 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Situated Stabilities of a Rhythm Generation System through Variational Cross-Examination
Sep 05, 2025This paper investigates GrooveTransformer, a real-time rhythm generation system, through the postphenomenological framework of Variational Cross-Examination (VCE). By reflecting on its deployment across three distinct artistic contexts, we identify three stabilities: an autonomous drum accompaniment generator, a rhythmic control voltage sequencer in Eurorack format, and a rhythm driver for a harmonic accompaniment system. The versatility of its applications was not an explicit goal from the outset of the project. Thus, we ask: how did this multistability emerge? Through VCE, we identify three key contributors to its emergence: the affordances of system invariants, the interdisciplinary collaboration, and the situated nature of its development. We conclude by reflecting on the viability of VCE as a descriptive and analytical method for Digital Musical Instrument (DMI) design, emphasizing its value in uncovering how technologies mediate, co-shape, and are co-shaped by users and contexts.
Fractional Fourier Sound Synthesis
Jun 10, 2025This paper explores the innovative application of the Fractional Fourier Transform (FrFT) in sound synthesis, highlighting its potential to redefine time-frequency analysis in audio processing. As an extension of the classical Fourier Transform, the FrFT introduces fractional order parameters, enabling a continuous interpolation between time and frequency domains and unlocking unprecedented flexibility in signal manipulation. Crucially, the FrFT also opens the possibility of directly synthesizing sounds in the alpha-domain, providing a unique framework for creating timbral and dynamic characteristics unattainable through conventional methods. This work delves into the mathematical principles of the FrFT, its historical evolution, and its capabilities for synthesizing complex audio textures. Through experimental analyses, we showcase novel sound design techniques, such as alpha-synthesis and alpha-filtering, which leverage the FrFT's time-frequency rotation properties to produce innovative sonic results. The findings affirm the FrFT's value as a transformative tool for composers, sound designers, and researchers seeking to push the boundaries of auditory creativity.
A Statistics-Driven Differentiable Approach for Sound Texture Synthesis and Analysis
Jun 04, 2025In this work, we introduce TexStat, a novel loss function specifically designed for the analysis and synthesis of texture sounds characterized by stochastic structure and perceptual stationarity. Drawing inspiration from the statistical and perceptual framework of McDermott and Simoncelli, TexStat identifies similarities between signals belonging to the same texture category without relying on temporal structure. We also propose using TexStat as a validation metric alongside Frechet Audio Distances (FAD) to evaluate texture sound synthesis models. In addition to TexStat, we present TexEnv, an efficient, lightweight and differentiable texture sound synthesizer that generates audio by imposing amplitude envelopes on filtered noise. We further integrate these components into TexDSP, a DDSP-inspired generative model tailored for texture sounds. Through extensive experiments across various texture sound types, we demonstrate that TexStat is perceptually meaningful, time-invariant, and robust to noise, features that make it effective both as a loss function for generative tasks and as a validation metric. All tools and code are provided as open-source contributions and our PyTorch implementations are efficient, differentiable, and highly configurable, enabling its use in both generative tasks and as a perceptually grounded evaluation metric.
The language of sound search: Examining User Queries in Audio Search Engines
Oct 10, 2024



This study examines textual, user-written search queries within the context of sound search engines, encompassing various applications such as foley, sound effects, and general audio retrieval. Current research inadequately addresses real-world user needs and behaviours in designing text-based audio retrieval systems. To bridge this gap, we analysed search queries from two sources: a custom survey and Freesound website query logs. The survey was designed to collect queries for an unrestricted, hypothetical sound search engine, resulting in a dataset that captures user intentions without the constraints of existing systems. This dataset is also made available for sharing with the research community. In contrast, the Freesound query logs encompass approximately 9 million search requests, providing a comprehensive view of real-world usage patterns. Our findings indicate that survey queries are generally longer than Freesound queries, suggesting users prefer detailed queries when not limited by system constraints. Both datasets predominantly feature keyword-based queries, with few survey participants using full sentences. Key factors influencing survey queries include the primary sound source, intended usage, perceived location, and the number of sound sources. These insights are crucial for developing user-centred, effective text-based audio retrieval systems, enhancing our understanding of user behaviour in sound search contexts.
