 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Training Strategies Using Contrastive Learning and Playlist Information for Music Classification and Similarity
Apr 24, 2023



In this work, we investigate an approach that relies on contrastive learning and music metadata as a weak source of supervision to train music representation models. Recent studies show that contrastive learning can be used with editorial metadata (e.g., artist or album name) to learn audio representations that are useful for different classification tasks. In this paper, we extend this idea to using playlist data as a source of music similarity information and investigate three approaches to generate anchor and positive track pairs. We evaluate these approaches by fine-tuning the pre-trained models for music multi-label classification tasks (genre, mood, and instrument tagging) and music similarity. We find that creating anchor and positive track pairs by relying on co-occurrences in playlists provides better music similarity and competitive classification results compared to choosing tracks from the same artist as in previous works. Additionally, our best pre-training approach based on playlists provides superior classification performance for most datasets.
Evaluating Off-the-Shelf Machine Listening and Natural Language Models for Automated Audio Captioning
Oct 14, 2021
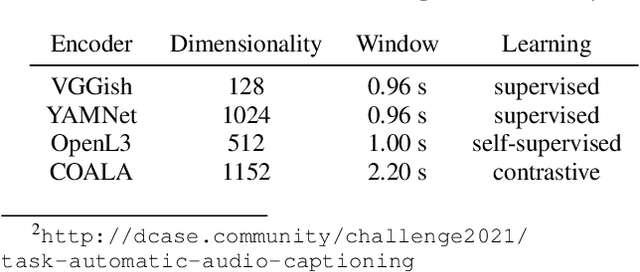
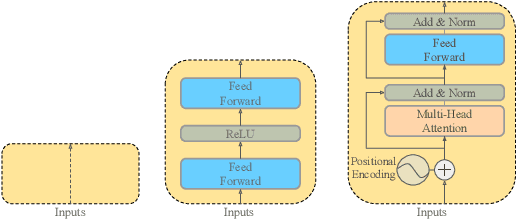
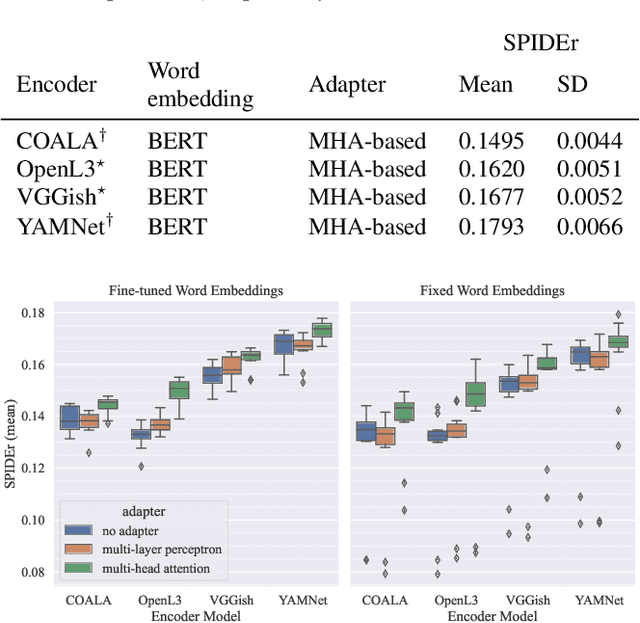
Automated audio captioning (AAC) is the task of automatically generating textual descriptions for general audio signals. A captioning system has to identify various information from the input signal and express it with natural language. Existing works mainly focus on investigating new methods and try to improve their performance measured on existing datasets. Having attracted attention only recently, very few works on AAC study the performance of existing pre-trained audio and natural language processing resources. In this paper, we evaluate the performance of off-the-shelf models with a Transformer-based captioning approach. We utilize the freely available Clotho dataset to compare four different pre-trained machine listening models, four word embedding models, and their combinations in many different settings. Our evaluation suggests that YAMNet combined with BERT embeddings produces the best captions. Moreover, in general, fine-tuning pre-trained word embeddings can lead to better performance. Finally, we show that sequences of audio embeddings can be processed using a Transformer encoder to produce higher-quality captions.
