 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Disentangled Representations for Controllable Music Generation
Feb 15, 2026Recent approaches in music generation rely on disentangled representations, often labeled as structure and timbre or local and global, to enable controllable synthesis. Yet the underlying properties of these embeddings remain underexplored. In this work, we evaluate such disentangled representations in a set of music audio models for controllable generation using a probing-based framework that goes beyond standard downstream tasks. The selected models reflect diverse unsupervised disentanglement strategies, including inductive biases, data augmentations, adversarial objectives, and staged training procedures. We further isolate specific strategies to analyze their effect. Our analysis spans four key axes: informativeness, equivariance, invariance, and disentanglement, which are assessed across datasets, tasks, and controlled transformations. Our findings reveal inconsistencies between intended and actual semantics of the embeddings, suggesting that current strategies fall short of producing truly disentangled representations, and prompting a re-examination of how controllability is approached in music generation.
Benchmarking Music Autotagging with MGPHot Expert Annotations vs. Generic Tag Datasets
Sep 08, 2025



Music autotagging aims to automatically assign descriptive tags, such as genre, mood, or instrumentation, to audio recordings. Due to its challenges, diversity of semantic descriptions, and practical value in various applications, it has become a common downstream task for evaluating the performance of general-purpose music representations learned from audio data. We introduce a new benchmarking dataset based on the recently published MGPHot dataset, which includes expert musicological annotations, allowing for additional insights and comparisons with results obtained on common generic tag datasets. While MGPHot annotations have been shown to be useful for computational musicology, the original dataset neither includes audio nor provides evaluation setups for its use as a standardized autotagging benchmark. To address this, we provide a curated set of YouTube URLs with retrievable audio, and propose a train/val/test split for standardized evaluation, and precomputed representations for seven state-of-the-art models. Using these resources, we evaluated these models in MGPHot and standard reference tag datasets, highlighting key differences between expert and generic tag annotations. Altogether, our contributions provide a more advanced benchmarking framework for future research in music understanding.
Fractional Fourier Sound Synthesis
Jun 10, 2025This paper explores the innovative application of the Fractional Fourier Transform (FrFT) in sound synthesis, highlighting its potential to redefine time-frequency analysis in audio processing. As an extension of the classical Fourier Transform, the FrFT introduces fractional order parameters, enabling a continuous interpolation between time and frequency domains and unlocking unprecedented flexibility in signal manipulation. Crucially, the FrFT also opens the possibility of directly synthesizing sounds in the alpha-domain, providing a unique framework for creating timbral and dynamic characteristics unattainable through conventional methods. This work delves into the mathematical principles of the FrFT, its historical evolution, and its capabilities for synthesizing complex audio textures. Through experimental analyses, we showcase novel sound design techniques, such as alpha-synthesis and alpha-filtering, which leverage the FrFT's time-frequency rotation properties to produce innovative sonic results. The findings affirm the FrFT's value as a transformative tool for composers, sound designers, and researchers seeking to push the boundaries of auditory creativity.
A Statistics-Driven Differentiable Approach for Sound Texture Synthesis and Analysis
Jun 04, 2025In this work, we introduce TexStat, a novel loss function specifically designed for the analysis and synthesis of texture sounds characterized by stochastic structure and perceptual stationarity. Drawing inspiration from the statistical and perceptual framework of McDermott and Simoncelli, TexStat identifies similarities between signals belonging to the same texture category without relying on temporal structure. We also propose using TexStat as a validation metric alongside Frechet Audio Distances (FAD) to evaluate texture sound synthesis models. In addition to TexStat, we present TexEnv, an efficient, lightweight and differentiable texture sound synthesizer that generates audio by imposing amplitude envelopes on filtered noise. We further integrate these components into TexDSP, a DDSP-inspired generative model tailored for texture sounds. Through extensive experiments across various texture sound types, we demonstrate that TexStat is perceptually meaningful, time-invariant, and robust to noise, features that make it effective both as a loss function for generative tasks and as a validation metric. All tools and code are provided as open-source contributions and our PyTorch implementations are efficient, differentiable, and highly configurable, enabling its use in both generative tasks and as a perceptually grounded evaluation metric.
