 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Cross-modal Artist Retrieval
Aug 12, 2023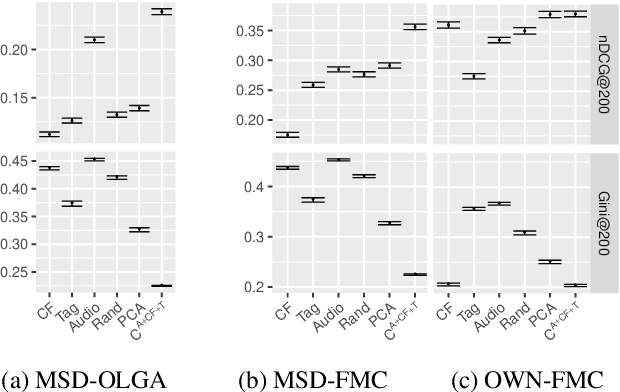



Music retrieval and recommendation applications often rely on content features encoded as embeddings, which provide vector representations of items in a music dataset. Numerous complementary embeddings can be derived from processing items originally represented in several modalities, e.g., audio signals, user interaction data, or editorial data. However, data of any given modality might not be available for all items in any music dataset. In this work, we propose a method based on contrastive learning to combine embeddings from multiple modalities and explore the impact of the presence or absence of embeddings from diverse modalities in an artist similarity task. Experiments on two datasets suggest that our contrastive method outperforms single-modality embeddings and baseline algorithms for combining modalities, both in terms of artist retrieval accuracy and coverage. Improvements with respect to other methods are particularly significant for less popular query artists. We demonstrate our method successfully combines complementary information from diverse modalities, and is more robust to missing modality data (i.e., it better handles the retrieval of artists with different modality embeddings than the query artist's).
Commonality in Recommender Systems: Evaluating Recommender Systems to Enhance Cultural Citizenship
Feb 23, 2023
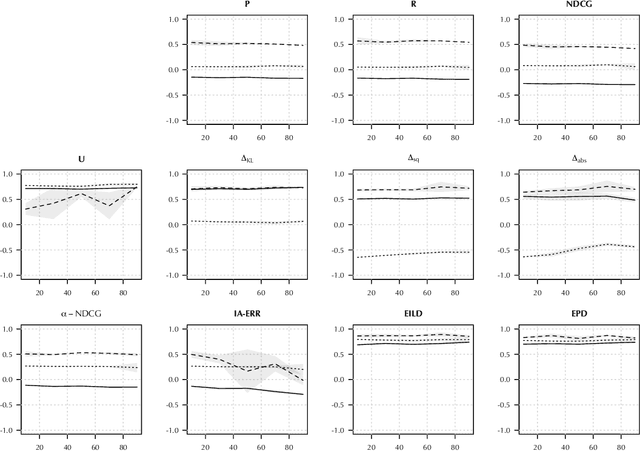

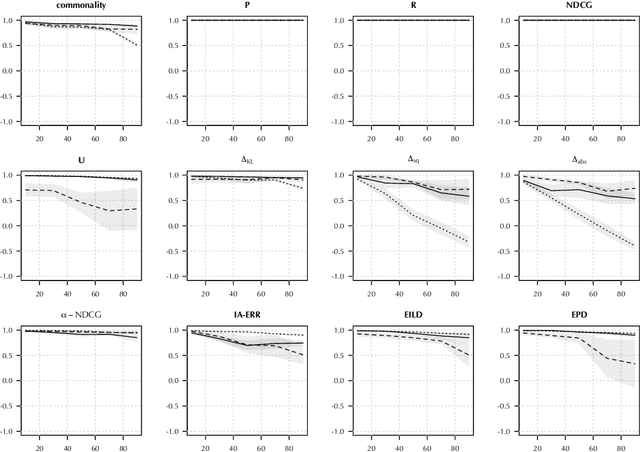
Recommender systems have become the dominant means of curating cultural content, significantly influencing individual cultural experience. Since recommender systems tend to optimize for personalized user experience, they can overlook impacts on cultural experience in the aggregate. After demonstrating that existing metrics do not center culture, we introduce a new metric, commonality, that measures the degree to which recommendations familiarize a given user population with specified categories of cultural content. We developed commonality through an interdisciplinary dialogue between researchers in computer science and the social sciences and humanities. With reference to principles underpinning public service media systems in democratic societies, we identify universality of address and content diversity in the service of strengthening cultural citizenship as particularly relevant goals for recommender systems delivering cultural content. We develop commonality as a measure of recommender system alignment with the promotion of content toward a shared cultural experience across a population of users. We empirically compare the performance of recommendation algorithms using commonality with existing metrics, demonstrating that commonality captures a novel property of system behavior complementary to existing metrics. Alongside existing fairness and diversity metrics, commonality contributes to a growing body of scholarship developing `public good' rationales for machine learning systems.
