 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArrange, Inpaint, and Refine: Steerable Long-term Music Audio Generation and Editing via Content-based Controls
Feb 14, 2024
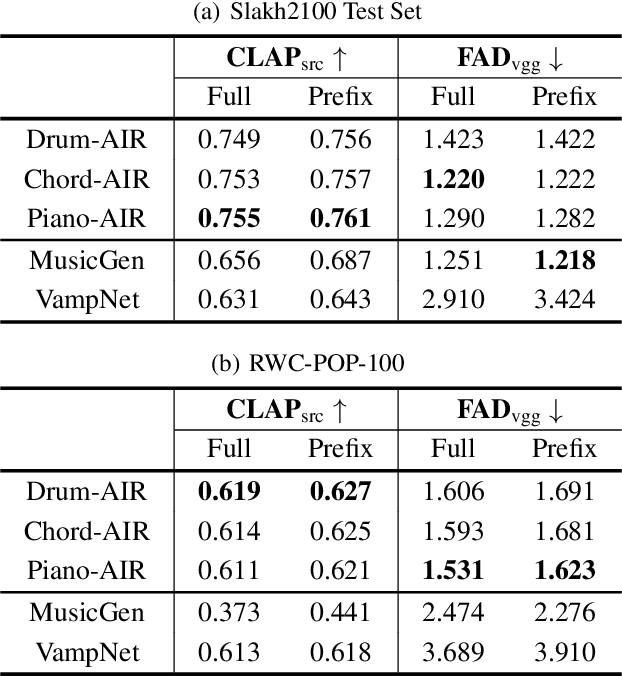

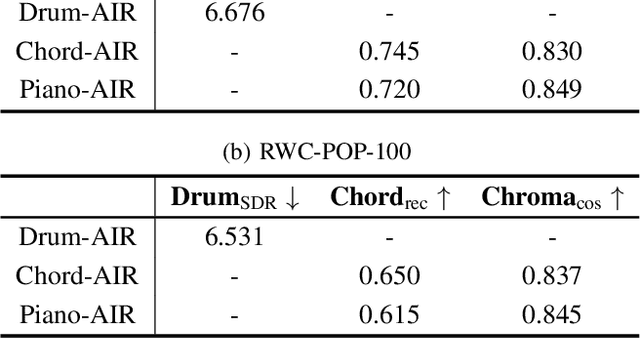
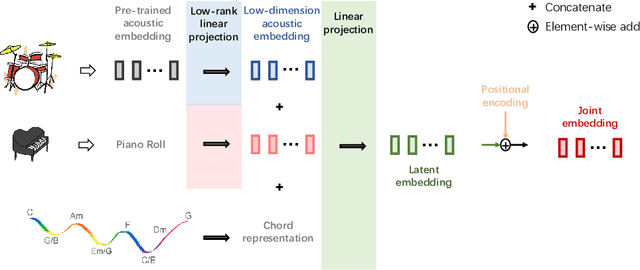
Controllable music generation plays a vital role in human-AI music co-creation. While Large Language Models (LLMs) have shown promise in generating high-quality music, their focus on autoregressive generation limits their utility in music editing tasks. To bridge this gap, we introduce a novel Parameter-Efficient Fine-Tuning (PEFT) method. This approach enables autoregressive language models to seamlessly address music inpainting tasks. Additionally, our PEFT method integrates frame-level content-based controls, facilitating track-conditioned music refinement and score-conditioned music arrangement. We apply this method to fine-tune MusicGen, a leading autoregressive music generation model. Our experiments demonstrate promising results across multiple music editing tasks, offering more flexible controls for future AI-driven music editing tools. A demo page\footnote{\url{https://kikyo-16.github.io/AIR/}.} showcasing our work and source codes\footnote{\url{https://github.com/Kikyo-16/airgen}.} are available online.