Enriched Music Representations with Multiple Cross-modal Contrastive Learning
Apr 01, 2021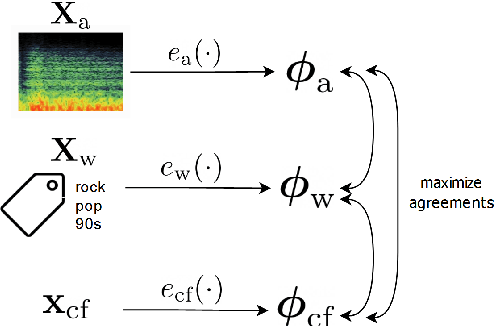
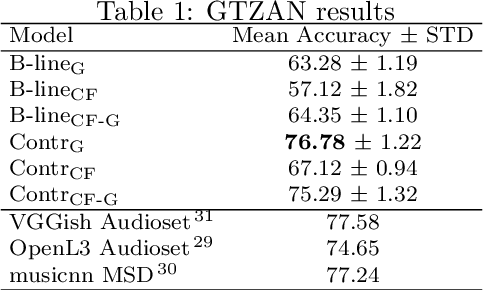
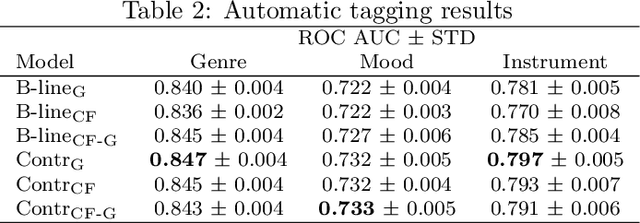
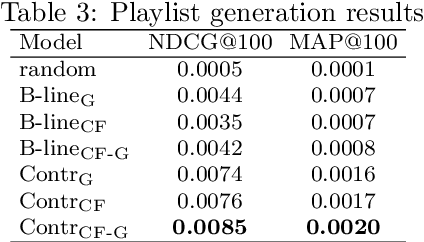
Modeling various aspects that make a music piece unique is a challenging task, requiring the combination of multiple sources of information. Deep learning is commonly used to obtain representations using various sources of information, such as the audio, interactions between users and songs, or associated genre metadata. Recently, contrastive learning has led to representations that generalize better compared to traditional supervised methods. In this paper, we present a novel approach that combines multiple types of information related to music using cross-modal contrastive learning, allowing us to learn an audio feature from heterogeneous data simultaneously. We align the latent representations obtained from playlists-track interactions, genre metadata, and the tracks' audio, by maximizing the agreement between these modality representations using a contrastive loss. We evaluate our approach in three tasks, namely, genre classification, playlist continuation and automatic tagging. We compare the performances with a baseline audio-based CNN trained to predict these modalities. We also study the importance of including multiple sources of information when training our embedding model. The results suggest that the proposed method outperforms the baseline in all the three downstream tasks and achieves comparable performance to the state-of-the-art.
