 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Music Autotagging with MGPHot Expert Annotations vs. Generic Tag Datasets
Sep 08, 2025



Music autotagging aims to automatically assign descriptive tags, such as genre, mood, or instrumentation, to audio recordings. Due to its challenges, diversity of semantic descriptions, and practical value in various applications, it has become a common downstream task for evaluating the performance of general-purpose music representations learned from audio data. We introduce a new benchmarking dataset based on the recently published MGPHot dataset, which includes expert musicological annotations, allowing for additional insights and comparisons with results obtained on common generic tag datasets. While MGPHot annotations have been shown to be useful for computational musicology, the original dataset neither includes audio nor provides evaluation setups for its use as a standardized autotagging benchmark. To address this, we provide a curated set of YouTube URLs with retrievable audio, and propose a train/val/test split for standardized evaluation, and precomputed representations for seven state-of-the-art models. Using these resources, we evaluated these models in MGPHot and standard reference tag datasets, highlighting key differences between expert and generic tag annotations. Altogether, our contributions provide a more advanced benchmarking framework for future research in music understanding.
Contrastive Learning for Cross-modal Artist Retrieval
Aug 12, 2023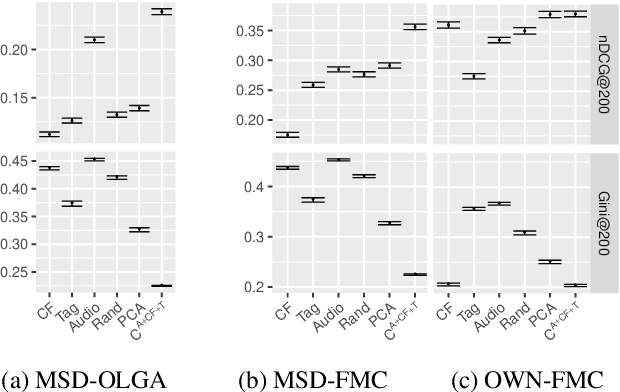



Music retrieval and recommendation applications often rely on content features encoded as embeddings, which provide vector representations of items in a music dataset. Numerous complementary embeddings can be derived from processing items originally represented in several modalities, e.g., audio signals, user interaction data, or editorial data. However, data of any given modality might not be available for all items in any music dataset. In this work, we propose a method based on contrastive learning to combine embeddings from multiple modalities and explore the impact of the presence or absence of embeddings from diverse modalities in an artist similarity task. Experiments on two datasets suggest that our contrastive method outperforms single-modality