 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified Representation Evaluation Framework Beyond Downstream Tasks
May 09, 2025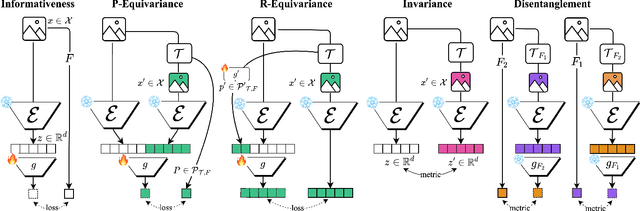


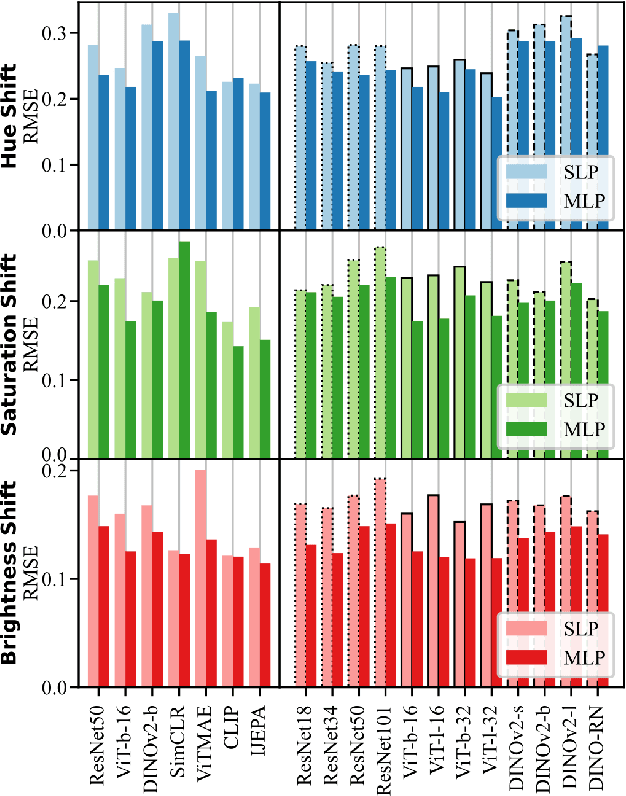
Downstream probing has been the dominant method for evaluating model representations, an important process given the increasing prominence of self-supervised learning and foundation models. However, downstream probing primarily assesses the availability of task-relevant information in the model's latent space, overlooking attributes such as equivariance, invariance, and disentanglement, which contribute to the interpretability, adaptability, and utility of representations in real-world applications. While some attempts have been made to measure these qualities in representations, no unified evaluation framework with modular, generalizable, and interpretable metrics exists. In this paper, we argue for the importance of representation evaluation beyond downstream probing. We introduce a standardized protocol to quantify informativeness, equivariance, invariance, and disentanglement of factors of variation in model representations. We use it to evaluate representations from a variety of models in the image and speech domains using different architectures and pretraining approaches on identified controllable factors of variation. We find that representations from models with similar downstream performance can behave substantially differently with regard to these attributes. This hints that the respective mechanisms underlying their downstream performance are functionally different, prompting new research directions to understand and improve representations.
Leave-One-EquiVariant: Alleviating invariance-related information loss in contrastive music representations
Dec 25, 2024



Contrastive learning has proven effective in self-supervised musical representation learning, particularly for Music Information Retrieval (MIR) tasks. However, reliance on augmentation chains for contrastive view generation and the resulting learnt invariances pose challenges when different downstream tasks require sensitivity to certain musical attributes. To address this, we propose the Leave One EquiVariant (LOEV) framework, which introduces a flexible, task-adaptive approach compared to previous work by selectively preserving information about specific augmentations, allowing the model to maintain task-relevant equivariances. We demonstrate that LOEV alleviates information loss related to learned invariances, improving performance on augmentation related tasks and retrieval without sacrificing general representation quality. Furthermore, we introduce a variant of LOEV, LOEV++, which builds a disentangled latent space by design in a self-supervised manner, and enables targeted retrieval based on augmentation related attributes.
Exploring trends in audio mixes and masters: Insights from a dataset analysis
Dec 04, 2024