Content-based Controls For Music Large Language Modeling
Oct 26, 2023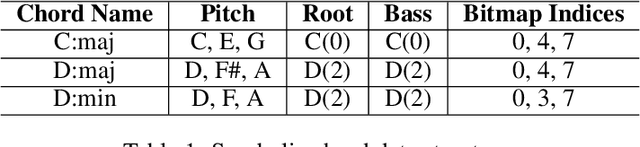
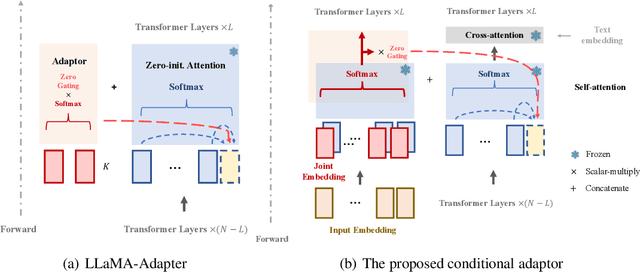
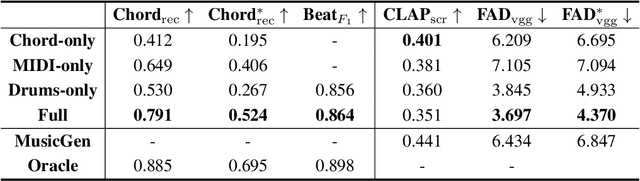
Recent years have witnessed a rapid growth of large-scale language models in the domain of music audio. Such models enable end-to-end generation of higher-quality music, and some allow conditioned generation using text descriptions. However, the control power of text controls on music is intrinsically limited, as they can only describe music indirectly through meta-data (such as singers and instruments) or high-level representations (such as genre and emotion). We aim to further equip the models with direct and content-based controls on innate music languages such as pitch, chords and drum track. To this end, we contribute Coco-Mulla, a content-based control method for music large language modeling. It uses a parameter-efficient fine-tuning (PEFT) method tailored for Transformer-based audio models. Experiments show that our approach achieved high-quality music generation with low-resource semi-supervised learning, tuning with less than 4% parameters compared to the original model and training on a small dataset with fewer than 300 songs. Moreover, our approach enables effective content-based controls, and we illustrate the control power via chords and rhythms, two of the most salient features of music audio. Furthermore, we show that by combining content-based controls and text descriptions, our system achieves flexible music variation generation and style transfer. Our source codes and demos are available online.
Polyffusion: A Diffusion Model for Polyphonic Score Generation with Internal and External Controls
Jul 19, 2023We propose Polyffusion, a diffusion model that generates polyphonic music scores by regarding music as image-like piano roll representations. The model is capable of controllable music generation with two paradigms: internal control and external control. Internal control refers to the process in which users pre-define a part of the music and then let the model infill the rest, similar to the task of masked music generation (or music inpainting). External control conditions the model with external yet related information, such as chord, texture, or other features, via the cross-attention mechanism. We show that by using internal and external controls, Polyffusion unifies a wide range of music creation tasks, including melody generation given accompaniment, accompaniment generation given melody, arbitrary music segment inpainting, and music arrangement given chords or textures. Experimental results show that our model significantly outperforms existing Transformer and sampling-based baselines, and using pre-trained disentangled representations as external conditions yields more effective controls.
Self-Supervised Hierarchical Metrical Structure Modeling
Oct 31, 2022



We propose a novel method to model hierarchical metrical structures for both symbolic music and audio signals in a self-supervised manner with minimal domain knowledge. The model trains and inferences on beat-aligned music signals and predicts an 8-layer hierarchical metrical tree from beat, measure to the section level. The training procedural does not require any hierarchical metrical labeling except for beats, purely relying on the nature of metrical regularity and inter-voice consistency as inductive biases. We show in experiments that the method achieves comparable performance with supervised baselines on multiple metrical structure analysis tasks on both symbolic music and audio signals. All demos, source code and pre-trained models are publicly available on GitHub.