Heterogeneous sound classification with the Broad Sound Taxonomy and Dataset
Oct 01, 2024



Automatic sound classification has a wide range of applications in machine listening, enabling context-aware sound processing and understanding. This paper explores methodologies for automatically classifying heterogeneous sounds characterized by high intra-class variability. Our study evaluates the classification task using the Broad Sound Taxonomy, a two-level taxonomy comprising 28 classes designed to cover a heterogeneous range of sounds with semantic distinctions tailored for practical user applications. We construct a dataset through manual annotation to ensure accuracy, diverse representation within each class and relevance in real-world scenarios. We compare a variety of both traditional and modern machine learning approaches to establish a baseline for the task of heterogeneous sound classification. We investigate the role of input features, specifically examining how acoustically derived sound representations compare to embeddings extracted with pre-trained deep neural networks that capture both acoustic and semantic information about sounds. Experimental results illustrate that audio embeddings encoding acoustic and semantic information achieve higher accuracy in the classification task. After careful analysis of classification errors, we identify some underlying reasons for failure and propose actions to mitigate them. The paper highlights the need for deeper exploration of all stages of classification, understanding the data and adopting methodologies capable of effectively handling data complexity and generalizing in real-world sound environments.
Evaluating Neural Networks Architectures for Spring Reverb Modelling
Sep 08, 2024Reverberation is a key element in spatial audio perception, historically achieved with the use of analogue devices, such as plate and spring reverb, and in the last decades with digital signal processing techniques that have allowed different approaches for Virtual Analogue Modelling (VAM). The electromechanical functioning of the spring reverb makes it a nonlinear system that is difficult to fully emulate in the digital domain with white-box modelling techniques. In this study, we compare five different neural network architectures, including convolutional and recurrent models, to assess their effectiveness in replicating the characteristics of this audio effect. The evaluation is conducted on two datasets at sampling rates of 16 kHz and 48 kHz. This paper specifically focuses on neural audio architectures that offer parametric control, aiming to advance the boundaries of current black-box modelling techniques in the domain of spring reverberation.
FSD50K: an Open Dataset of Human-Labeled Sound Events
Oct 01, 2020
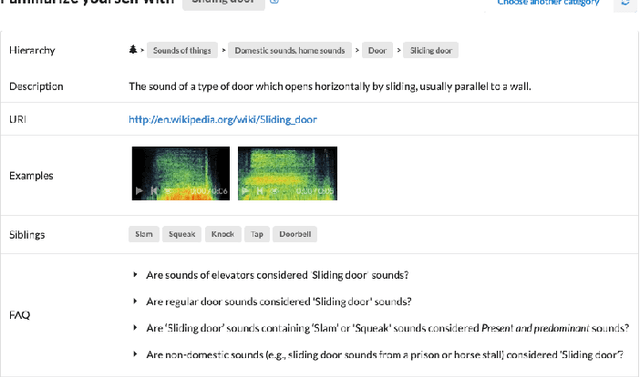
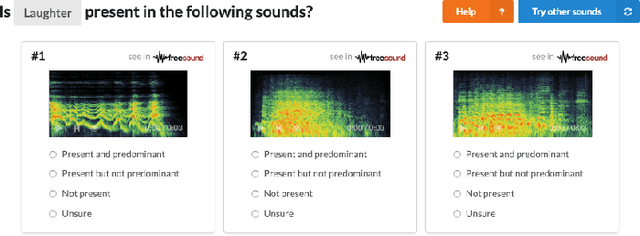
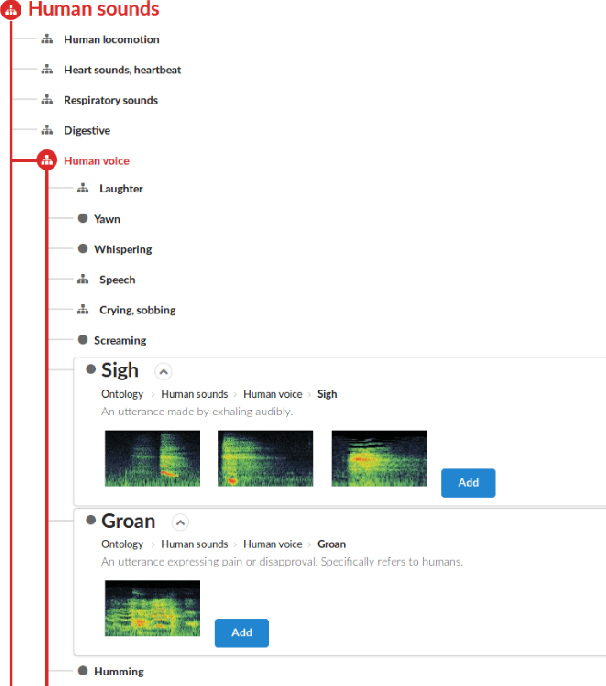