We present an analysis of a dataset of audio metrics and aesthetic considerations about mixes and masters provided by the web platform MixCheck studio. The platform is designed for educational purposes, primarily targeting amateur music producers, and aimed at analysing their recordings prior to them being released. The analysis focuses on the following data points: integrated loudness, mono compatibility, presence of clipping and phase issues, compression and tonal profile across 30 user-specified genres. Both mixed (mixes) and mastered audio (masters) are included in the analysis, where mixes refer to the initial combination and balance of individual tracks, and masters refer to the final refined version optimized for distribution. Results show that loudness-related issues along with dynamics issues are the most prevalent, particularly in mastered audio. However mastered audio presents better results in compression than just mixed audio. Additionally, results show that mastered audio has a lower percentage of stereo field and phase issues.
Foundation Models for Music: A Survey
Aug 27, 2024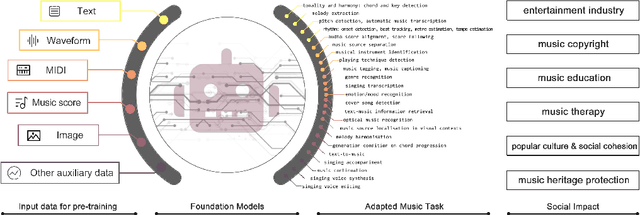

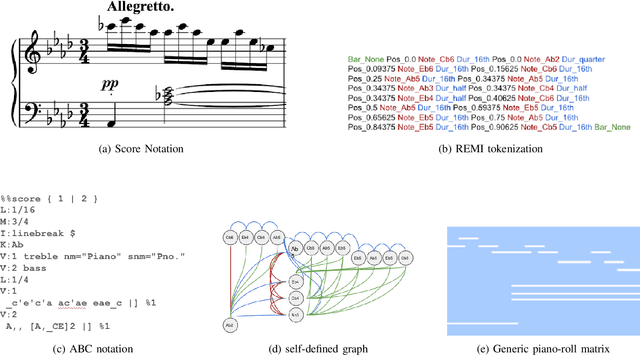
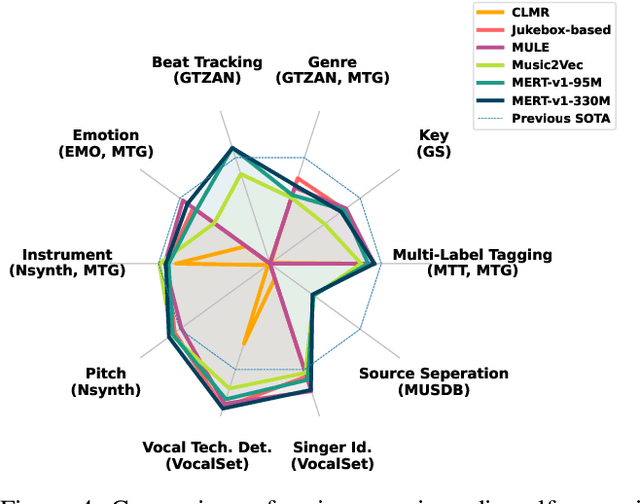
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
MuChoMusic: Evaluating Music Understanding in Multimodal Audio-Language Models
Aug 02, 2024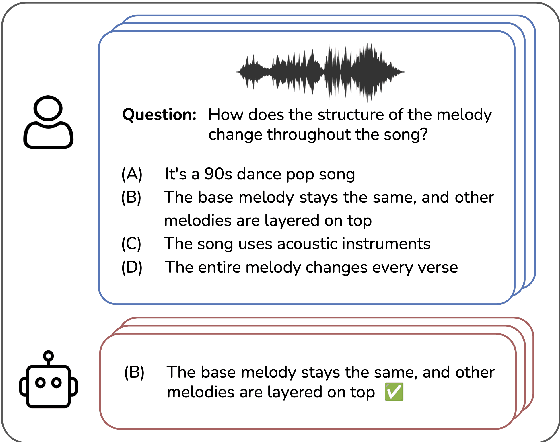
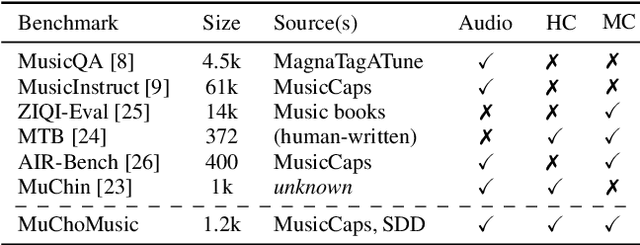
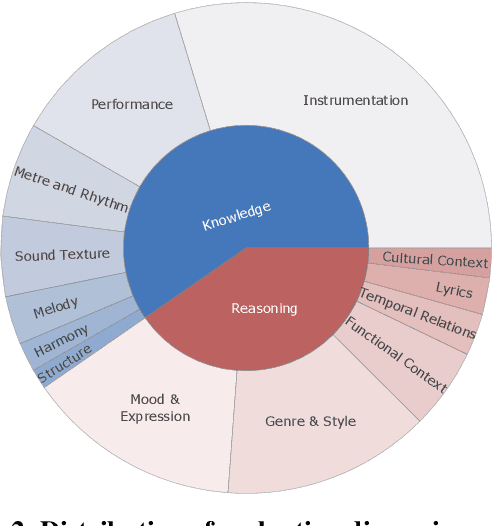