Learning Hierarchical Metrical Structure Beyond Measures
Sep 21, 2022
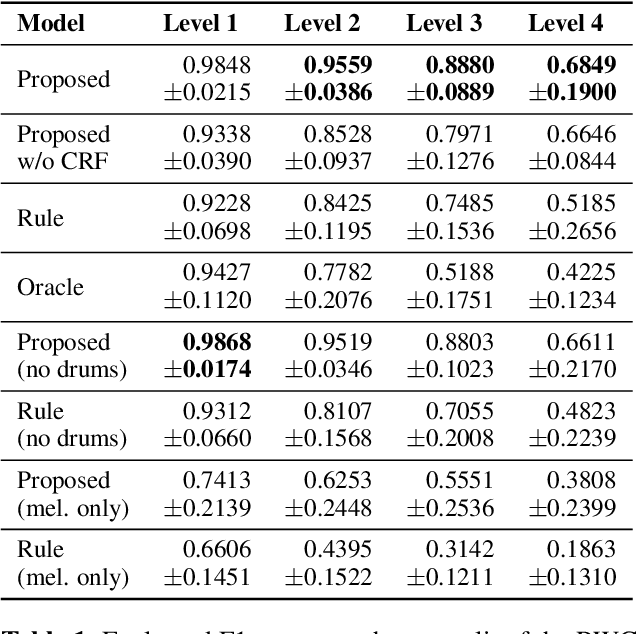
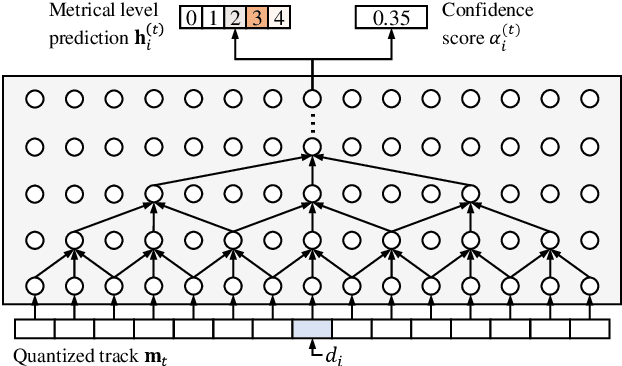
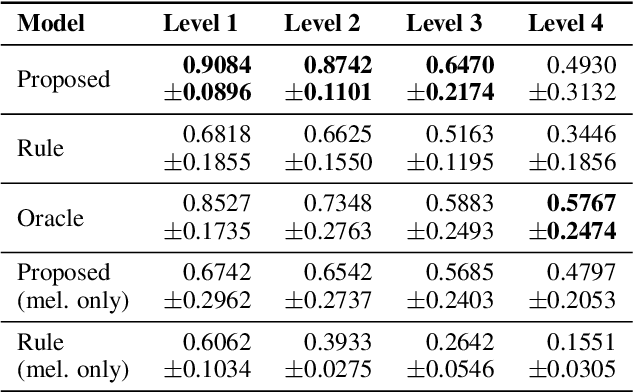
Music contains hierarchical structures beyond beats and measures. While hierarchical structure annotations are helpful for music information retrieval and computer musicology, such annotations are scarce in current digital music databases. In this paper, we explore a data-driven approach to automatically extract hierarchical metrical structures from scores. We propose a new model with a Temporal Convolutional Network-Conditional Random Field (TCN-CRF) architecture. Given a symbolic music score, our model takes in an arbitrary number of voices in a beat-quantized form, and predicts a 4-level hierarchical metrical structure from downbeat-level to section-level. We also annotate a dataset using RWC-POP MIDI files to facilitate training and evaluation. We show by experiments that the proposed method performs better than the rule-based approach under different orchestration settings. We also perform some simple musicological analysis on the model predictions. All demos, datasets and pre-trained models are publicly available on Github.
Interpreting Song Lyrics with an Audio-Informed Pre-trained Language Model
Aug 24, 2022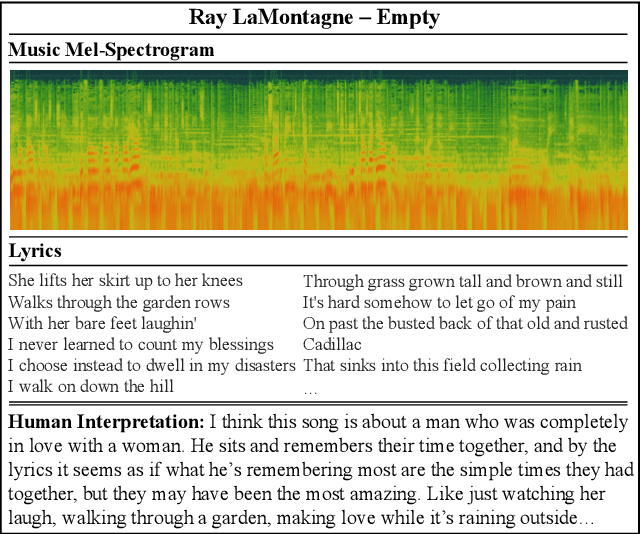
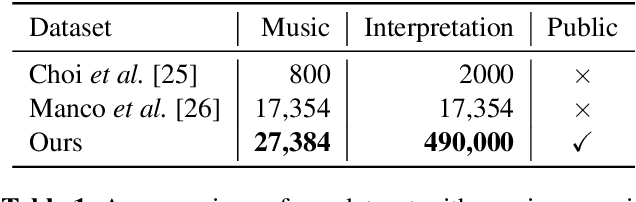
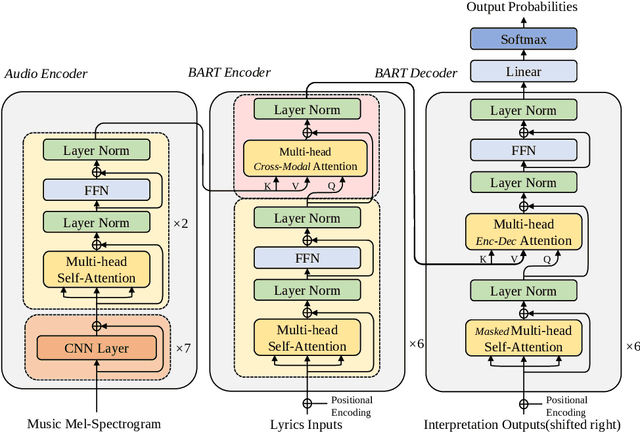
Lyric interpretations can help people understand songs and their lyrics quickly, and can also make it easier to manage, retrieve and discover songs efficiently from the growing mass of music archives. In this paper we propose BART-fusion, a novel model for generating lyric interpretations from lyrics and music audio that combines a large-scale pre-trained language model with an audio encoder. We employ a cross-modal attention module to incorporate the audio representation into the lyrics representation to help the pre-trained language model understand