Automatic Estimation of Singing Voice Musical Dynamics
Oct 27, 2024



Musical dynamics form a core part of expressive singing voice performances. However, automatic analysis of musical dynamics for singing voice has received limited attention partly due to the scarcity of suitable datasets and a lack of clear evaluation frameworks. To address this challenge, we propose a methodology for dataset curation. Employing the proposed methodology, we compile a dataset comprising 509 musical dynamics annotated singing voice performances, aligned with 163 score files, leveraging state-of-the-art source separation and alignment techniques. The scores are sourced from the OpenScore Lieder corpus of romantic-era compositions, widely known for its wealth of expressive annotations. Utilizing the curated dataset, we train a multi-head attention based CNN model with varying window sizes to evaluate the effectiveness of estimating musical dynamics. We explored two distinct perceptually motivated input representations for the model training: log-Mel spectrum and bark-scale based features. For testing, we manually curate another dataset of 25 musical dynamics annotated performances in collaboration with a professional vocalist. We conclude through our experiments that bark-scale based features outperform log-Mel-features for the task of singing voice dynamics prediction. The dataset along with the code is shared publicly for further research on the topic.
Discogs-VI: A Musical Version Identification Dataset Based on Public Editorial Metadata
Oct 22, 2024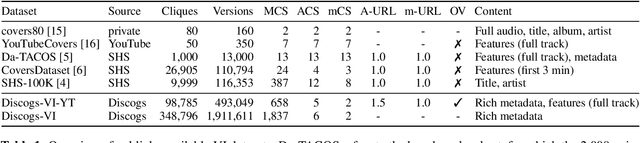
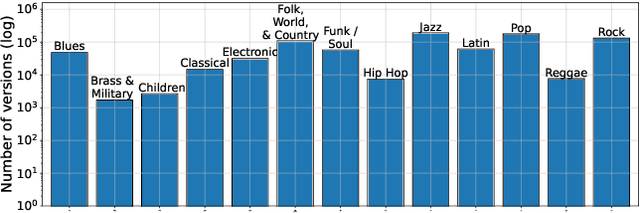
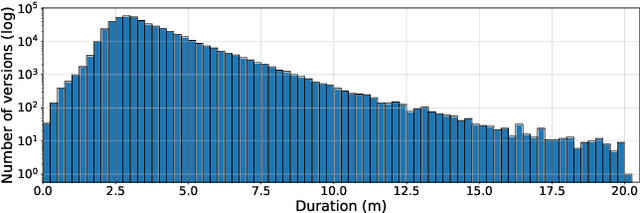
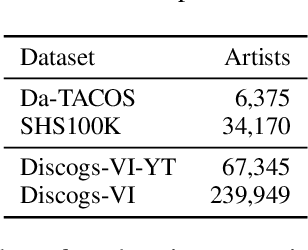
Current version identification (VI) datasets often lack sufficient size and musical diversity to train robust neural networks (NNs). Additionally, their non-representative clique size distributions prevent realistic system evaluations. To address these challenges, we explore the untapped potential of the rich editorial metadata in the Discogs music database and create a large dataset of musical versions containing about 1,900,000 versions across 348,000 cliques. Utilizing a high-precision search algorithm, we map this dataset to official music uploads on YouTube, resulting in a dataset of approximately 493,000 versions across 98,000 cliques. This dataset offers over nine times the number of cliques and over four times the number of versions than existing datasets. We demonstrate the utility of our dataset by training a baseline NN without extensive model complexities or data augmentations, which achieves competitive results on the SHS100K and Da-TACOS datasets. Our dataset, along with the tools used for its creation, the extracted audio features, and a trained model, are all publicly available online.
Heterogeneous sound classification with the Broad Sound Taxonomy and Dataset
Oct 01, 2024



Automatic sound classification has a wide range of applications in machine listening, enabling context-aware sound processing and understanding. This paper explores methodologies for automatically classifying heterogeneous sounds characterized by high intra-class variability. Our study evaluates the classification task using the Broad Sound Taxonomy, a two-level taxonomy comprising 28 classes designed to cover a heterogeneous range of sounds with semantic distinctions tailored for practical user applications. We construct a dataset through manual annotation to ensure accuracy, diverse representation within each class and relevance in real-world scenarios. We compare a variety of both traditional and modern machine learning approaches to establish a baseline for the task of heterogeneous sound classification. We investigate the role of input features, specifically examining how acoustically derived sound representations compare to embeddings extracted with pre-trained deep neural networks that capture both acoustic and semantic information about sounds. Experimental results illustrate that audio embeddings encoding acoustic and semantic information achieve higher accuracy in the classification task. After careful analysis of classification errors, we identify some underlying reasons for failure and propose actions to mitigate them. The paper highlights the need for deeper exploration of all stages of classification, understanding the data and adopting methodologies capable of effectively handling data complexity and generalizing in real-world sound environments.
The Role of Large Language Models in Musicology: Are We Ready to Trust the Machines?
