 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Music Audio Representations With Limited Data
May 09, 2025


Large deep-learning models for music, including those focused on learning general-purpose music audio representations, are often assumed to require substantial training data to achieve high performance. If true, this would pose challenges in scenarios where audio data or annotations are scarce, such as for underrepresented music traditions, non-popular genres, and personalized music creation and listening. Understanding how these models behave in limited-data scenarios could be crucial for developing techniques to tackle them. In this work, we investigate the behavior of several music audio representation models under limited-data learning regimes. We consider music models with various architectures, training paradigms, and input durations, and train them on data collections ranging from 5 to 8,000 minutes long. We evaluate the learned representations on various music information retrieval tasks and analyze their robustness to noise. We show that, under certain conditions, representations from limited-data and even random models perform comparably to ones from large-dataset models, though handcrafted features outperform all learned representations in some tasks.
Towards a Unified Representation Evaluation Framework Beyond Downstream Tasks
May 09, 2025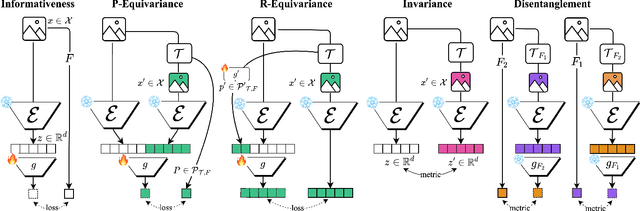


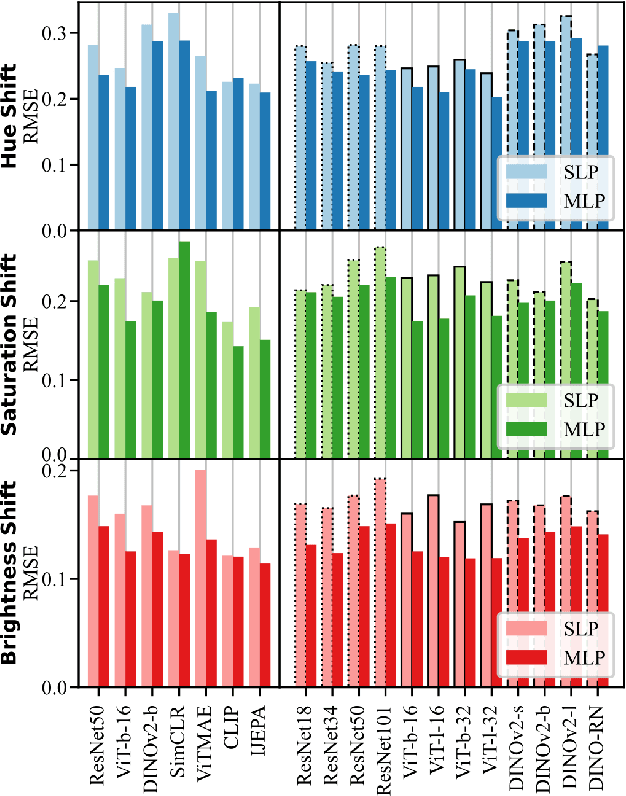
Downstream probing has been the dominant method for evaluating model representations, an important process given the increasing prominence of self-supervised learning and foundation models. However, downstream probing primarily assesses the availability of task-relevant information in the model's latent space, overlooking attributes such as equivariance, invariance, and disentanglement, which contribute to the interpretability, adaptability, and utility of representations in real-world applications. While some attempts have been made to measure these qualities in representations, no unified evaluation framework with modular, generalizable, and interpretable metrics exists. In this paper, we argue for the importance of representation evaluation beyond downstream probing. We introduce a standardized protocol to quantify informativeness, equivariance, invariance, and disentanglement of factors of variation in model representations. We use it to evaluate representations from a variety of models in the image and speech domains using different architectures and pretraining approaches on identified controllable factors of variation. We find that representations from models with similar downstream performance can behave substantially differently with regard to these attributes. This hints that the respective mechanisms underlying their downstream performance are functionally different, prompting new research directions to understand and improve representations.
Foundation Models for Music: A Survey
Aug 27, 2024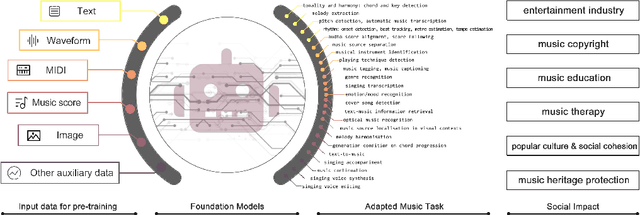

