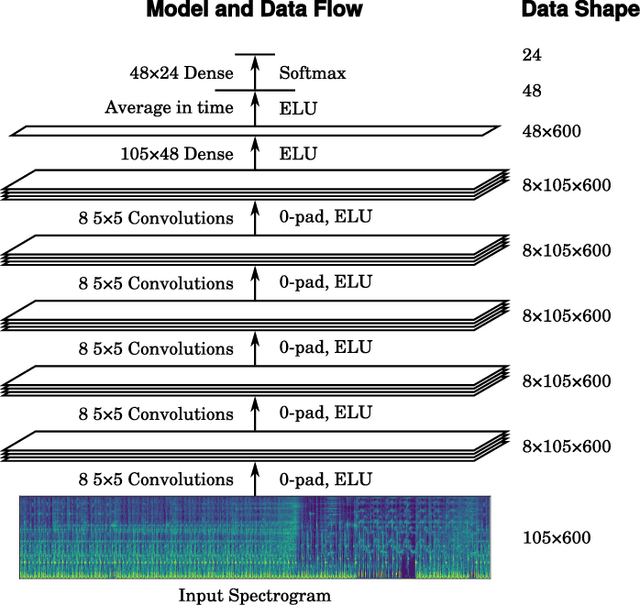

We present an end-to-end system for musical key estimation, based on a convolutional neural network. The proposed system not only out-performs existing key estimation methods proposed in the academic literature; it is also capable of learning a unified model for diverse musical genres that performs comparably to existing systems specialised for specific genres. Our experiments confirm that different genres do differ in their interpretation of tonality, and thus a system tuned e.g. for pop music performs subpar on pieces of electronic music. They also reveal that such cross-genre setups evoke specific types of error (predicting the relative or parallel minor). However, using the data-driven approach proposed in this paper, we can train models that deal with multiple musical styles adequately, and without major losses in accuracy.
On the Futility of Learning Complex Frame-Level Language Models for Chord Recognition
Mar 31, 2017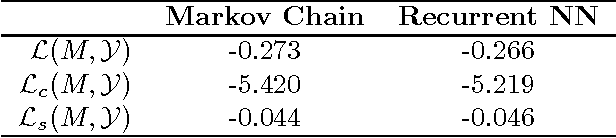


Chord recognition systems use temporal models to post-process frame-wise chord preditions from acoustic models. Traditionally, first-order models such as Hidden Markov Models were used for this task, with recent works suggesting to apply Recurrent Neural Networks instead. Due to their ability to learn longer-term dependencies, these models are supposed to learn and to apply musical knowledge, instead of just smoothing the output of the acoustic model. In this paper, we argue that learning complex temporal models at the level of audio frames is futile on principle, and that non-Markovian models do not perform better than their first-order counterparts. We support our argument through three experiments on the McGill Billboard dataset. The first two show 1) that when learning complex temporal models at the frame level, improvements in chord sequence modelling are marginal; and 2) that these improvements do not translate when applied within a full chord recognition system. The third, still rather preliminary experiment gives first indications that the use of complex sequential models for chord prediction at higher temporal levels might be more promising.