Multimodal models that jointly process audio and language hold great promise in audio understanding and are increasingly being adopted in the music domain. By allowing users to query via text and obtain information about a given audio input, these models have the potential to enable a variety of music understanding tasks via language-based interfaces. However, their evaluation poses considerable challenges, and it remains unclear how to effectively assess their ability to correctly interpret music-related inputs with current methods. Motivated by this, we introduce MuChoMusic, a benchmark for evaluating music understanding in multimodal language models focused on audio. MuChoMusic comprises 1,187 multiple-choice questions, all validated by human annotators, on 644 music tracks sourced from two publicly available music datasets, and covering a wide variety of genres. Questions in the benchmark are crafted to assess knowledge and reasoning abilities across several dimensions that cover fundamental musical concepts and their relation to cultural and functional contexts. Through the holistic analysis afforded by the benchmark, we evaluate five open-source models and identify several pitfalls, including an over-reliance on the language modality, pointing to a need for better multimodal integration. Data and code are open-sourced.
Robust Lossy Audio Compression Identification
Jul 31, 2024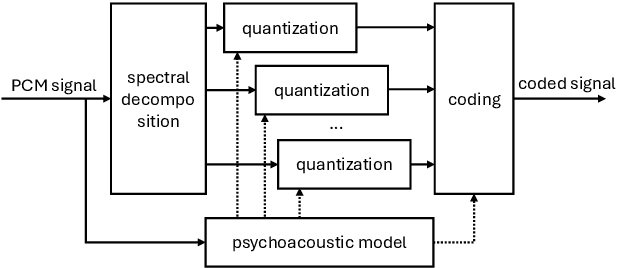

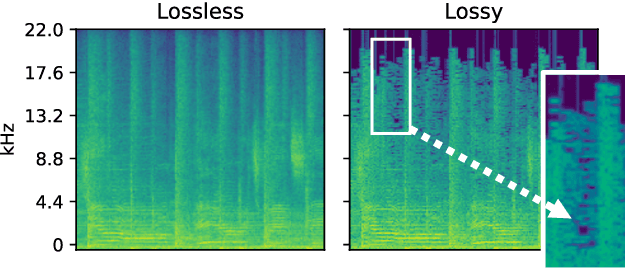

Previous research contributions on blind lossy compression identification report near perfect performance metrics on their test set, across a variety of codecs and bit rates. However, we show that such results can be deceptive and may not accurately represent true ability of the system to tackle the task at hand. In this article, we present an investigation into the robustness and generalisation capability of a lossy audio identification model. Our contributions are as follows. (1) We show the lack of robustness to codec parameter variations of a model equivalent to prior art. In particular, when naively training a lossy compression detection model on a dataset of music recordings processed with a range of codecs and their lossless counterparts, we obtain near perfect performance metrics on the held-out test set, but severely degraded performance on lossy tracks produced with codec parameters not seen in training. (2) We propose and show the effectiveness of an improved training strategy to significantly increase the robustness and generalisation capability of the model beyond codec configurations seen during training. Namely we apply a random mask to the input spectrogram to encourage the model not to rely solely on the training set's codec cutoff frequency.
Semi-Supervised Contrastive Learning of Musical Representations
Jul 18, 2024



