 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumMusQA: A Human-written Music Understanding QA Benchmark Dataset
Mar 29, 2026The evaluation of music understanding in Large Audio-Language Models (LALMs) requires a rigorously defined benchmark that truly tests whether models can perceive and interpret music, a standard that current data methodologies frequently fail to meet. This paper introduces a meticulously structured approach to music evaluation, proposing a new dataset of 320 hand-written questions curated and validated by experts with musical training, arguing that such focused, manual curation is superior for probing complex audio comprehension. To demonstrate the use of the dataset, we benchmark six state-of-the-art LALMs and additionally test their robustness to uni-modal shortcuts.
* Dataset available at https://doi.org/10.5281/zenodo.18462523
Benchmarking Music Autotagging with MGPHot Expert Annotations vs. Generic Tag Datasets
Sep 08, 2025



Music autotagging aims to automatically assign descriptive tags, such as genre, mood, or instrumentation, to audio recordings. Due to its challenges, diversity of semantic descriptions, and practical value in various applications, it has become a common downstream task for evaluating the performance of general-purpose music representations learned from audio data. We introduce a new benchmarking dataset based on the recently published MGPHot dataset, which includes expert musicological annotations, allowing for additional insights and comparisons with results obtained on common generic tag datasets. While MGPHot annotations have been shown to be useful for computational musicology, the original dataset neither includes audio nor provides evaluation setups for its use as a standardized autotagging benchmark. To address this, we provide a curated set of YouTube URLs with retrievable audio, and propose a train/val/test split for standardized evaluation, and precomputed representations for seven state-of-the-art models. Using these resources, we evaluated these models in MGPHot and standard reference tag datasets, highlighting key differences between expert and generic tag annotations. Altogether, our contributions provide a more advanced benchmarking framework for future research in music understanding.
Supervised contrastive learning from weakly-labeled audio segments for musical version matching
Feb 24, 2025