embeddings and baseline algorithms for combining modalities, both in terms of artist retrieval accuracy and coverage. Improvements with respect to other methods are particularly significant for less popular query artists. We demonstrate our method successfully combines complementary information from diverse modalities, and is more robust to missing modality data (i.e., it better handles the retrieval of artists with different modality embeddings than the query artist's).
Supervised and Unsupervised Learning of Audio Representations for Music Understanding
Oct 07, 2022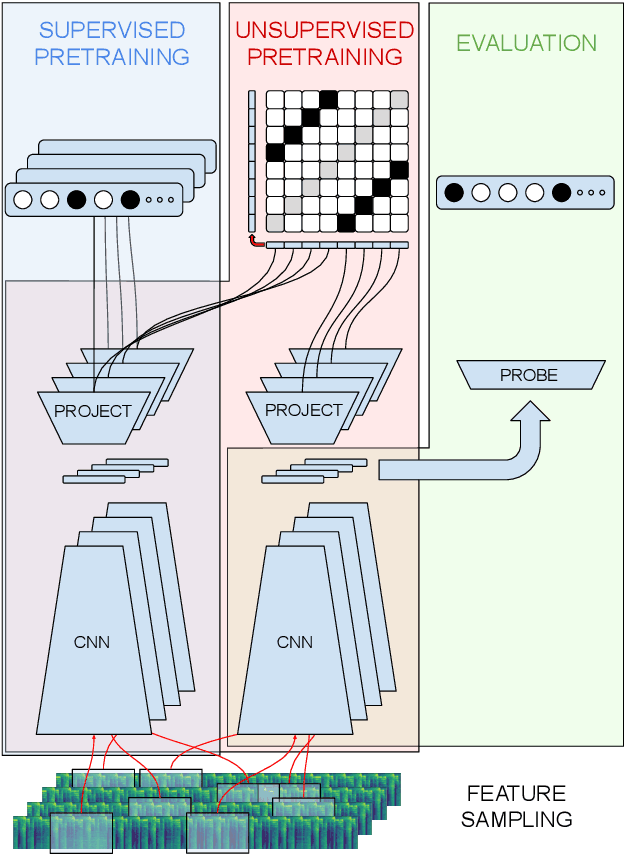
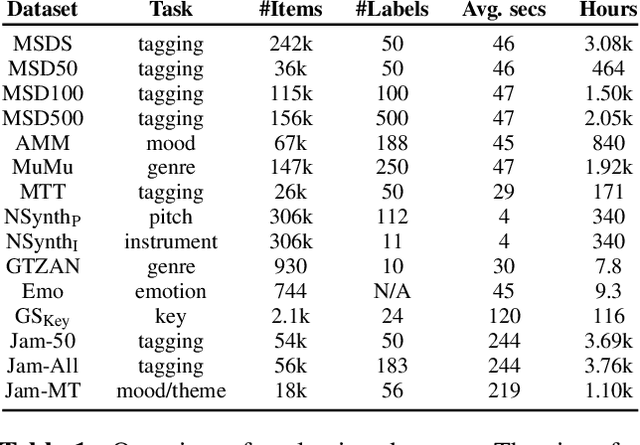
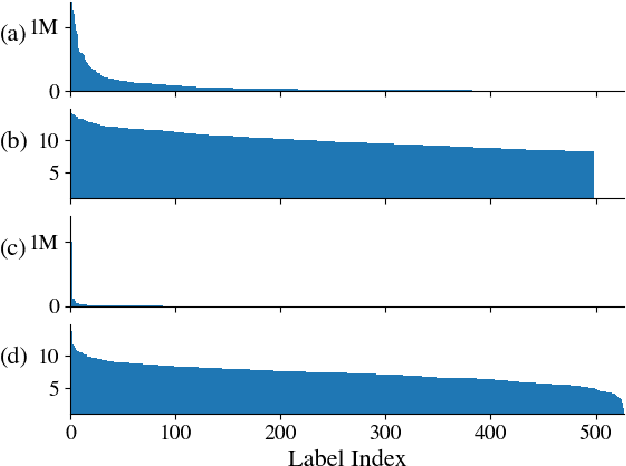
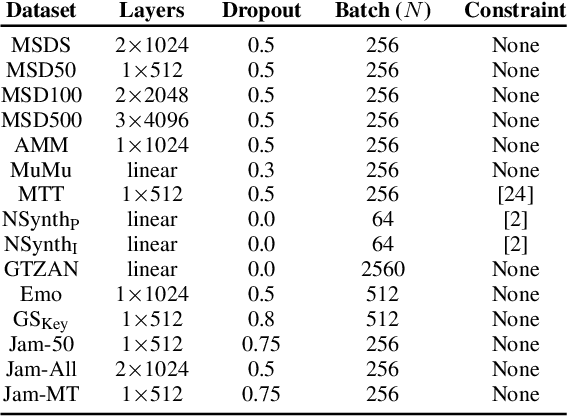
In this work, we provide a broad comparative analysis of strategies for pre-training audio understanding models for several tasks in the music domain, including labelling of genre, era, origin, mood, instrumentation, key, pitch, vocal characteristics, tempo and sonority. Specifically, we explore how the domain of pre-training datasets (music or generic audio) and the pre-training methodology (supervised or unsupervised) affects the adequacy of the resulting audio embeddings for downstream tasks. We show that models trained via supervised learning on large-scale expert-annotated music datasets achieve state-of-the-art performance in a wide range of music labelling tasks, each with novel content and vocabularies. This can be done in an efficient manner with models containing less than 100 million parameters that require no fine-tuning or reparameterization for downstream tasks, making this approach practical for industry-scale audio catalogs. Within the class of unsupervised learning strategies, we show that the domain of the training dataset can significantly impact the performance of representations learned by the model. We find that restricting the domain of the pre-training dataset to music allows for training with smaller batch sizes while achieving state-of-the-art in unsupervised learning -- and in some cases, supervised learning -- for music understanding. We also corroborate that, while achieving state-of-the-art performance on many tasks, supervised learning can cause models to specialize to the supervised information provided, somewhat compromising a model's generality.