Despite the success of contrastive learning in Music Information Retrieval, the inherent ambiguity of contrastive self-supervision presents a challenge. Relying solely on augmentation chains and self-supervised positive sampling strategies can lead to a pretraining objective that does not capture key musical information for downstream tasks. We introduce semi-supervised contrastive learning (SemiSupCon), a simple method for leveraging musically informed labeled data (supervision signals) in the contrastive learning of musical representations. Our approach introduces musically relevant supervision signals into self-supervised contrastive learning by combining supervised and self-supervised contrastive objectives in a simpler framework than previous approaches. This framework improves downstream performance and robustness to audio corruptions on a range of downstream MIR tasks with moderate amounts of labeled data. Our approach enables shaping the learned similarity metric through the choice of labeled data that (1) infuses the representations with musical domain knowledge and (2) improves out-of-domain performance with minimal general downstream performance loss. We show strong transfer learning performance on musically related yet not trivially similar tasks - such as pitch and key estimation. Additionally, our approach shows performance improvement on automatic tagging over self-supervised approaches with only 5\% of available labels included in pretraining.
The Song Describer Dataset: a Corpus of Audio Captions for Music-and-Language Evaluation
Nov 22, 2023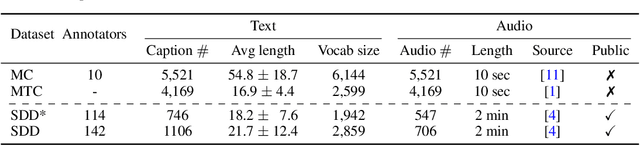
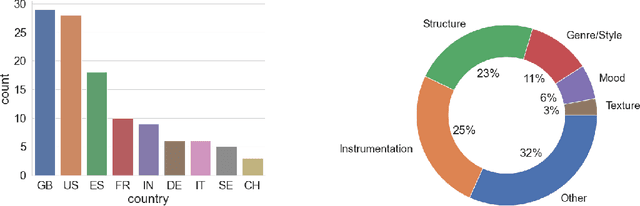


We introduce the Song Describer dataset (SDD), a new crowdsourced corpus of high-quality audio-caption pairs, designed for the evaluation of music-and-language models. The dataset consists of 1.1k human-written natural language descriptions of 706 music recordings, all publicly accessible and released under Creative Common licenses. To showcase the use of our dataset, we benchmark popular models on three key music-and-language tasks (music captioning, text-to-music generation and music-language retrieval). Our experiments highlight the importance of cross-dataset evaluation and offer insights into how researchers can use SDD to gain a broader understanding of model performance.
Serenade: A Model for Human-in-the-loop Automatic Chord Estimation
Oct 17, 2023