Learning Contextual Tag Embeddings for Cross-Modal Alignment of Audio and Tags
Oct 27, 2020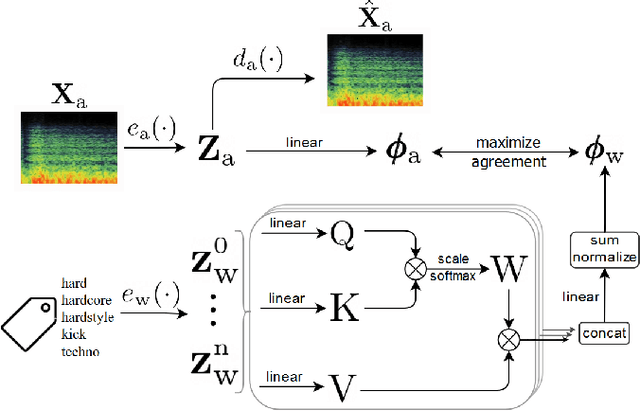
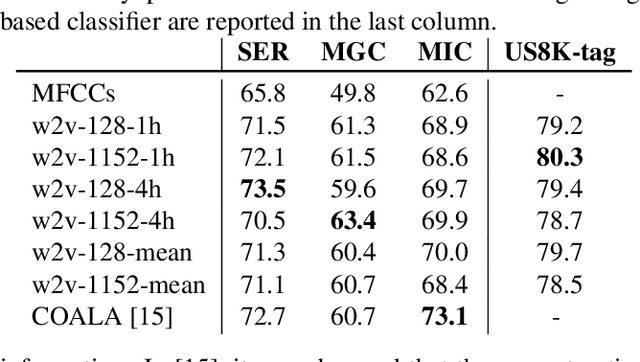
Self-supervised audio representation learning offers an attractive alternative for obtaining generic audio embeddings, capable to be employed into various downstream tasks. Published approaches that consider both audio and words/tags associated with audio do not employ text processing models that are capable to generalize to tags unknown during training. In this work we propose a method for learning audio representations using an audio autoencoder (AAE), a general word embeddings model (WEM), and a multi-head self-attention (MHA) mechanism. MHA attends on the output of the WEM, providing a contextualized representation of the tags associated with the audio, and we align the output of MHA with the output of the encoder of AAE using a contrastive loss. We jointly optimize AAE and MHA and we evaluate the audio representations (i.e. the output of the encoder of AAE) by utilizing them in three different downstream tasks, namely sound, music genre, and music instrument classification. Our results show that employing multi-head self-attention with multiple heads in the tag-based network can induce better learned audio representations.
FSD50K: an Open Dataset of Human-Labeled Sound Events
Oct 01, 2020
Most existing datasets for sound event recognition (SER) are relatively small and/or domain-specific, with the exception of AudioSet, based on a massive amount of audio tracks from YouTube videos and encompassing over 500 classes of everyday sounds. However, AudioSet is not an open dataset---its release consists of pre-computed audio features (instead of waveforms), which limits the adoption of some SER methods. Downloading the original audio tracks is also problematic due to constituent YouTube videos gradually disappearing and usage rights issues, which casts doubts over the suitability of this resource for systems' benchmarking. To provide an alternative benchmark dataset and thus foster SER research, we introduce FSD50K, an open dataset containing over 51k audio clips totalling over 100h of audio manually labeled using 200 classes drawn from the AudioSet Ontology. The audio clips are licensed under Creative Commons licenses, making the dataset freely distributable (including waveforms). We provide a detailed description of the FSD50K creation process, tailored to the particularities of Freesound data, including challenges encountered and solutions adopted. We include a comprehensive dataset characterization along with discussion of limitations and key factors to allow its audio-informed usage. Finally, we conduct sound event classification experiments to provide baseline systems as well as insight on the main factors to consider when splitting Freesound audio data for SER. Our goal is to develop a dataset to be widely adopted by the community as a new open benchmark for SER research.
COALA: Co-Aligned Autoencoders for Learning Semantically Enriched Audio Representations
Jul 08, 2020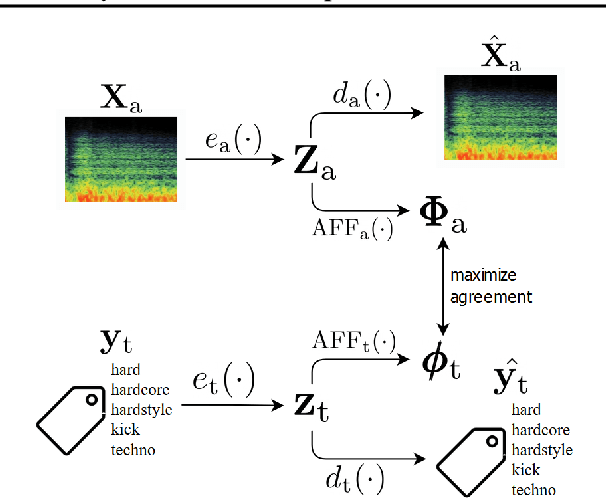

Audio representation learning based on deep neural networks (DNNs) emerged as an alternative approach to hand-crafted features. For achieving high performance, DNNs often need a large amount of annotated data which can be difficult and costly to obtain. In this paper, we propose a method for learning audio representations, aligning the learned latent representations of audio and associated tags. Aligning is done by maximizing the agreement of the latent representations of audio and tags, using a contrastive loss. The result is an audio embedding model which reflects acoustic and semantic characteristics of sounds. We evaluate the quality of our embedding model, measuring its performance as a feature extractor on three different tasks (namely, sound event recognition, and music genre and musical instrument classification), and investigate what type of characteristics the model captures. Our results are promising, sometimes in par with the state-of-the-art in the considered tasks and the embeddings produced with our method are well correlated with some acoustic descriptors.