the song from an audio perspective, while preserving the language model's original generative performance. We also release the Song Interpretation Dataset, a new large-scale dataset for training and evaluating our model. Experimental results show that the additional audio information helps our model to understand words and music better, and to generate precise and fluent interpretations. An additional experiment on cross-modal music retrieval shows that interpretations generated by BART-fusion can also help people retrieve music more accurately than with the original BART.
A Unified Model for Zero-shot Music Source Separation, Transcription and Synthesis
Aug 07, 2021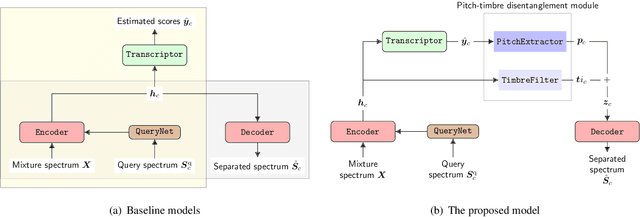

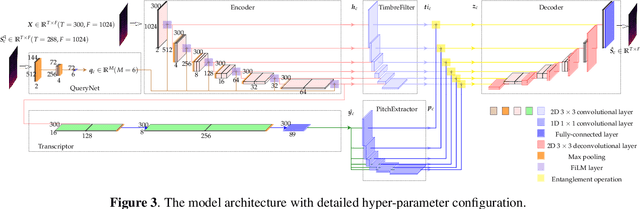
We propose a unified model for three inter-related tasks: 1) to \textit{separate} individual sound sources from a mixed music audio, 2) to \textit{transcribe} each sound source to MIDI notes, and 3) to\textit{ synthesize} new pieces based on the timbre of separated sources. The model is inspired by the fact that when humans listen to music, our minds can not only separate the sounds of different instruments, but also at the same time perceive high-level representations such as score and timbre. To mirror such capability computationally, we designed a pitch-timbre disentanglement module based on a popular encoder-decoder neural architecture for source separation. The key inductive biases are vector-quantization for pitch representation and pitch-transformation invariant for timbre representation. In addition, we adopted a query-by-example method to achieve \textit{zero-shot} learning, i.e., the model is capable of doing source separation, transcription, and synthesis for \textit{unseen} instruments. The current design focuses on audio mixtures of two monophonic instruments. Experimental results show that our model outperforms existing multi-task baselines, and the transcribed score serves as a powerful auxiliary for separation tasks.