Computational harmony analysis is important for MIR tasks such as automatic segmentation, corpus analysis and automatic chord label estimation. However, recent research into the ambiguous nature of musical harmony, causing limited inter-rater agreement, has made apparent that there is a glass ceiling for common metrics such as accuracy. Commonly, these issues are addressed either in the training data itself by creating majority-rule annotations or during the training phase by learning soft targets. We propose a novel alternative approach in which a human and an autoregressive model together co-create a harmonic annotation for an audio track. After automatically generating harmony predictions, a human sparsely annotates parts with low model confidence and the model then adjusts its predictions following human guidance. We evaluate our model on a dataset of popular music and we show that, with this human-in-the-loop approach, harmonic analysis performance improves over a model-only approach. The human contribution is amplified by the second, constrained prediction of the model.
Equivariant Self-Supervision for Musical Tempo Estimation
Sep 03, 2022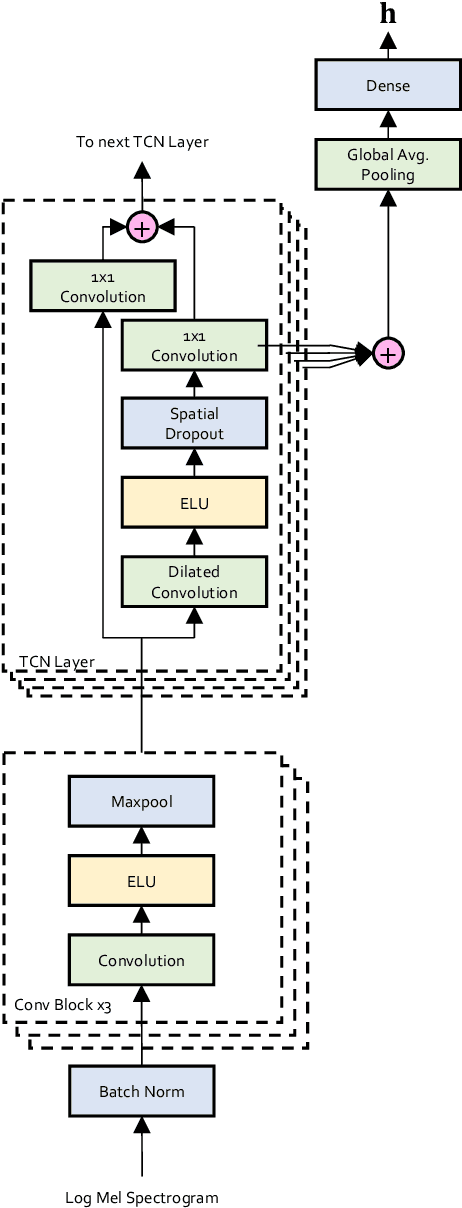
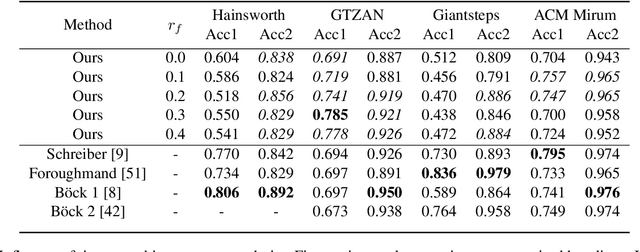
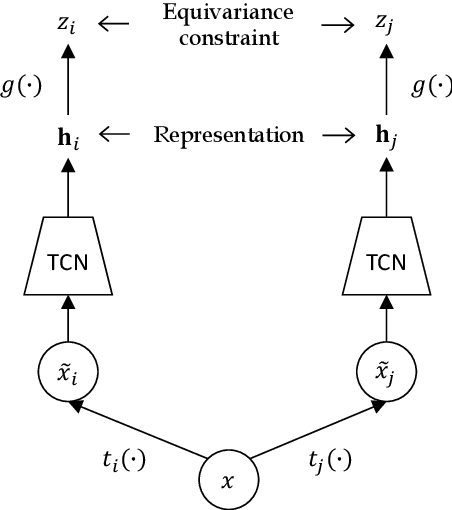
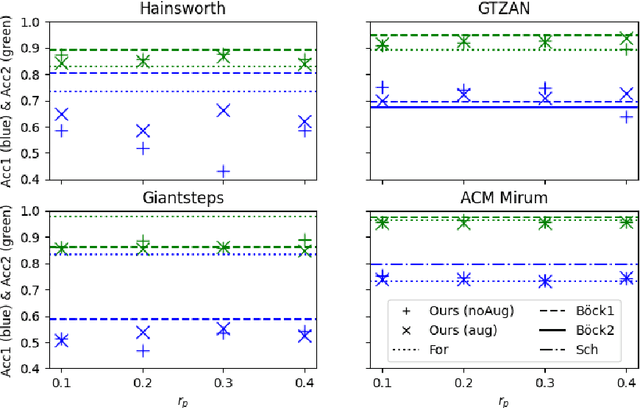
Self-supervised methods have emerged as a promising avenue for representation learning in the recent years since they alleviate the need for labeled datasets, which are scarce and expensive to acquire. Contrastive methods are a popular choice for self-supervision in the audio domain, and typically provide a learning signal by forcing the model to be invariant to some transformations of the input. These methods, however, require measures such as negative sampling or some form of regularisation to be taken to prevent the model from collapsing on trivial solutions. In this work, instead of invariance, we propose to use equivariance as a self-supervision signal to learn audio tempo representations from unlabelled data. We derive a simple loss function that prevents the network from collapsing on a trivial solution during training, without requiring any form of regularisation or negative sampling. Our experiments show that it is possible to learn meaningful representations for tempo estimation by solely relying on equivariant self-supervision, achieving performance comparable with supervised methods on several benchmarks. As an added benefit, our method only requires moderate compute resources and therefore remains accessible to a wide research community.