Search Result Clustering in Collaborative Sound Collections
Apr 08, 2020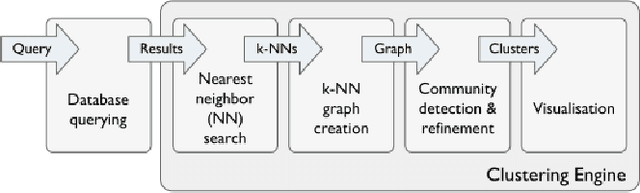

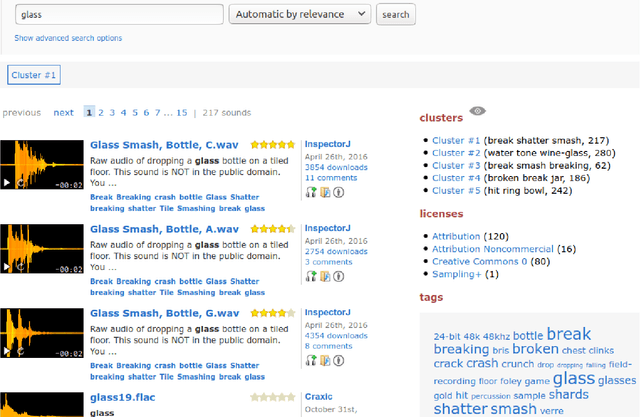
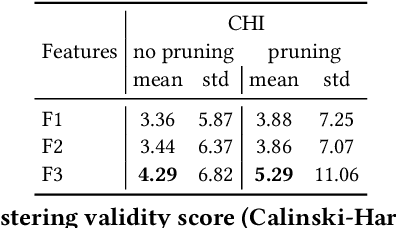
The large size of nowadays' online multimedia databases makes retrieving their content a difficult and time-consuming task. Users of online sound collections typically submit search queries that express a broad intent, often making the system return large and unmanageable result sets. Search Result Clustering is a technique that organises search-result content into coherent groups, which allows users to identify useful subsets in their results. Obtaining coherent and distinctive clusters that can be explored with a suitable interface is crucial for making this technique a useful complement of traditional search engines. In our work, we propose a graph-based approach using audio features for clustering diverse sound collections obtained when querying large online databases. We propose an approach to assess the performance of different features at scale, by taking advantage of the metadata associated with each sound. This analysis is complemented with an evaluation using ground-truth labels from manually annotated datasets. We show that using a confidence measure for discarding inconsistent clusters improves the quality of the partitions. After identifying the most appropriate features for clustering, we conduct an experiment with users performing a sound design task, in order to evaluate our approach and its user interface. A qualitative analysis is carried out including usability questionnaires and semi-structured interviews. This provides us with valuable new insights regarding the features that promote efficient interaction with the clusters.
