 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Adaptation of Pre-trained Foundation Models for Music Structure Analysis
Jul 17, 2025



Audio-based music structure analysis (MSA) is an essential task in Music Information Retrieval that remains challenging due to the complexity and variability of musical form. Recent advances highlight the potential of fine-tuning pre-trained music foundation models for MSA tasks. However, these models are typically trained with high temporal feature resolution and short audio windows, which limits their efficiency and introduces bias when applied to long-form audio. This paper presents a temporal adaptation approach for fine-tuning music foundation models tailored to MSA. Our method enables efficient analysis of full-length songs in a single forward pass by incorporating two key strategies: (1) audio window extension and (2) low-resolution adaptation. Experiments on the Harmonix Set and RWC-Pop datasets show that our method significantly improves both boundary detection and structural function prediction, while maintaining comparable memory usage and inference speed.
Hybrid-Field 6D Movable Antenna for Terahertz Communications: Channel Modeling and Estimation
May 07, 2025In this work, we study a six-dimensional movable antenna (6DMA)-enhanced Terahertz (THz) network that supports a large number of users with a few antennas by controlling the three-dimensional (3D) positions and 3D rotations of antenna surfaces/subarrays at the base station (BS). However, the short wavelength of THz signals combined with a large 6DMA movement range extends the near-field region. As a result, a user can be in the far-field region relative to the antennas on one 6DMA surface, while simultaneously residing in the near-field region relative to other 6DMA surfaces. Moreover, 6DMA THz channel estimation suffers from increased computational complexity and pilot overhead due to uneven power distribution across the large number of candidate position-rotation pairs, as well as the limited number of radio frequency (RF) chains in THz bands. To address these issues, we propose an efficient hybrid-field generalized 6DMA THz channel model, which accounts for planar wave propagation within individual 6DMA surfaces and spherical waves among different 6DMA surfaces. Furthermore, we propose a low-overhead channel estimation algorithm that leverages directional sparsity to construct a complete channel map for all potential antenna position-rotation pairs. Numerical results show that the proposed hybrid-field channel model achieves a sum rate close to that of the ground-truth near-field channel model and confirm that the channel estimation method yields accurate results with low complexity.
Improving Controllability and Editability for Pretrained Text-to-Music Generation Models
Nov 21, 2024



The field of AI-assisted music creation has made significant strides, yet existing systems often struggle to meet the demands of iterative and nuanced music production. These challenges include providing sufficient control over the generated content and allowing for flexible, precise edits. This thesis tackles these issues by introducing a series of advancements that progressively build upon each other, enhancing the controllability and editability of text-to-music generation models. First, we introduce Loop Copilot, a system that tries to address the need for iterative refinement in music creation. Loop Copilot leverages a large language model (LLM) to coordinate multiple specialised AI models, enabling users to generate and refine music interactively through a conversational interface. Central to this system is the Global Attribute Table, which records and maintains key musical attributes throughout the iterative process, ensuring that modifications at any stage preserve the overall coherence of the music. While Loop Copilot excels in orchestrating the music creation process, it does not directly address the need for detailed edits to the generated content. To overcome this limitation, MusicMagus is presented as a further solution for editing AI-generated music. MusicMagus introduces a zero-shot text-to-music editing approach that allows for the modification of specific musical attributes, such as genre, mood, and instrumentation, without the need for retraining. By manipulating the latent space within pre-trained diffusion models, MusicMagus ensures that these edits are stylistically coherent and that non-targeted attributes remain unchanged. This system is particularly effective in maintaining the structural integrity of the music during edits, but it encounters challenges with more complex and real-world audio scenarios. ...
Security Enhancement of Quantum Communication in Space-Air-Ground Integrated Networks
Oct 22, 2024This paper investigates a transmission scheme for enhancing quantum communication security, aimed at improving the security of space-air-ground integrated networks (SAGIN). Quantum teleportation achieves the transmission of quantum states through quantum channels. In simple terms, an unknown quantum state at one location can be reconstructed on a particle at another location. By combining classical Turbo coding with quantum Shor error-correcting codes, we propose a practical solution that ensures secure information transmission even in the presence of errors in both classical and quantum channels. To provide absolute security under SAGIN, we add a quantum secure direct communication (QSDC) protocol to the current system. Specifically, by accounting for the practical scenario of eavesdropping in quantum channels, the QSDC protocol utilizes virtual entangled pairs to detect the presence of eavesdroppers. Consequently, the overall scheme guarantees both the reliability and absolute security of communication.
The Interpretation Gap in Text-to-Music Generation Models
Jul 14, 2024