POP909: A Pop-song Dataset for Music Arrangement Generation
Aug 17, 2020
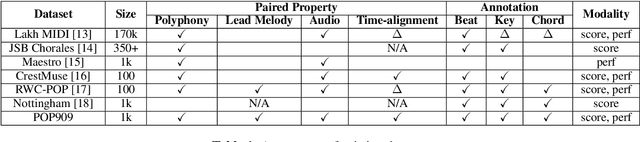
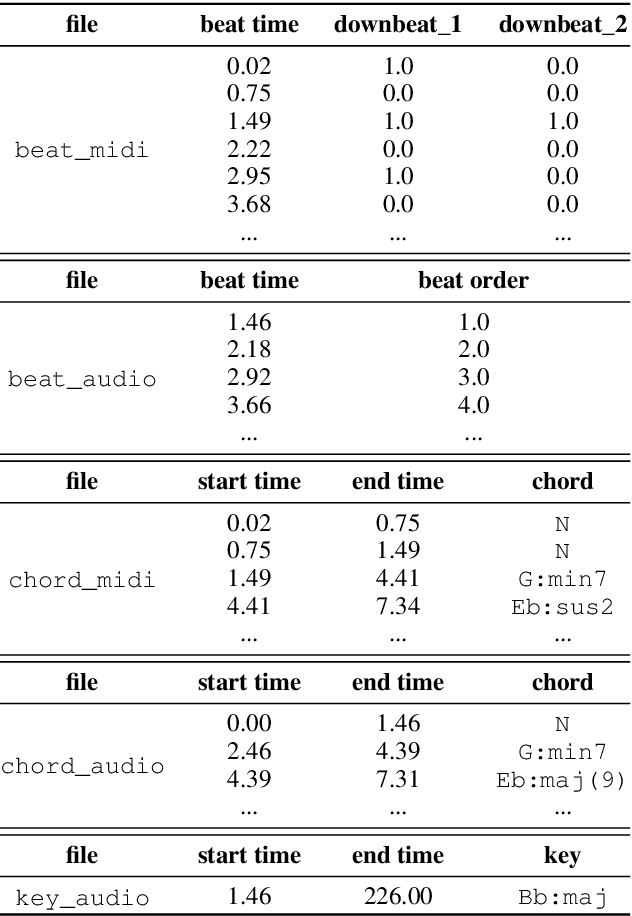
Music arrangement generation is a subtask of automatic music generation, which involves reconstructing and re-conceptualizing a piece with new compositional techniques. Such a generation process inevitably requires reference from the original melody, chord progression, or other structural information. Despite some promising models for arrangement, they lack more refined data to achieve better evaluations and more practical results. In this paper, we propose POP909, a dataset which contains multiple versions of the piano arrangements of 909 popular songs created by professional musicians. The main body of the dataset contains the vocal melody, the lead instrument melody, and the piano accompaniment for each song in MIDI format, which are aligned to the original audio files. Furthermore, we provide the annotations of tempo, beat, key, and chords, where the tempo curves are hand-labeled and others are done by MIR algorithms. Finally, we conduct several baseline experiments with this dataset using standard deep music generation algorithms.
PIANOTREE VAE: Structured Representation Learning for Polyphonic Music
Aug 17, 2020
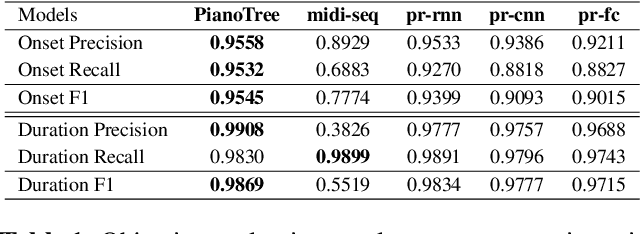
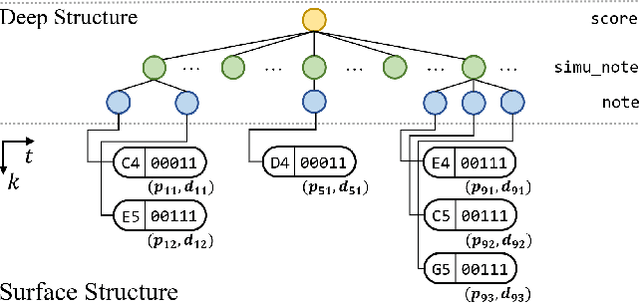
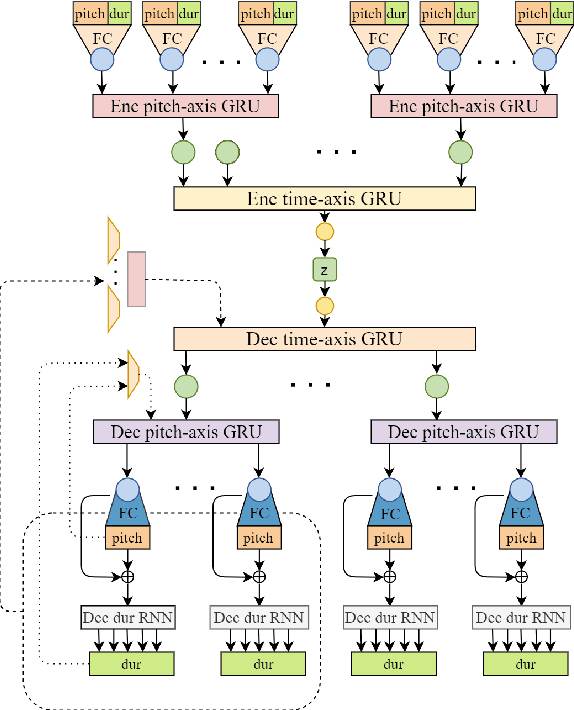
The dominant approach for music representation learning involves the deep unsupervised model family variational autoencoder (VAE). However, most, if not all, viable attempts on this problem have largely been limited to monophonic music. Normally composed of richer modality and more complex musical structures, the polyphonic counterpart has yet to be addressed in the context of music representation learning. In this work, we propose the PianoTree VAE, a novel tree-structure extension upon VAE aiming to fit the polyphonic music learning. The experiments prove the validity of the PianoTree VAE via (i)-semantically meaningful latent code for polyphonic segments; (ii)-more satisfiable reconstruction aside of decent geometry learned in the latent space; (iii)-this model's benefits to the variety of the downstream music generation.
