 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Chord Recognition by Combining Duration and Harmonic Language Models
Paper and Code
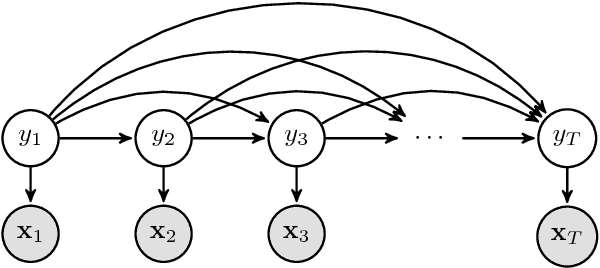

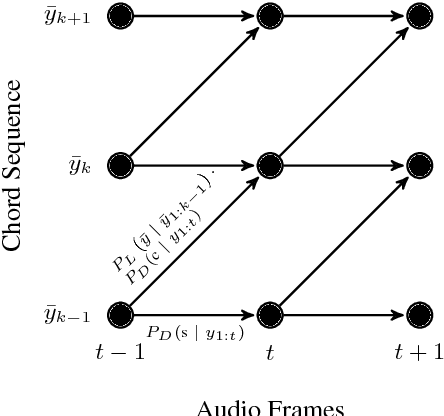

Chord recognition systems typically comprise an acoustic model that predicts chords for each audio frame, and a temporal model that casts these predictions into labelled chord segments. However, temporal models have been shown to only smooth predictions, without being able to incorporate musical information about chord progressions. Recent research discovered that it might be the low hierarchical level such models have been applied to (directly on audio frames) which prevents learning musical relationships, even for expressive models such as recurrent neural networks (RNNs). However, if applied on the level of chord sequences, RNNs indeed can become powerful chord predictors. In this paper, we disentangle temporal models into a harmonic language model---to be applied on chord sequences---and a chord duration model that connects the chord-level predictions of the language model to the frame-level predictions of the acoustic model. In our experiments, we explore the impact of each model on the chord recognition score, and show that using harmonic language and duration models improves the results.