* 8 pages, 4 figures, ACM ICMR 20
Neural Percussive Synthesis Parameterised by High-Level Timbral Features
Nov 25, 2019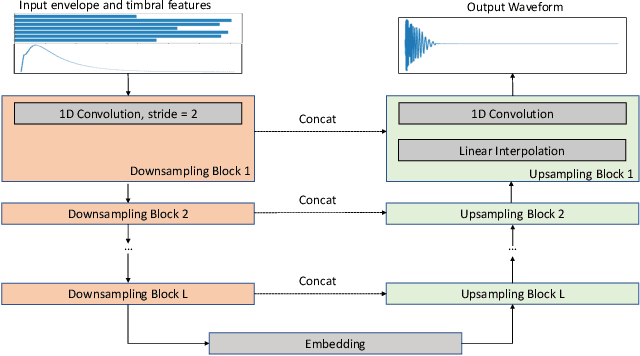
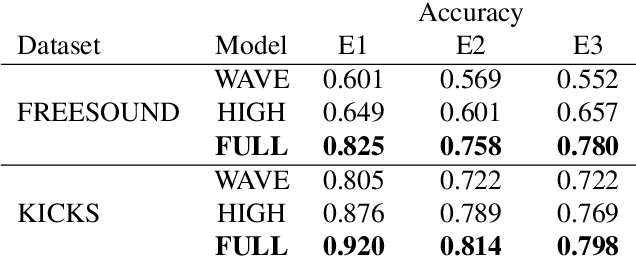
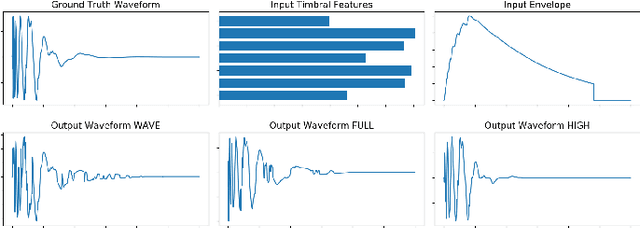
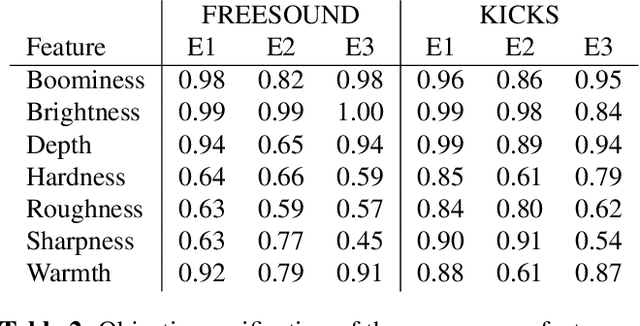
We present a deep neural network-based methodology for synthesising percussive sounds with control over high-level timbral characteristics of the sounds. This approach allows for intuitive control of a synthesizer, enabling the user to shape sounds without extensive knowledge of signal processing. We use a feedforward convolutional neural network-based architecture, which is able to map input parameters to the corresponding waveform. We propose two datasets to evaluate our approach on both a restrictive context, and in one covering a broader spectrum of sounds. The timbral features used as parameters are taken from recent literature in signal processing. We also use these features for evaluation and validation of the presented model, to ensure that changing the input parameters produces a congruent waveform with the desired characteristics. Finally, we evaluate the quality of the output sound using a subjective listening test. We provide sound examples and the system's source code for reproducibility.
Learning Sound Event Classifiers from Web Audio with Noisy Labels
Jan 04, 2019



As sound event classification moves towards larger datasets, issues of label noise become inevitable. Web sites can supply large volumes of user-contributed audio and metadata, but inferring labels from this metadata introduces errors due to unreliable inputs, and limitations in the mapping. There is, however, little research into the impact of these errors. To foster the investigation of label noise in sound event classification we present FSDnoisy18k, a dataset containing 42.5 hours of audio across 20 sound classes, including a small amount of manually-labeled data and a larger quantity of real-world noisy data. We characterize the label noise empirically, and provide a CNN baseline system. Experiments suggest that training with large amounts of noisy data can outperform training with smaller amounts of carefully-labeled data. We also show that noise-robust loss functions can be effective in improving performance in presence of corrupted labels.