Measuring Commonality in Recommendation of Cultural Content: Recommender Systems to Enhance Cultural Citizenship
Aug 02, 2022
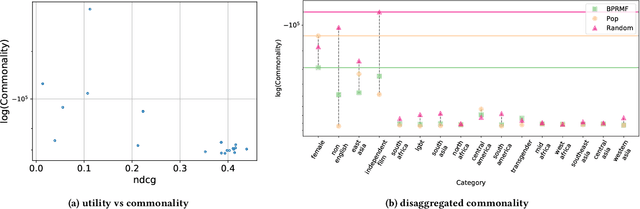
Recommender systems have become the dominant means of curating cultural content, significantly influencing the nature of individual cultural experience. While the majority of research on recommender systems optimizes for personalized user experience, this paradigm does not capture the ways that recommender systems impact cultural experience in the aggregate, across populations of users. Although existing novelty, diversity, and fairness studies probe how systems relate to the broader social role of cultural content, they do not adequately center culture as a core concept and challenge. In this work, we introduce commonality as a new measure that reflects the degree to which recommendations familiarize a given user population with specified categories of cultural content. Our proposed commonality metric responds to a set of arguments developed through an interdisciplinary dialogue between researchers in computer science and the social sciences and humanities. With reference to principles underpinning non-profit, public service media systems in democratic societies, we identify universality of address and content diversity in the service of strengthening cultural citizenship as particularly relevant goals for recommender systems delivering cultural content. Taking diversity in movie recommendation as a case study in enhancing pluralistic cultural experience, we empirically compare systems' performance using commonality and existing utility, diversity, and fairness metrics. Our