 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriched Music Representations with Multiple Cross-modal Contrastive Learning
Apr 01, 2021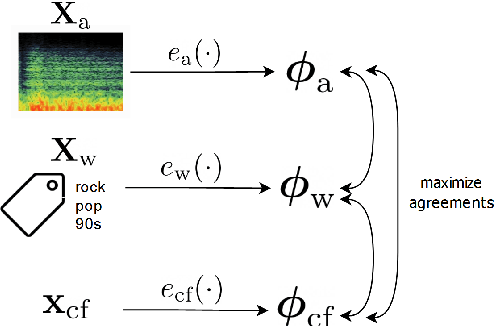
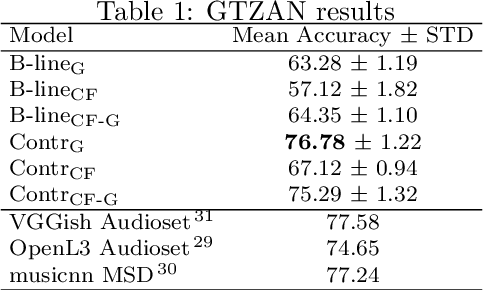
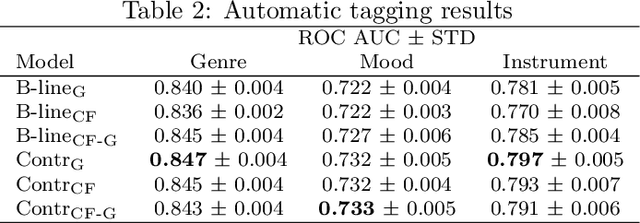
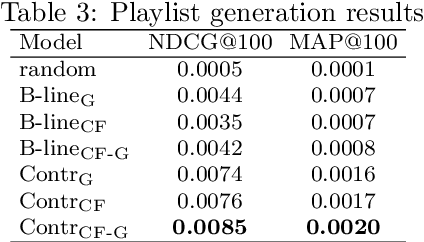
Modeling various aspects that make a music piece unique is a challenging task, requiring the combination of multiple sources of information. Deep learning is commonly used to obtain representations using various sources of information, such as the audio, interactions between users and songs, or associated genre metadata. Recently, contrastive learning has led to representations that generalize better compared to traditional supervised methods. In this paper, we present a novel approach that combines multiple types of information related to music using cross-modal contrastive learning, allowing us to learn an audio feature from heterogeneous data simultaneously. We align the latent representations obtained from playlists-track interactions, genre metadata, and the tracks' audio, by maximizing the agreement between these modality representations using a contrastive loss. We evaluate our approach in three tasks, namely, genre classification, playlist continuation and automatic tagging. We compare the performances with a baseline audio-based CNN trained to predict these modalities. We also study the importance of including multiple sources of information when training our embedding model. The results suggest that the proposed method outperforms the baseline in all the three downstream tasks and achieves comparable performance to the state-of-the-art.
Melon Playlist Dataset: a public dataset for audio-based playlist generation and music tagging
Jan 30, 2021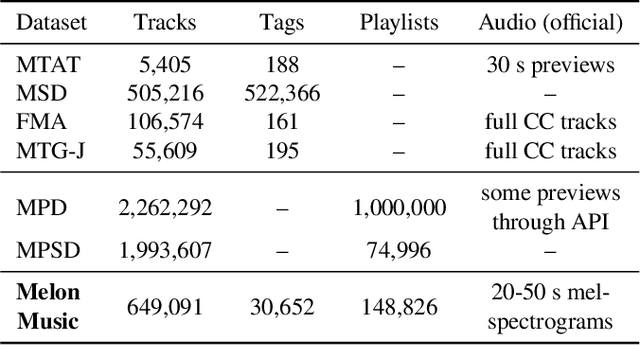
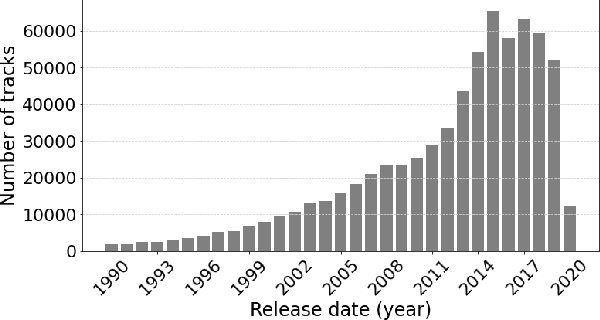
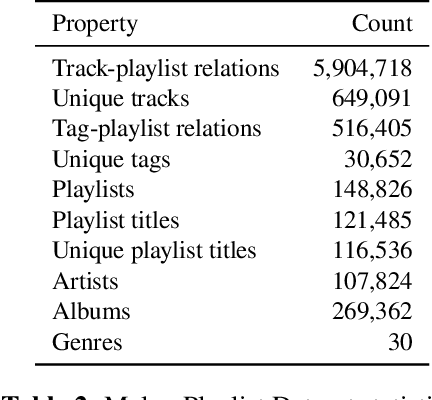
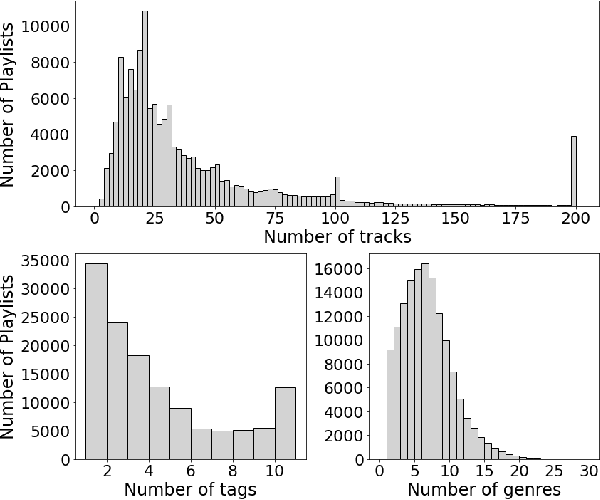
One of the main limitations in the field of audio signal processing is the lack of large public datasets with audio representations and high-quality annotations due to restrictions of copyrighted commercial music. We present Melon Playlist Dataset, a public dataset of mel-spectrograms for 649,091tracks and 148,826 associated playlists annotated by 30,652 different tags. All the data is gathered from Melon, a popular Korean streaming service. The dataset is suitable for music information retrieval tasks, in particular, auto-tagging and automatic playlist continuation. Even though the latter can be addressed by collaborative filtering approaches, audio provides opportunities for research on track suggestions and building systems resistant to the cold-start problem, for which we provide a baseline. Moreover, the playlists and the annotations included in the Melon Playlist Dataset make it suitable for metric learning and representation learning.