Large-scale text-to-music generation models have significantly enhanced music creation capabilities, offering unprecedented creative freedom. However, their ability to collaborate effectively with human musicians remains limited. In this paper, we propose a framework to describe the musical interaction process, which includes expression, interpretation, and execution of controls. Following this framework, we argue that the primary gap between existing text-to-music models and musicians lies in the interpretation stage, where models lack the ability to interpret controls from musicians. We also propose two strategies to address this gap and call on the music information retrieval community to tackle the interpretation challenge to improve human-AI musical collaboration.
Instruct-MusicGen: Unlocking Text-to-Music Editing for Music Language Models via Instruction Tuning
May 29, 2024



Recent advances in text-to-music editing, which employ text queries to modify music (e.g.\ by changing its style or adjusting instrumental components), present unique challenges and opportunities for AI-assisted music creation. Previous approaches in this domain have been constrained by the necessity to train specific editing models from scratch, which is both resource-intensive and inefficient; other research uses large language models to predict edited music, resulting in imprecise audio reconstruction. To Combine the strengths and address these limitations, we introduce Instruct-MusicGen, a novel approach that finetunes a pretrained MusicGen model to efficiently follow editing instructions such as adding, removing, or separating stems. Our approach involves a modification of the original MusicGen architecture by incorporating a text fusion module and an audio fusion module, which allow the model to process instruction texts and audio inputs concurrently and yield the desired edited music. Remarkably, Instruct-MusicGen only introduces 8% new parameters to the original MusicGen model and only trains for 5K steps, yet it achieves superior performance across all tasks compared to existing baselines, and demonstrates performance comparable to the models trained for specific tasks. This advancement not only enhances the efficiency of text-to-music editing but also broadens the applicability of music language models in dynamic music production environments.
Universal and Extensible Language-Vision Models for Organ Segmentation and Tumor Detection from Abdominal Computed Tomography
May 28, 2024



The advancement of artificial intelligence (AI) for organ segmentation and tumor detection is propelled by the growing availability of computed tomography (CT) datasets with detailed, per-voxel annotations. However, these AI models often struggle with flexibility for partially annotated datasets and extensibility for new classes due to limitations in the one-hot encoding, architectural design, and learning scheme. To overcome these limitations, we propose a universal, extensible framework enabling a single model, termed Universal Model, to deal with multiple public datasets and adapt to new classes (e.g., organs/tumors). Firstly, we introduce a novel language-driven parameter generator that leverages language embeddings from large language models, enriching semantic encoding compared with one-hot encoding. Secondly, the conventional output layers are replaced with lightweight, class-specific heads, allowing Universal Model to simultaneously segment 25 organs and six types of tumors and ease the addition of new classes. We train our Universal Model on 3,410 CT volumes assembled from 14 publicly available datasets and then test it on 6,173 CT volumes from four external datasets. Universal Model achieves first place on six CT tasks in the Medical Segmentation Decathlon (MSD) public leaderboard and leading performance on the Beyond The Cranial Vault (BTCV) dataset. In summary, Universal Model exhibits remarkable computational efficiency (6x faster than other dataset-specific models), demonstrates strong generalization across different hospitals, transfers well to numerous downstream tasks, and more importantly, facilitates the extensibility to new classes while alleviating the catastrophic forgetting of previously learned classes. Codes, models, and datasets are available at https://github.com/ljwztc/CLIP-Driven-Universal-Model
Exploiting Structural Consistency of Chest Anatomy for Unsupervised Anomaly Detection in Radiography Images
Mar 13, 2024