results demonstrate that commonality captures a property of system behavior complementary to existing metrics and suggest the need for alternative, non-personalized interventions in recommender systems oriented to strengthening cultural citizenship across populations of users. In this way, commonality contributes to a growing body of scholarship developing 'public good' rationales for digital media and ML systems.
Offline Retrieval Evaluation Without Evaluation Metrics
Apr 25, 2022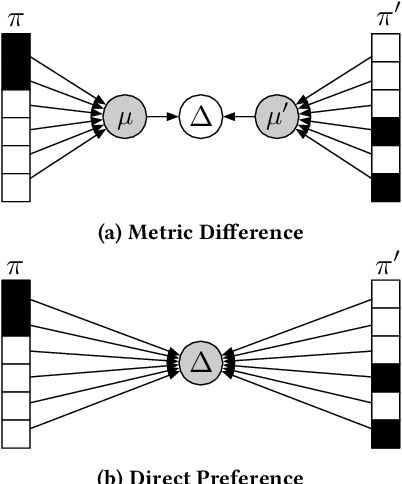
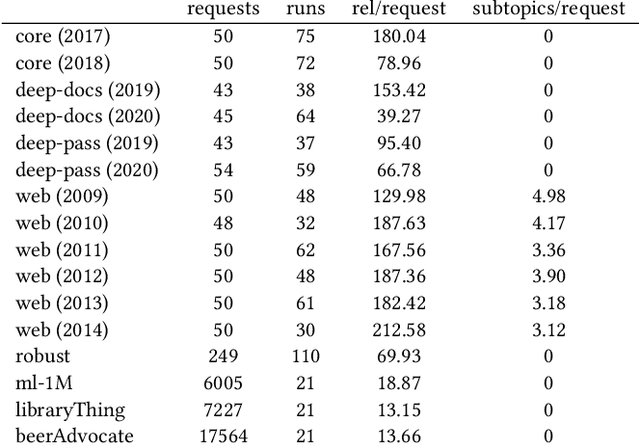
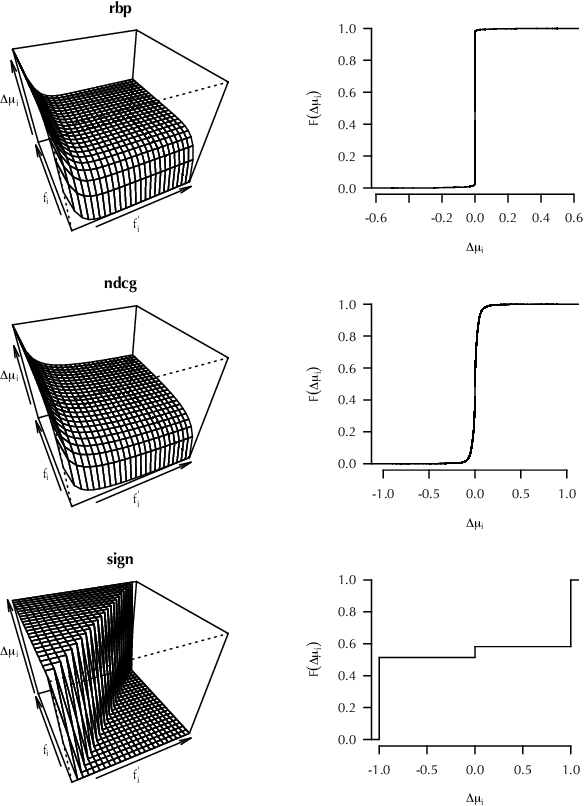
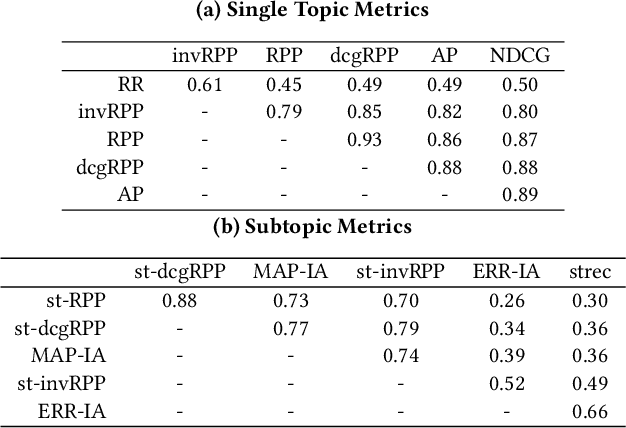
Offline evaluation of information retrieval and recommendation has traditionally focused on distilling the quality of a ranking into a scalar metric such as average precision or normalized discounted cumulative gain. We can use this metric to compare the performance of multiple systems for the same request. Although evaluation metrics provide a convenient summary of system performance, they also collapse subtle differences across users into a single number and can carry assumptions about user behavior and utility not supported across retrieval scenarios. We propose recall-paired preference (RPP), a metric-free evaluation method based on directly computing a preference between ranked lists. RPP simulates multiple user subpopulations per query and compares systems across these pseudo-populations. Our results across multiple search and recommendation tasks demonstrate that RPP substantially improves discriminative power while correlating well with existing metrics and being equally robust to incomplete data.