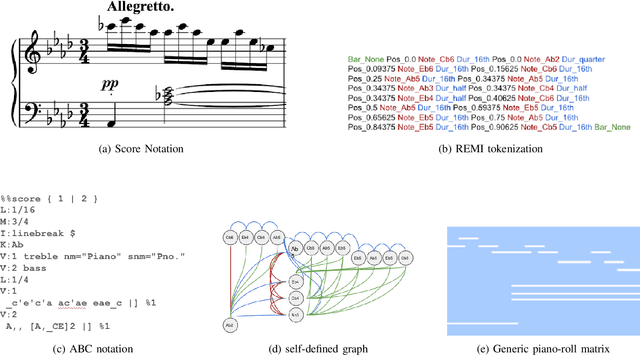
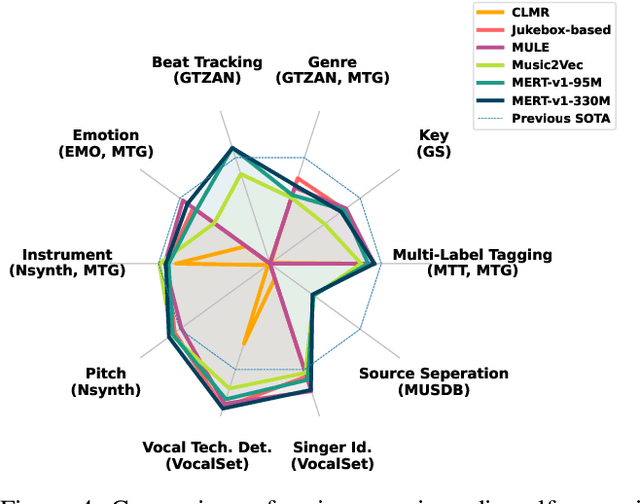
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
mir_ref: A Representation Evaluation Framework for Music Information Retrieval Tasks
Dec 12, 2023


Music Information Retrieval (MIR) research is increasingly leveraging representation learning to obtain more compact, powerful music audio representations for various downstream MIR tasks. However, current representation evaluation methods are fragmented due to discrepancies in audio and label preprocessing, downstream model and metric implementations, data availability, and computational resources, often leading to inconsistent and limited results. In this work, we introduce mir_ref, an MIR Representation Evaluation Framework focused on seamless, transparent, local-first experiment orchestration to support representation development. It features implementations of a variety of components such as MIR datasets, tasks, embedding models, and tools for result analysis and visualization, while facilitating the implementation of custom components. To demonstrate its utility, we use it to conduct an extensive evaluation of several embedding models across various tasks and datasets, including evaluating their robustness to various audio perturbations and the ease of extracting relevant information from them.
Music Rearrangement Using Hierarchical Segmentation
May 12, 2023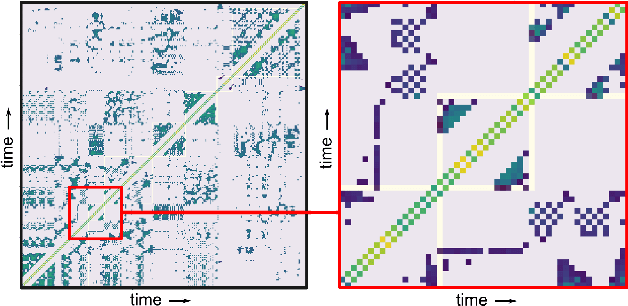
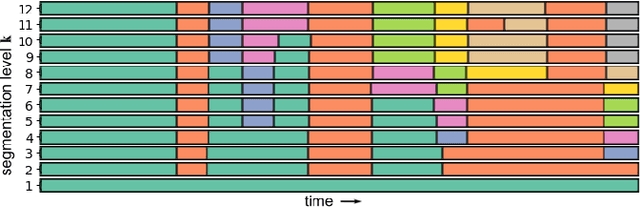
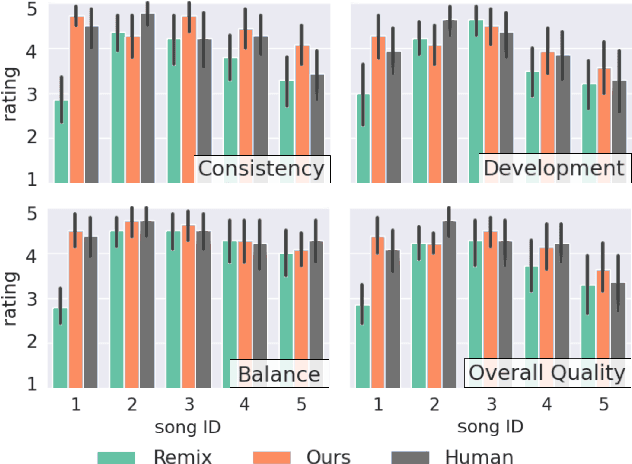
Music rearrangement involves reshuffling, deleting, and repeating sections of a music piece with the goal of producing a standalone version that has a different duration. It is a creative and time-consuming task commonly performed by an expert music engineer. In this paper, we propose a method for automatically rearranging music recordings that takes into account the hierarchical structure of the recording. Previous approaches focus solely on identifying cut-points in the audio that could result in smooth transitions. We instead utilize deep audio representations to hierarchically segment the piece and define a cut-point search subject to the boundaries and musical functions of the segments. We score suitable entry- and exit-point pairs based on their similarity and the segments they belong to, and define an optimal path search. Experimental results demonstrate the selected cut-points are most commonly imperceptible by listeners and result in more consistent musical development with less distracting repetitions.