Detecting musical versions (different renditions of the same piece) is a challenging task with important applications. Because of the ground truth nature, existing approaches match musical versions at the track level (e.g., whole song). However, most applications require to match them at the segment level (e.g., 20s chunks). In addition, existing approaches resort to classification and triplet losses, disregarding more recent losses that could bring meaningful improvements. In this paper, we propose a method to learn from weakly annotated segments, together with a contrastive loss variant that outperforms well-studied alternatives. The former is based on pairwise segment distance reductions, while the latter modifies an existing loss following decoupling, hyper-parameter, and geometric considerations. With these two elements, we do not only achieve state-of-the-art results in the standard track-level evaluation, but we also obtain a breakthrough performance in a segment-level evaluation. We believe that, due to the generality of the challenges addressed here, the proposed methods may find utility in domains beyond audio or musical version matching.
Discogs-VI: A Musical Version Identification Dataset Based on Public Editorial Metadata
Oct 22, 2024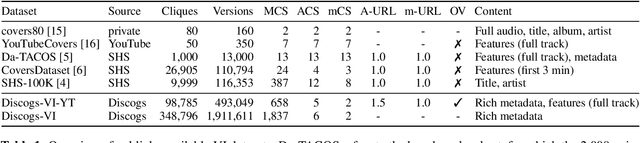
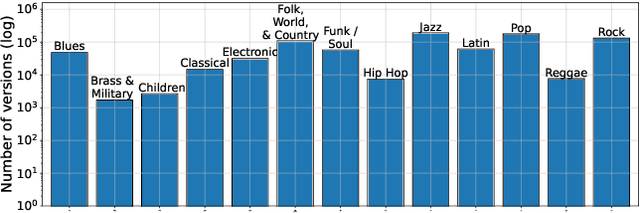
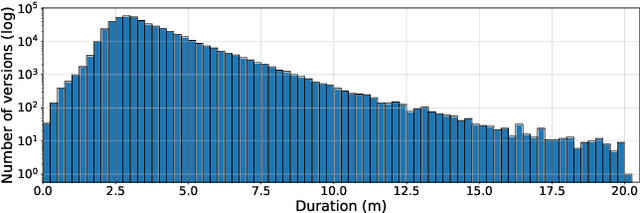
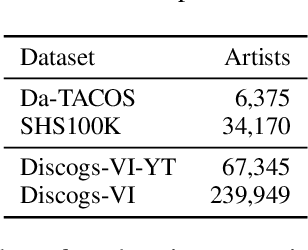
Current version identification (VI) datasets often lack sufficient size and musical diversity to train robust neural networks (NNs). Additionally, their non-representative clique size distributions prevent realistic system evaluations. To address these challenges, we explore the untapped potential of the rich editorial metadata in the Discogs music database and create a large dataset of musical versions containing about 1,900,000 versions across 348,000 cliques. Utilizing a high-precision search algorithm, we map this dataset to official music uploads on YouTube, resulting in a dataset of approximately 493,000 versions across 98,000 cliques. This dataset offers over nine times the number of cliques and over four times the number of versions than existing datasets. We demonstrate the utility of our dataset by training a baseline NN without extensive model complexities or data augmentations, which achieves competitive results on the SHS100K and Da-TACOS datasets. Our dataset, along with the tools used for its creation, the extracted audio features, and a trained model, are all publicly available online.
MuChoMusic: Evaluating Music Understanding in Multimodal Audio-Language Models
Aug 02, 2024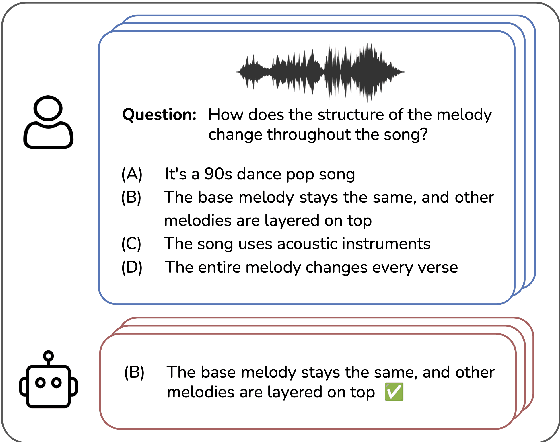
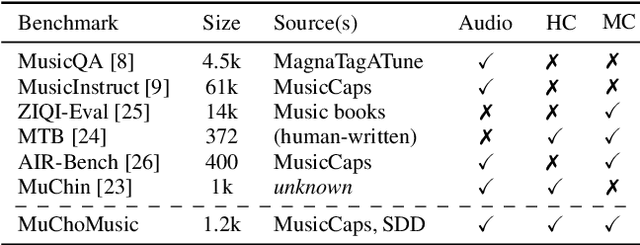
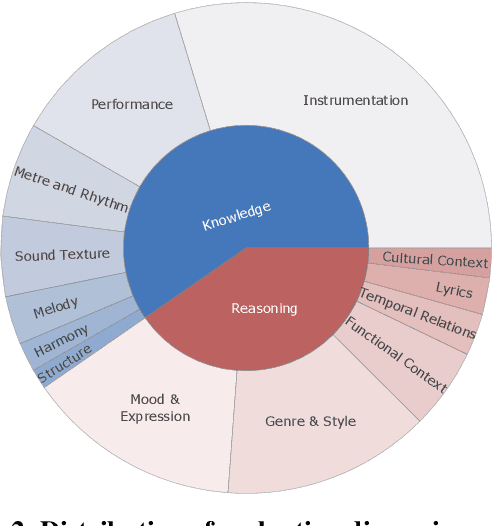

Multimodal models that jointly process audio and language hold great promise in audio understanding and are increasingly being adopted in the music domain. By allowing users to query via text and obtain information about a given audio input, these models have the potential to enable a variety of music understanding tasks via language-based interfaces. However, their evaluation poses considerable challenges, and it remains unclear how to effectively assess their ability to correctly interpret music-related inputs with current methods. Motivated by this, we introduce MuChoMusic, a benchmark for evaluating music understanding in multimodal language models focused on audio. MuChoMusic comprises 1,187 multiple-choice questions, all validated by human annotators, on 644 music tracks sourced from two publicly available music datasets, and covering a wide variety of genres. Questions in the benchmark are crafted to assess knowledge and reasoning abilities across several dimensions that cover fundamental musical concepts and their relation to cultural and functional contexts. Through the holistic analysis afforded by the benchmark, we evaluate five open-source models and identify several pitfalls, including an over-reliance on the language modality, pointing to a need for better multimodal integration. Data and code are open-sourced.
Leveraging Pre-Trained Autoencoders for Interpretable Prototype Learning of Music Audio
Feb 14, 2024