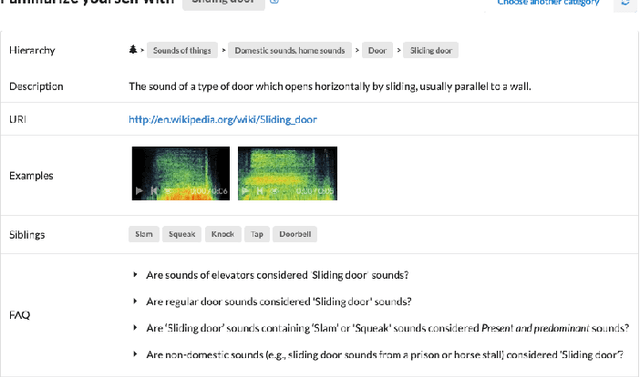
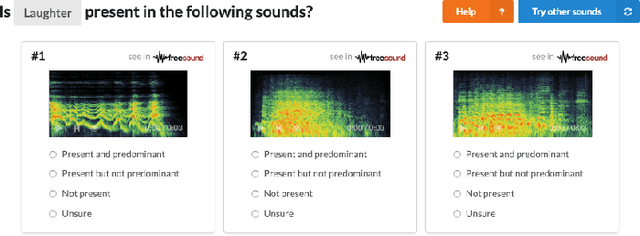
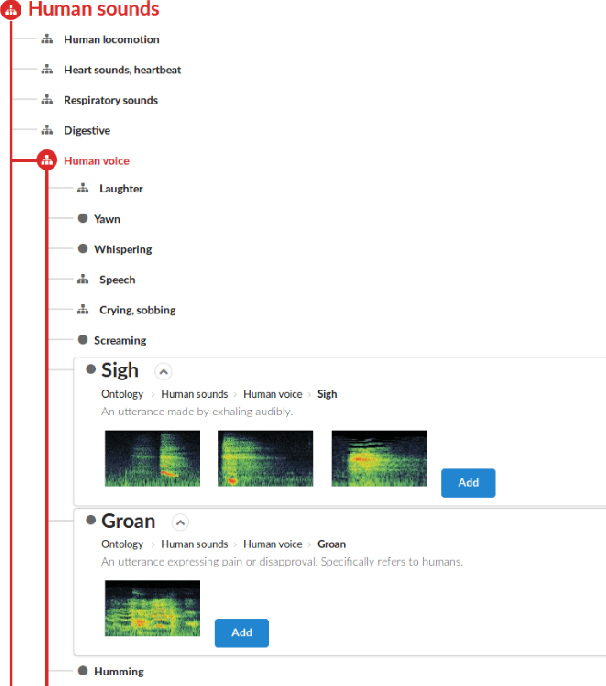
Facilitating the Manual Annotation of Sounds When Using Large Taxonomies
Nov 21, 2018

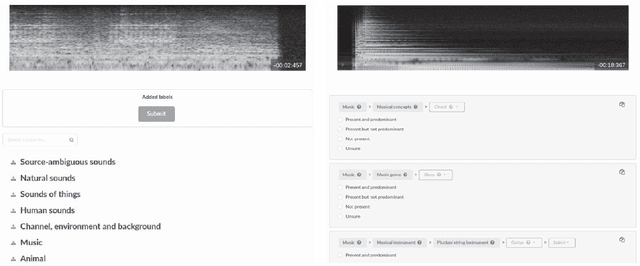
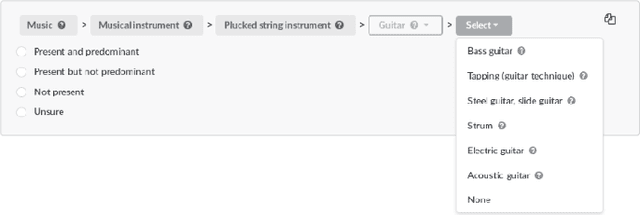
Properly annotated multimedia content is crucial for supporting advances in many Information Retrieval applications. It enables, for instance, the development of automatic tools for the annotation of large and diverse multimedia collections. In the context of everyday sounds and online collections, the content to describe is very diverse and involves many different types of concepts, often organised in large hierarchical structures called taxonomies. This makes the task of manually annotating content arduous. In this paper, we present our user-centered development of two tools for the manual annotation of audio content from a wide range of types. We conducted a preliminary evaluation of functional prototypes involving real users. The goal is to evaluate them in a real context, engage in discussions with users, and inspire new ideas. A qualitative analysis was carried out including usability questionnaires and semi-structured interviews. This revealed interesting aspects to consider when developing tools for the manual annotation of audio content with labels drawn from large hierarchical taxonomies.
* 5 pages, 5 figures, IEEE FRUCT International Workshop on Semantic Audio and the Internet of Things