Most existing datasets for sound event recognition (SER) are relatively small and/or domain-specific, with the exception of AudioSet, based on a massive amount of audio tracks from YouTube videos and encompassing over 500 classes of everyday sounds. However, AudioSet is not an open dataset---its release consists of pre-computed audio features (instead of waveforms), which limits the adoption of some SER methods. Downloading the original audio tracks is also problematic due to constituent YouTube videos gradually disappearing and usage rights issues, which casts doubts over the suitability of this resource for systems' benchmarking. To provide an alternative benchmark dataset and thus foster SER research, we introduce FSD50K, an open dataset containing over 51k audio clips totalling over 100h of audio manually labeled using 200 classes drawn from the AudioSet Ontology. The audio clips are licensed under Creative Commons licenses, making the dataset freely distributable (including waveforms). We provide a detailed description of the FSD50K creation process, tailored to the particularities of Freesound data, including challenges encountered and solutions adopted. We include a comprehensive dataset characterization along with discussion of limitations and key factors to allow its audio-informed usage. Finally, we conduct sound event classification experiments to provide baseline systems as well as insight on the main factors to consider when splitting Freesound audio data for SER. Our goal is to develop a dataset to be widely adopted by the community as a new open benchmark for SER research.
Search Result Clustering in Collaborative Sound Collections
Apr 08, 2020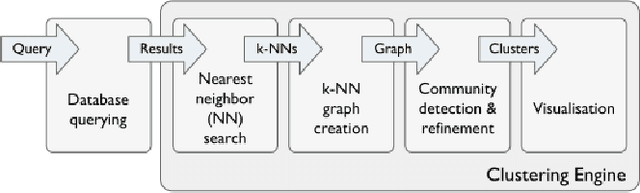

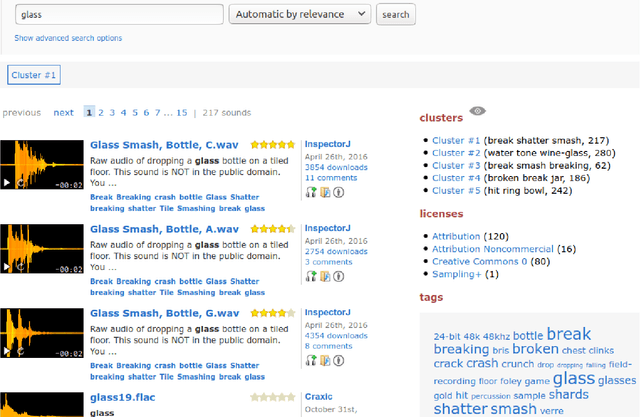
The large size of nowadays' online multimedia databases makes retrieving their content a difficult and time-consuming task. Users of online sound collections typically submit search queries that express a broad intent, often making the system return large and unmanageable result sets. Search Result Clustering is a technique that organises search-result content into coherent groups, which allows users to identify useful subsets in their results. Obtaining coherent and distinctive clusters that can be explored with a suitable interface is crucial for making this technique a useful complement of traditional search engines. In our work, we propose a graph-based approach using audio features for clustering diverse sound collections obtained when querying large online databases. We propose an approach to assess the performance of different features at scale, by taking advantage of the metadata associated with each sound. This analysis is complemented with an evaluation using ground-truth labels from manually annotated datasets. We show that using a confidence measure for discarding inconsistent clusters improves the quality of the partitions. After identifying the most appropriate features for clustering, we conduct an experiment with users performing a sound design task, in order to evaluate our approach and its user interface. A qualitative analysis is carried out including usability questionnaires and semi-structured interviews. This provides us with valuable new insights regarding the features that promote efficient interaction with the clusters.