We present PECMAE, an interpretable model for music audio classification based on prototype learning. Our model is based on a previous method, APNet, which jointly learns an autoencoder and a prototypical network. Instead, we propose to decouple both training processes. This enables us to leverage existing self-supervised autoencoders pre-trained on much larger data (EnCodecMAE), providing representations with better generalization. APNet allows prototypes' reconstruction to waveforms for interpretability relying on the nearest training data samples. In contrast, we explore using a diffusion decoder that allows reconstruction without such dependency. We evaluate our method on datasets for music instrument classification (Medley-Solos-DB) and genre recognition (GTZAN and a larger in-house dataset), the latter being a more challenging task not addressed with prototypical networks before. We find that the prototype-based models preserve most of the performance achieved with the autoencoder embeddings, while the sonification of prototypes benefits understanding the behavior of the classifier.
mir_ref: A Representation Evaluation Framework for Music Information Retrieval Tasks
Dec 12, 2023


Music Information Retrieval (MIR) research is increasingly leveraging representation learning to obtain more compact, powerful music audio representations for various downstream MIR tasks. However, current representation evaluation methods are fragmented due to discrepancies in audio and label preprocessing, downstream model and metric implementations, data availability, and computational resources, often leading to inconsistent and limited results. In this work, we introduce mir_ref, an MIR Representation Evaluation Framework focused on seamless, transparent, local-first experiment orchestration to support representation development. It features implementations of a variety of components such as MIR datasets, tasks, embedding models, and tools for result analysis and visualization, while facilitating the implementation of custom components. To demonstrate its utility, we use it to conduct an extensive evaluation of several embedding models across various tasks and datasets, including evaluating their robustness to various audio perturbations and the ease of extracting relevant information from them.
The Song Describer Dataset: a Corpus of Audio Captions for Music-and-Language Evaluation
Nov 22, 2023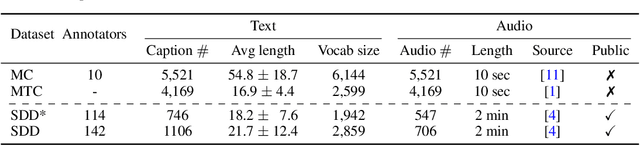
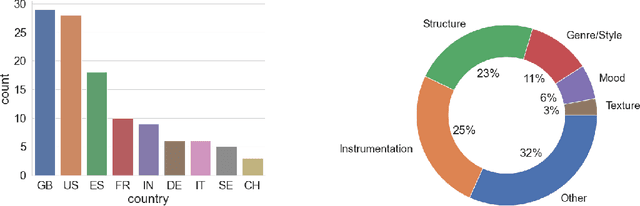


We introduce the Song Describer dataset (SDD), a new crowdsourced corpus of high-quality audio-caption pairs, designed for the evaluation of music-and-language models. The dataset consists of 1.1k human-written natural language descriptions of 706 music recordings, all publicly accessible and released under Creative Common licenses. To showcase the use of our dataset, we benchmark popular models on three key music-and-language tasks (music captioning, text-to-music generation and music-language retrieval). Our experiments highlight the importance of cross-dataset evaluation and offer insights into how researchers can use SDD to gain a broader understanding of model performance.
Efficient Supervised Training of Audio Transformers for Music Representation Learning
Sep 28, 2023



In this work, we address music representation learning using convolution-free transformers. We build on top of existing spectrogram-based audio transformers such as AST and train our models on a supervised task using patchout training similar to PaSST. In contrast to previous works, we study how specific design decisions affect downstream music tagging tasks instead of focusing on the training task. We assess the impact of initializing the models with different pre-trained weights, using various input audio segment lengths, using learned representations from different blocks and tokens of the transformer for downstream tasks, and applying patchout at inference to speed up feature extraction. We find that 1) initializing the model from ImageNet or AudioSet weights and using longer input segments are beneficial both for the training and downstream tasks, 2) the best representations for the considered downstream tasks are located in the middle blocks of the transformer, and 3) using patchout at inference allows faster processing than our convolutional baselines while maintaining superior performance. The resulting models, MAEST, are publicly available and obtain the best performance among open models in music tagging tasks.
Pre-Training Strategies Using Contrastive Learning and Playlist Information for Music Classification and Similarity
Apr 24, 2023



In this work, we investigate an approach that relies on contrastive learning and music metadata as a weak source of supervision to train music representation models. Recent studies show that contrastive learning can be used with editorial metadata (e.g., artist or album name) to learn audio representations that are useful for different classification tasks. In this paper, we extend this idea to using playlist data as a source of music similarity information and investigate three approaches to generate anchor and positive track pairs. We evaluate these approaches by fine-tuning the pre-trained models for music multi-label classification tasks (genre, mood, and instrument tagging) and music similarity. We find that creating anchor and positive track pairs by relying on co-occurrences in playlists provides better music similarity and competitive classification results compared to choosing tracks from the same artist as in previous works. Additionally, our best pre-training approach based on playlists provides superior classification performance for most datasets.