 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Futility of Learning Complex Frame-Level Language Models for Chord Recognition
Paper and Code
Mar 31, 2017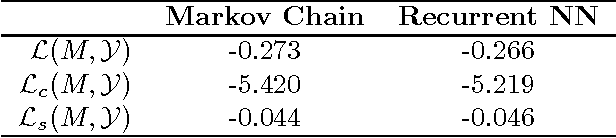


Chord recognition systems use temporal models to post-process frame-wise chord preditions from acoustic models. Traditionally, first-order models such as Hidden Markov Models were used for this task, with recent works suggesting to apply Recurrent Neural Networks instead. Due to their ability to learn longer-term dependencies, these models are supposed to learn and to apply musical knowledge, instead of just smoothing the output of the acoustic model. In this paper, we argue that learning complex temporal models at the level of audio frames is futile on principle, and that non-Markovian models do not perform better than their first-order counterparts. We support our argument through three experiments on the McGill Billboard dataset. The first two show 1) that when learning complex temporal models at the frame level, improvements in chord sequence modelling are marginal; and 2) that these improvements do not translate when applied within a full chord recognition system. The third, still rather preliminary experiment gives first indications that the use of complex sequential models for chord prediction at higher temporal levels might be more promising.