Artist Similarity with Graph Neural Networks
Jul 30, 2021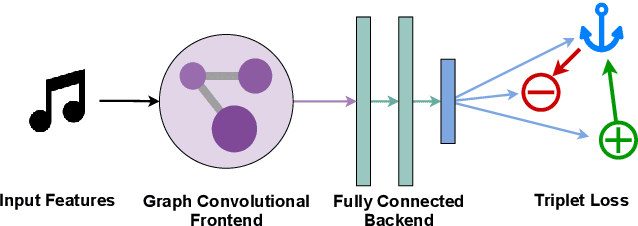

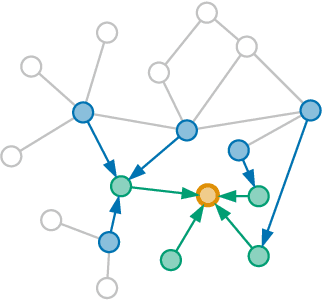
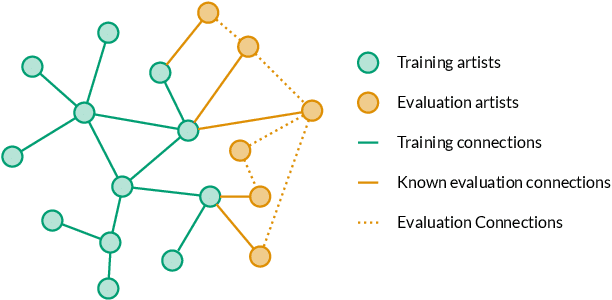
Artist similarity plays an important role in organizing, understanding, and subsequently, facilitating discovery in large collections of music. In this paper, we present a hybrid approach to computing similarity between artists using graph neural networks trained with triplet loss. The novelty of using a graph neural network architecture is to combine the topology of a graph of artist connections with content features to embed artists into a vector space that encodes similarity. To evaluate the proposed method, we compile the new OLGA dataset, which contains artist similarities from AllMusic, together with content features from AcousticBrainz. With 17,673 artists, this is the largest academic artist similarity dataset that includes content-based features to date. Moreover, we also showcase the scalability of our approach by experimenting with a much larger proprietary dataset. Results show the superiority of the proposed approach over current state-of-the-art methods for music similarity. Finally, we hope that the OLGA dataset will facilitate research on data-driven models for artist similarity.
Mood Classification Using Listening Data
Oct 22, 2020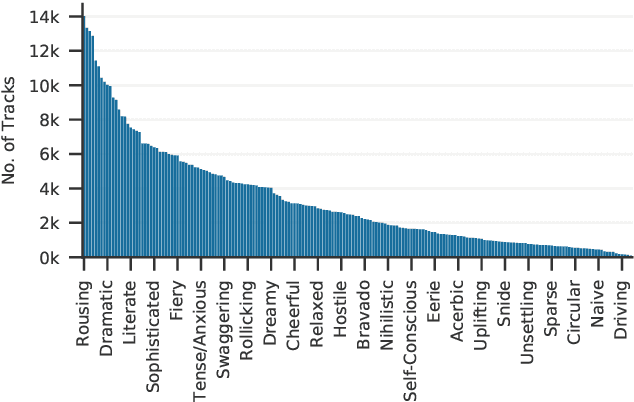
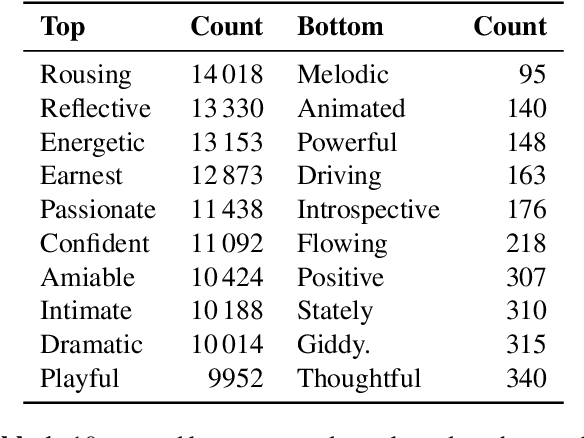
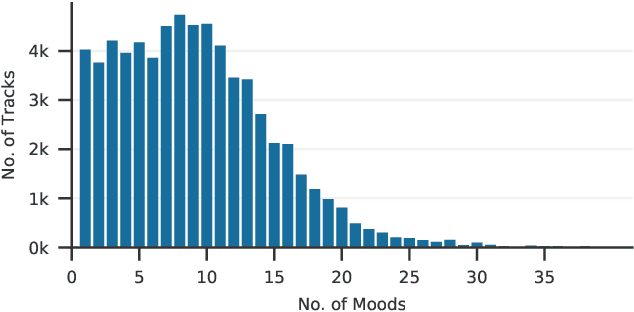
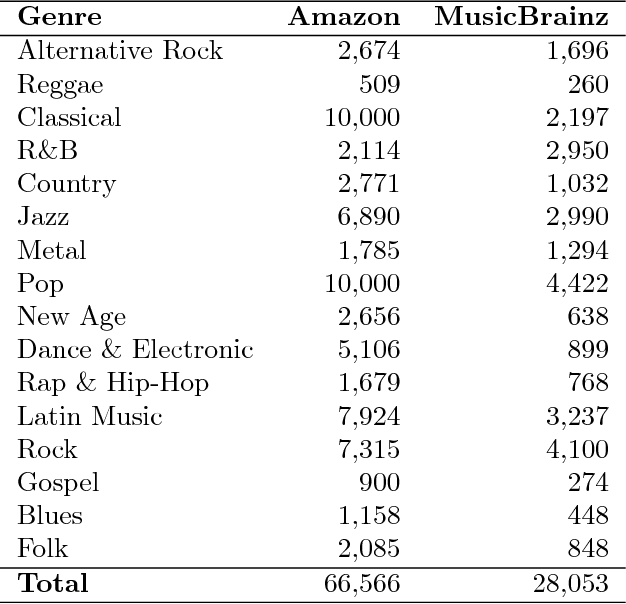
The mood of a song is a highly relevant feature for exploration and recommendation in large collections of music. These collections tend to require automatic methods for predicting such moods. In this work, we show that listening-based features outperform content-based ones when classifying moods: embeddings obtained through matrix factorization of listening data appear to be more informative of a track mood than embeddings based on its audio content. To demonstrate this, we compile a subset of the Million Song Dataset, totalling 67k tracks, with expert annotations of 188 different moods collected from AllMusic. Our results on this novel dataset not only expose the limitations of current audio-based models, but also aim to foster further reproducible research on this timely topic.
