Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Processing for Music Knowledge Discovery
Paper and Code
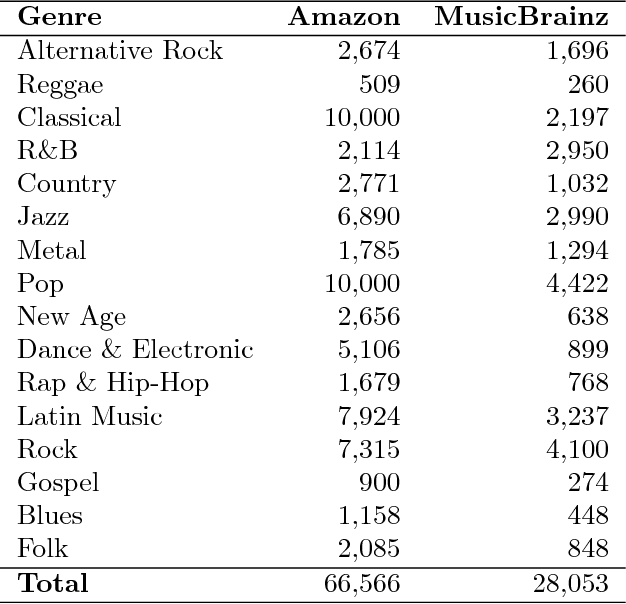
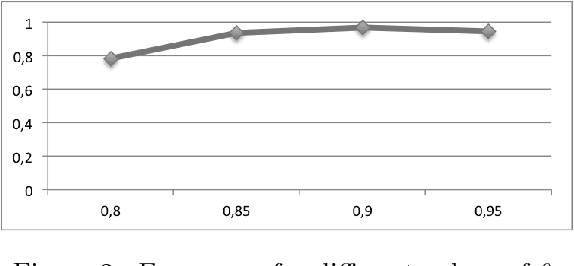

Today, a massive amount of musical knowledge is stored in written form, with testimonies dated as far back as several centuries ago. In this work, we present different Natural Language Processing (NLP) approaches to harness the potential of these text collections for automatic music knowledge discovery, covering different phases in a prototypical NLP pipeline, namely corpus compilation, text-mining, information extraction, knowledge graph generation and sentiment analysis. Each of these approaches is presented alongside different use cases (i.e., flamenco, Renaissance and popular music) where large collections of documents are processed, and conclusions stemming from data-driven analyses are presented and discussed.
* Journal of New Music Research (2018)
View paper on