Sep 03, 2024



In this work, we explore the use and reliability of Large Language Models (LLMs) in musicology. From a discussion with experts and students, we assess the current acceptance and concerns regarding this, nowadays ubiquitous, technology. We aim to go one step further, proposing a semi-automatic method to create an initial benchmark using retrieval-augmented generation models and multiple-choice question generation, validated by human experts. Our evaluation on 400 human-validated questions shows that current vanilla LLMs are less reliable than retrieval augmented generation from music dictionaries. This paper suggests that the potential of LLMs in musicology requires musicology driven research that can specialized LLMs by including accurate and reliable domain knowledge.
Towards Explainable and Interpretable Musical Difficulty Estimation: A Parameter-efficient Approach
Aug 01, 2024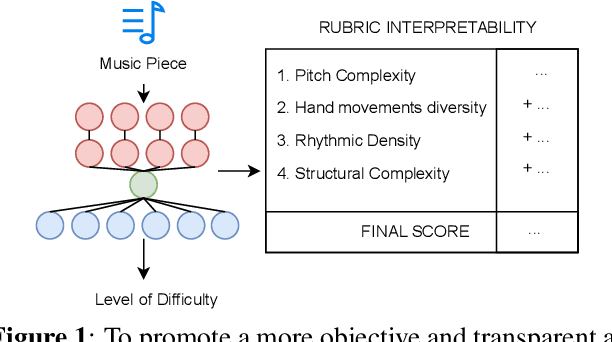
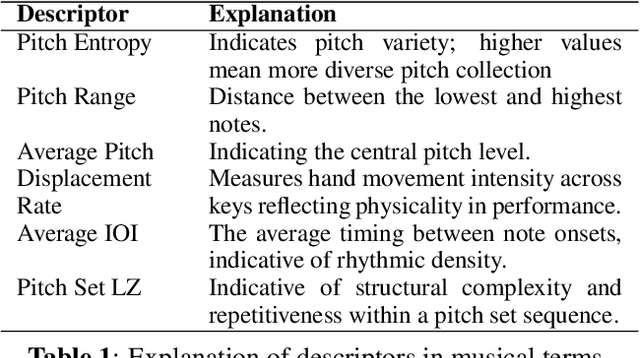
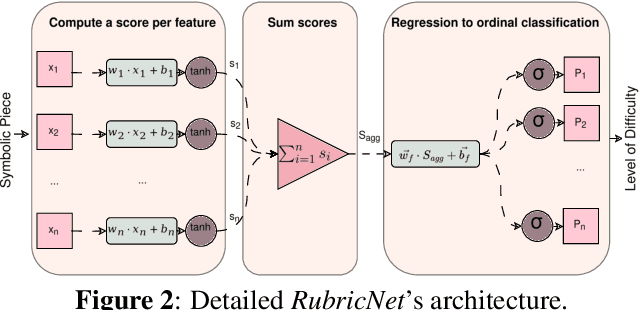
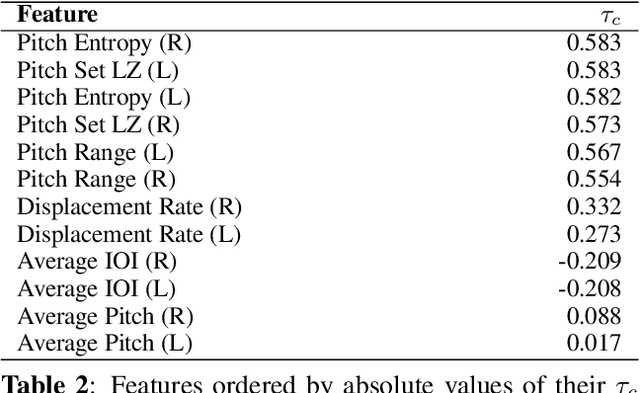
Estimating music piece difficulty is important for organizing educational music collections. This process could be partially automatized to facilitate the educator's role. Nevertheless, the decisions performed by prevalent deep-learning models are hardly understandable, which may impair the acceptance of such a technology in music education curricula. Our work employs explainable descriptors for difficulty estimation in symbolic music representations. Furthermore, through a novel parameter-efficient white-box model, we outperform previous efforts while delivering interpretable results. These comprehensible outcomes emulate the functionality of a rubric, a tool widely used in music education. Our approach, evaluated in piano repertoire categorized in 9 classes, achieved 41.4% accuracy independently, with a mean squared error (MSE) of 1.7, showing precise difficulty estimation. Through our baseline, we illustrate how building on top of past research can offer alternatives for music difficulty assessment which are explainable and interpretable. With this, we aim to promote a more effective communication between the Music Information Retrieval (MIR) community and the music education one.