Radiography imaging protocols focus on particular body regions, therefore producing images of great similarity and yielding recurrent anatomical structures across patients. Exploiting this structured information could potentially ease the detection of anomalies from radiography images. To this end, we propose a Simple Space-Aware Memory Matrix for In-painting and Detecting anomalies from radiography images (abbreviated as SimSID). We formulate anomaly detection as an image reconstruction task, consisting of a space-aware memory matrix and an in-painting block in the feature space. During the training, SimSID can taxonomize the ingrained anatomical structures into recurrent visual patterns, and in the inference, it can identify anomalies (unseen/modified visual patterns) from the test image. Our SimSID surpasses the state of the arts in unsupervised anomaly detection by +8.0%, +5.0%, and +9.9% AUC scores on ZhangLab, COVIDx, and CheXpert benchmark datasets, respectively. Code: https://github.com/MrGiovanni/SimSID
Arrange, Inpaint, and Refine: Steerable Long-term Music Audio Generation and Editing via Content-based Controls
Feb 14, 2024
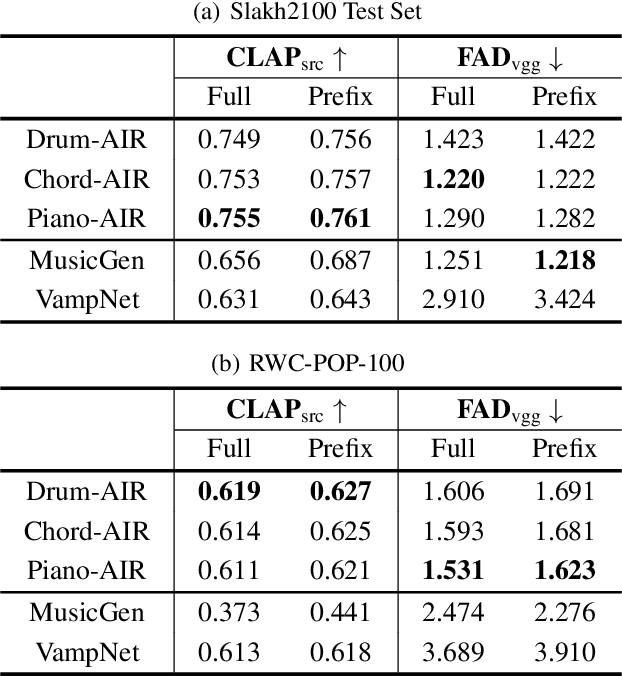

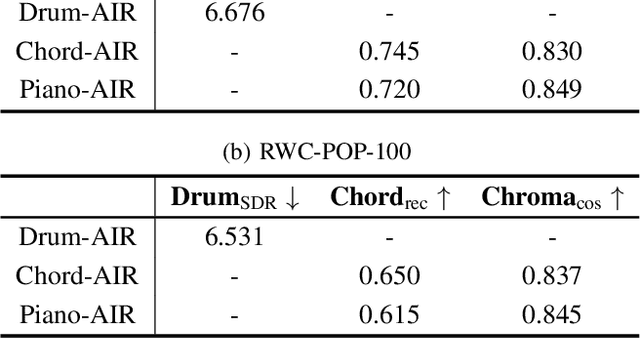
Controllable music generation plays a vital role in human-AI music co-creation. While Large Language Models (LLMs) have shown promise in generating high-quality music, their focus on autoregressive generation limits their utility in music editing tasks. To bridge this gap, we introduce a novel Parameter-Efficient Fine-Tuning (PEFT) method. This approach enables autoregressive language models to seamlessly address music inpainting tasks. Additionally, our PEFT method integrates frame-level content-based controls, facilitating track-conditioned music refinement and score-conditioned music arrangement. We apply this method to fine-tune MusicGen, a leading autoregressive music generation model. Our experiments demonstrate promising results across multiple music editing tasks, offering more flexible controls for future AI-driven music editing tools. A demo page\footnote{\url{https://kikyo-16.github.io/AIR/}.} showcasing our work and source codes\footnote{\url{https://github.com/Kikyo-16/airgen}.} are available online.
MusicMagus: Zero-Shot Text-to-Music Editing via Diffusion Models
Feb 09, 2024



Recent advances in text-to-music generation models have opened new avenues in musical creativity. However, music generation usually involves iterative refinements, and how to edit the generated music remains a significant challenge. This paper introduces a novel approach to the editing of music generated by such models, enabling the modification of specific attributes, such as genre, mood and instrument, while maintaining other aspects unchanged. Our method transforms text editing to \textit{latent space manipulation} while adding an extra constraint to enforce consistency. It seamlessly integrates with existing pretrained text-to-music diffusion models without requiring additional training. Experimental results demonstrate superior performance over both zero-shot and certain supervised baselines in style and timbre transfer evaluations. Additionally, we showcase the practical applicability of our approach in real-world music editing scenarios.