Natural Language Processing for Music Knowledge Discovery
Jul 06, 2018

Today, a massive amount of musical knowledge is stored in written form, with testimonies dated as far back as several centuries ago. In this work, we present different Natural Language Processing (NLP) approaches to harness the potential of these text collections for automatic music knowledge discovery, covering different phases in a prototypical NLP pipeline, namely corpus compilation, text-mining, information extraction, knowledge graph generation and sentiment analysis. Each of these approaches is presented alongside different use cases (i.e., flamenco, Renaissance and popular music) where large collections of documents are processed, and conclusions stemming from data-driven analyses are presented and discussed.
A Deep Multimodal Approach for Cold-start Music Recommendation
Jul 24, 2017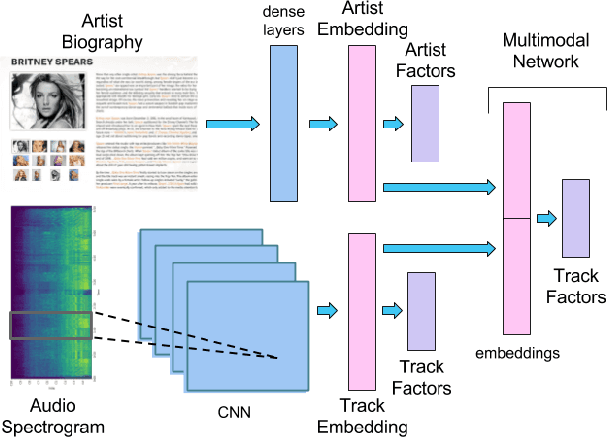
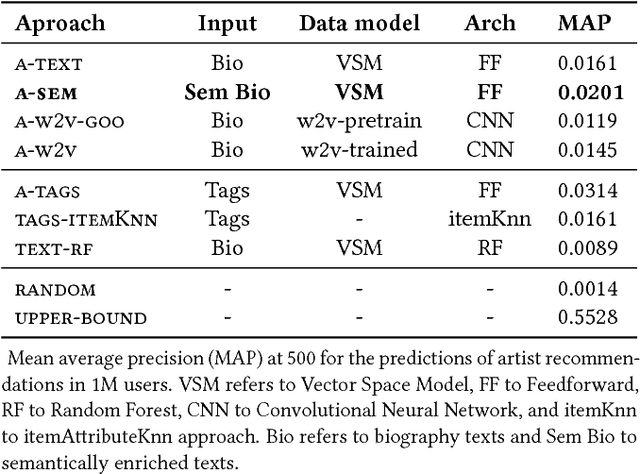

An increasing amount of digital music is being published daily. Music streaming services often ingest all available music, but this poses a challenge: how to recommend new artists for which prior knowledge is scarce? In this work we aim to address this so-called cold-start problem by combining text and audio information with user feedback data using deep network architectures. Our method is divided into three steps. First, artist embeddings are learned from biographies by combining semantics, text features, and aggregated usage data. Second, track embeddings are learned from the audio signal and available feedback data. Finally, artist and track embeddings are combined in a multimodal network. Results suggest that both splitting the recommendation problem between feature levels (i.e., artist metadata and audio track), and merging feature embeddings in a multimodal approach improve the accuracy of the recommendations.