Improving Sound Event Classification by Increasing Shift Invariance in Convolutional Neural Networks
Jul 22, 2021
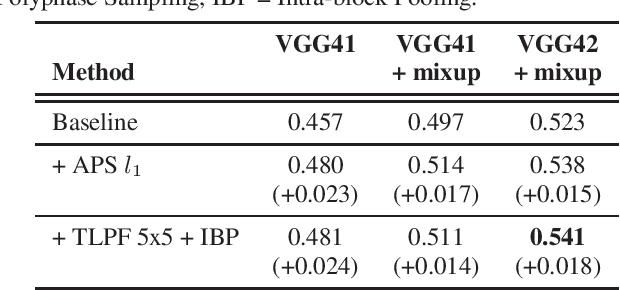

Recent studies have put into question the commonly assumed shift invariance property of convolutional networks, showing that small shifts in the input can affect the output predictions substantially. In this paper, we analyze the benefits of addressing lack of shift invariance in CNN-based sound event classification. Specifically, we evaluate two pooling methods to improve shift invariance in CNNs, based on low-pass filtering and adaptive sampling of incoming feature maps. These methods are implemented via small architectural modifications inserted into the pooling layers of CNNs. We evaluate the effect of these architectural changes on the FSD50K dataset using models of different capacity and in presence of strong regularization. We show that these modifications consistently improve sound event classification in all cases considered. We also demonstrate empirically that the proposed pooling methods increase shift invariance in the network, making it more robust against time/frequency shifts in input spectrograms. This is achieved by adding a negligible amount of trainable parameters, which makes these methods an appealing alternative to conventional pooling layers. The outcome is a new state-of-the-art mAP of 0.541 on the FSD50K classification benchmark.
Enriched Music Representations with Multiple Cross-modal Contrastive Learning
Apr 01, 2021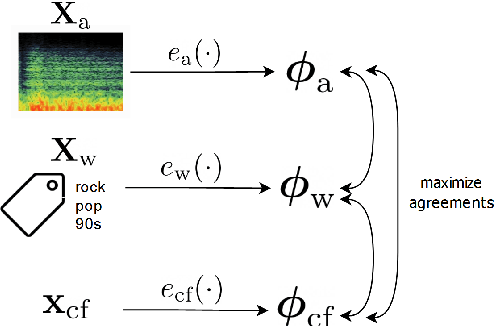
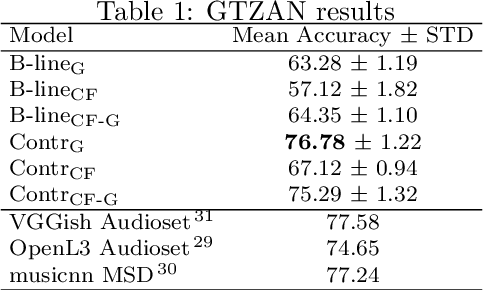
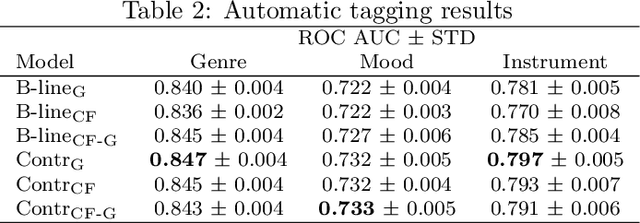
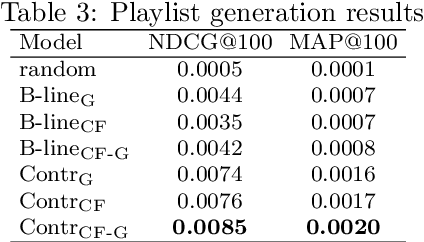
Modeling various aspects that make a music piece unique is a challenging task, requiring the combination of multiple sources of information. Deep learning is commonly used to obtain representations using various sources of information, such as the audio, interactions between users and songs, or associated genre metadata. Recently, contrastive learning has led to representations that generalize better compared to traditional supervised methods. In this paper, we present a novel approach that combines multiple types of information related to music using cross-modal contrastive learning, allowing us to learn an audio feature from heterogeneous data simultaneously. We align the latent representations obtained from playlists-track interactions, genre metadata, and the tracks' audio, by maximizing the agreement between these modality representations using a contrastive loss. We evaluate our approach in three tasks, namely, genre classification, playlist continuation and automatic tagging. We compare the performances with a baseline audio-based CNN trained to predict these modalities. We also study the importance of including multiple sources of information when training our embedding model. The results suggest that the proposed method outperforms the baseline in all the three downstream tasks and achieves comparable performance to the state-of-the-art.