Towards Assessing Data Replication in Music Generation with Music Similarity Metrics on Raw Audio
Jul 19, 2024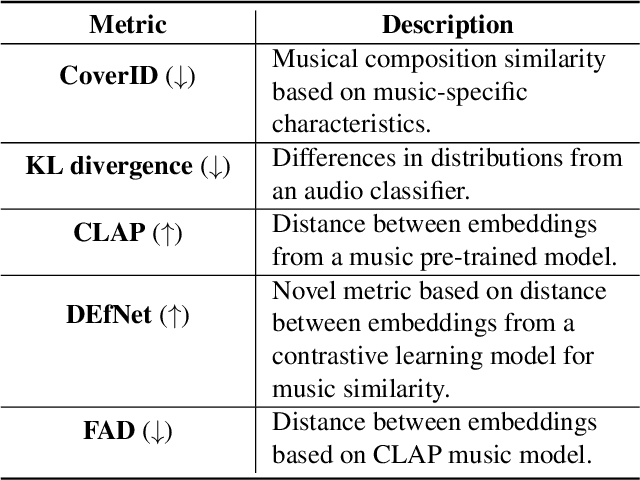
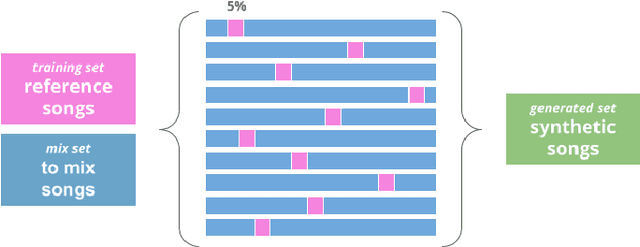
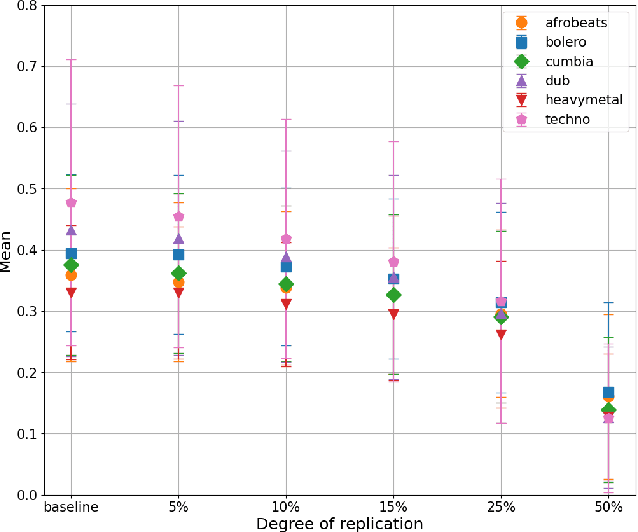
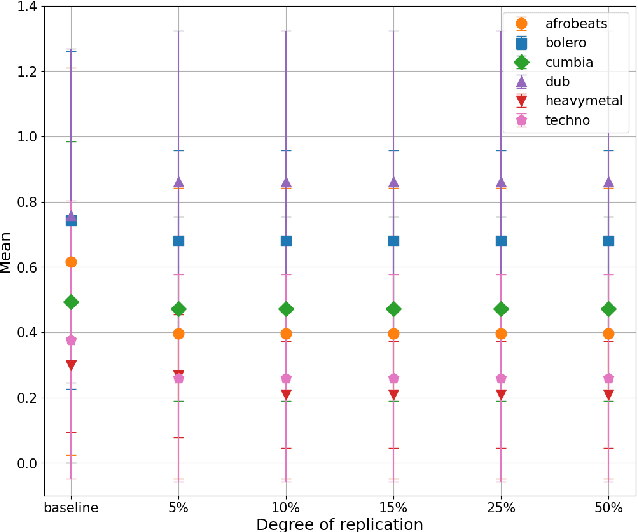
Recent advancements in music generation are raising multiple concerns about the implications of AI in creative music processes, current business models and impacts related to intellectual property management. A relevant challenge is the potential replication and plagiarism of the training set in AI-generated music, which could lead to misuse of data and intellectual property rights violations. To tackle this issue, we present the Music Replication Assessment (MiRA) tool: a model-independent open evaluation method based on diverse audio music similarity metrics to assess data replication of the training set. We evaluate the ability of five metrics to identify exact replication, by conducting a controlled replication experiment in different music genres based on synthetic samples. Our results show that the proposed methodology can estimate exact data replication with a proportion higher than 10%. By introducing the MiRA tool, we intend to encourage the open evaluation of music generative models by researchers, developers and users concerning data replication, highlighting the importance of ethical, social, legal and economic consequences of generative AI in the music domain.