* 8 pages, 4 figures, ACM ICMR 20
Model-agnostic Approaches to Handling Noisy Labels When Training Sound Event Classifiers
Oct 26, 2019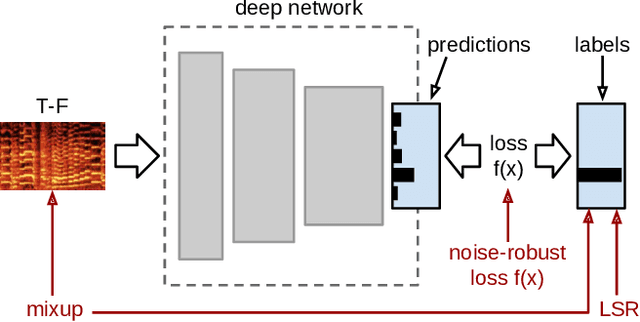

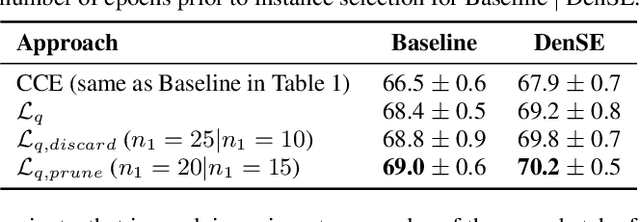
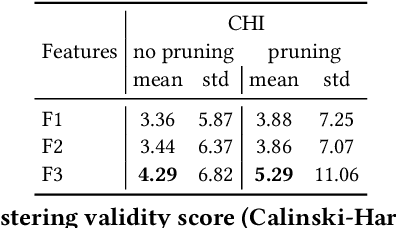
Label noise is emerging as a pressing issue in sound event classification. This arises as we move towards larger datasets that are difficult to annotate manually, but it is even more severe if datasets are collected automatically from online repositories, where labels are inferred through automated heuristics applied to the audio content or metadata. While learning from noisy labels has been an active area of research in computer vision, it has received little attention in sound event classification. Most recent computer vision approaches against label noise are relatively complex, requiring complex networks or extra data resources. In this work, we evaluate simple and efficient model-agnostic approaches to handling noisy labels when training sound event classifiers, namely label smoothing regularization, mixup and noise-robust loss functions. The main advantage of these methods is that they can be easily incorporated to existing deep learning pipelines without need for network modifications or extra resources. We report results from experiments conducted with the FSDnoisy18k dataset. We show that these simple methods can be effective in mitigating the effect of label noise, providing up to 2.5\% of accuracy boost when incorporated to two different CNNs, while requiring minimal intervention and computational overhead.
Audio tagging with noisy labels and minimal supervision
Jul 14, 2019
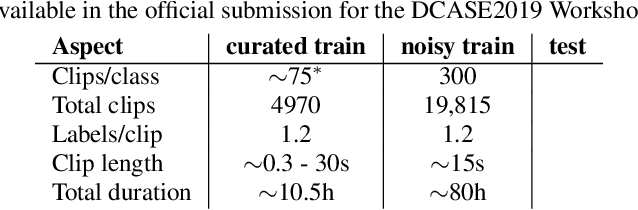


This paper introduces Task 2 of the DCASE2019 Challenge, titled "Audio tagging with noisy labels and minimal supervision". This task was hosted on the Kaggle platform as "Freesound Audio Tagging 2019". The task evaluates systems for multi-label audio tagging using a large set of noisy-labeled data, and a much smaller set of manually-labeled data, under a large vocabulary setting of 80 everyday sound classes. In addition, the proposed dataset poses an acoustic mismatch problem between the noisy train set and the test set due to the fact that they come from different web audio sources. This can correspond to a realistic scenario given by the difficulty in gathering large amounts of manually labeled data. We present the task setup, the FSDKaggle2019 dataset prepared for this scientific evaluation, and a baseline system consisting of a convolutional neural network. All these resources are freely available.