Melon Playlist Dataset: a public dataset for audio-based playlist generation and music tagging
Jan 30, 2021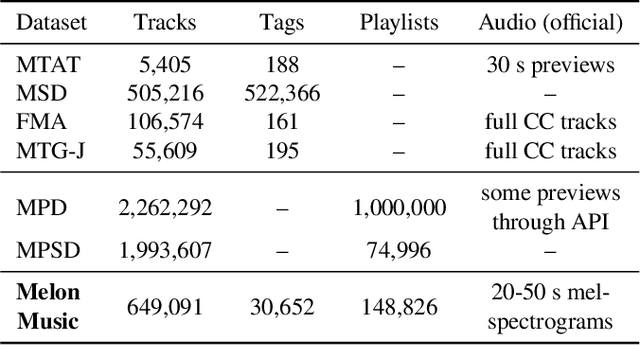
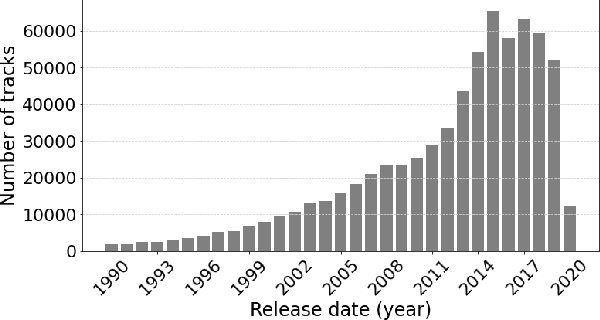
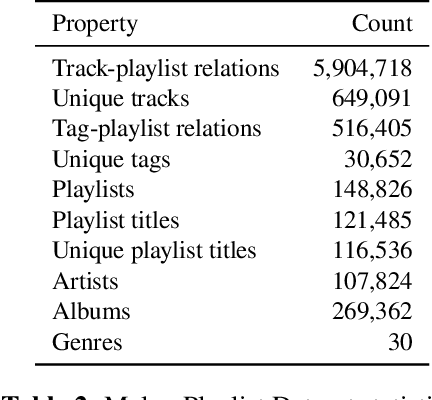
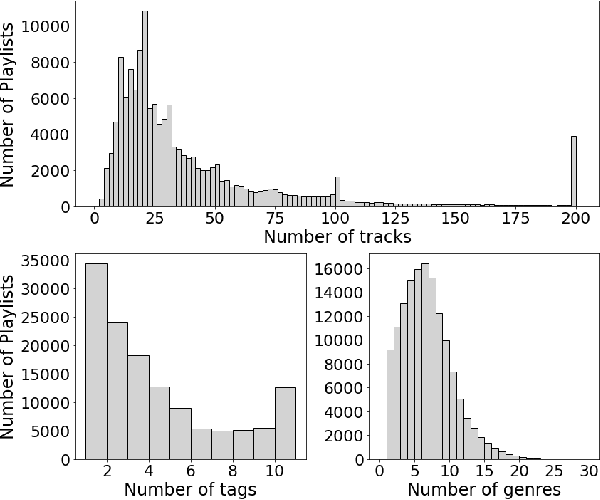
One of the main limitations in the field of audio signal processing is the lack of large public datasets with audio representations and high-quality annotations due to restrictions of copyrighted commercial music. We present Melon Playlist Dataset, a public dataset of mel-spectrograms for 649,091tracks and 148,826 associated playlists annotated by 30,652 different tags. All the data is gathered from Melon, a popular Korean streaming service. The dataset is suitable for music information retrieval tasks, in particular, auto-tagging and automatic playlist continuation. Even though the latter can be addressed by collaborative filtering approaches, audio provides opportunities for research on track suggestions and building systems resistant to the cold-start problem, for which we provide a baseline. Moreover, the playlists and the annotations included in the Melon Playlist Dataset make it suitable for metric learning and representation learning.