Deep Music Analogy Via Latent Representation Disentanglement
Jul 08, 2019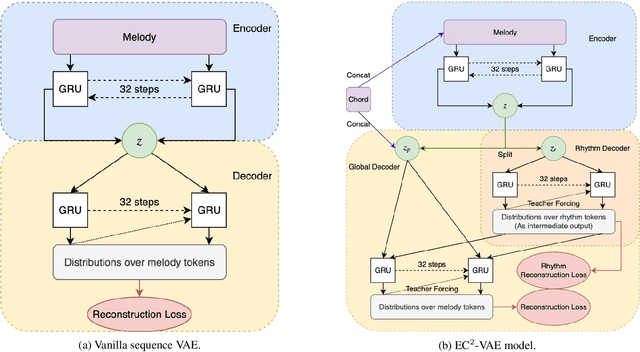
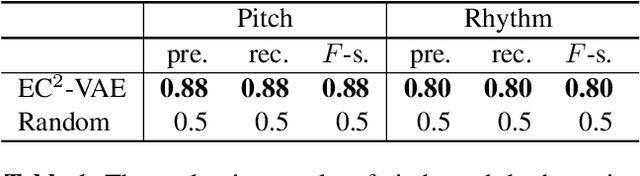
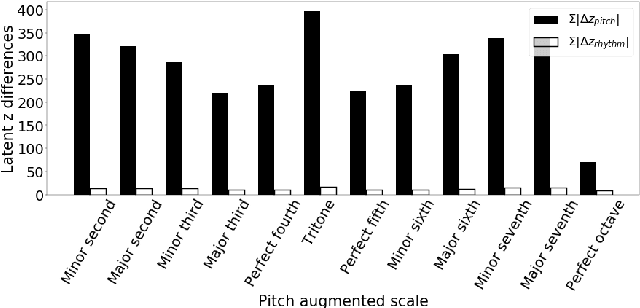
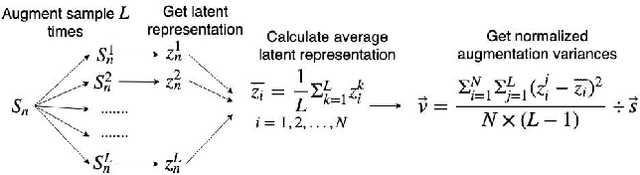
Analogy-making is a key method for computer algorithms to generate both natural and creative music pieces. In general, an analogy is made by partially transferring the music abstractions, i.e., high-level representations and their relationships, from one piece to another; however, this procedure requires disentangling music representations, which usually takes little effort for musicians but is non-trivial for computers. Three sub-problems arise: extracting latent representations from the observation, disentangling the representations so that each part has a unique semantic interpretation, and mapping the latent representations back to actual music. In this paper, we contribute an explicitly-constrained variational autoencoder (EC$^2$-VAE) as a unified solution to all three sub-problems. We focus on disentangling the pitch and rhythm representations of 8-beat music clips conditioned on chords. In producing music analogies, this model helps us to realize the imaginary situation of "what if" a piece is composed using a different pitch contour, rhythm pattern, or chord progression by borrowing the representations from other pieces. Finally, we validate the proposed disentanglement method using objective measurements and evaluate the analogy examples by a subjective study.