 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Centered LLM-Agent User Interface: A Position Paper
May 19, 2024



Large Language Model (LLM) -in-the-loop applications have been shown to effectively interpret the human user's commands, make plans, and operate external tools/systems accordingly. Still, the operation scope of the LLM agent is limited to passively following the user, requiring the user to frame his/her needs with regard to the underlying tools/systems. We note that the potential of an LLM-Agent User Interface (LAUI) is much greater. A user mostly ignorant to the underlying tools/systems should be able to work with a LAUI to discover an emergent workflow. Contrary to the conventional way of designing an explorable GUI to teach the user a predefined set of ways to use the system, in the ideal LAUI, the LLM agent is initialized to be proficient with the system, proactively studies the user and his/her needs, and proposes new interaction schemes to the user. To illustrate LAUI, we present Flute X GPT, a concrete example using an LLM agent, a prompt manager, and a flute-tutoring multi-modal software-hardware system to facilitate the complex, real-time user experience of learning to play the flute.
Learning Interpretable Low-dimensional Representation via Physical Symmetry
Feb 24, 2023
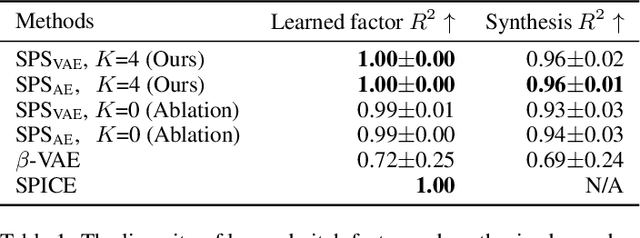


Interpretable representation learning has been playing a key role in creative intelligent systems. In the music domain, current learning algorithms can successfully learn various features such as pitch, timbre, chord, texture, etc. However, most methods rely heavily on music domain knowledge. It remains an open question what general computational principles give rise to interpretable representations, especially low-dim factors that agree with human perception. In this study, we take inspiration from modern physics and use physical symmetry as a self-consistency constraint for the latent space. Specifically, it requires the prior model that characterises the dynamics of the latent states to be equivariant with respect to certain group transformations. We show that physical symmetry leads the model to learn a linear pitch factor from unlabelled monophonic music audio in a self-supervised fashion. In addition, the same methodology can be applied to computer vision, learning a 3D Cartesian space from videos of a simple moving object without labels. Furthermore, physical symmetry naturally leads to representation augmentation, a new technique which improves sample efficiency.
Learning Hierarchical Metrical Structure Beyond Measures
Sep 21, 2022
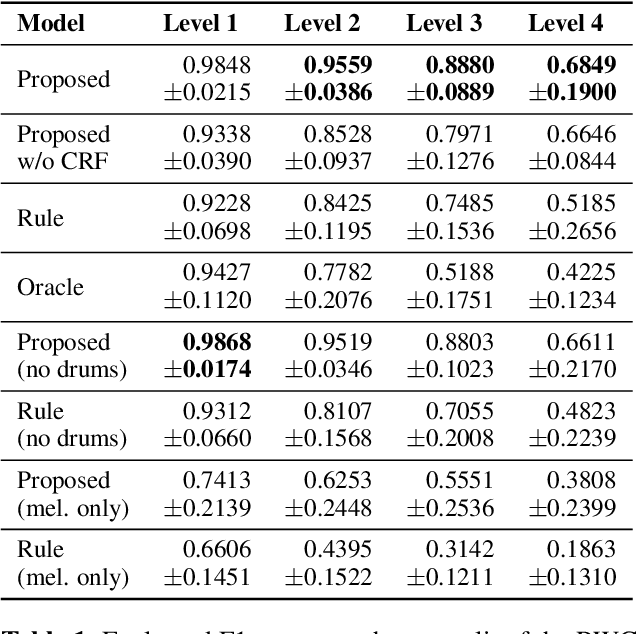
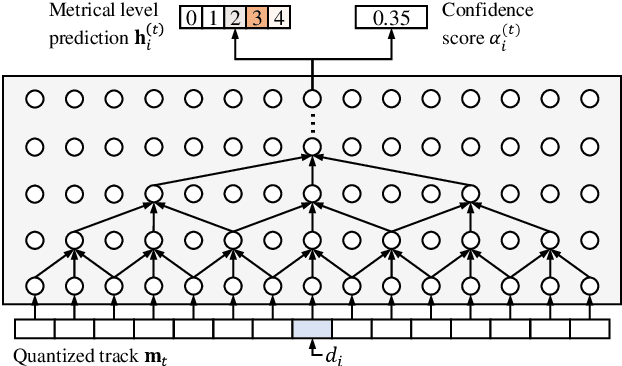
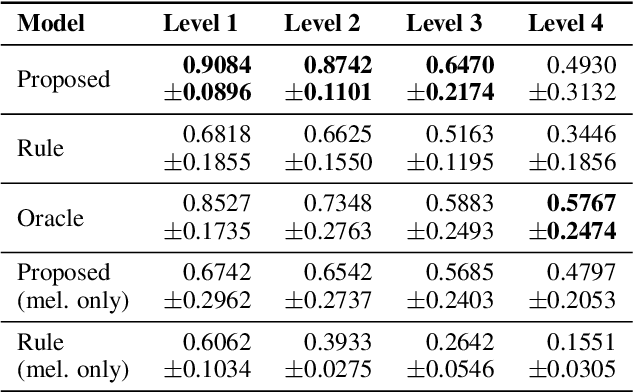
Music contains hierarchical structures beyond beats and measures. While hierarchical structure annotations are helpful for music information retrieval and computer musicology, such annotations are scarce in current digital music databases. In this paper, we explore a data-driven approach to automatically extract hierarchical metrical structures from scores. We propose a new model with a Temporal Convolutional Network-Conditional Random Field (TCN-CRF) architecture. Given a symbolic music score, our model takes in an arbitrary number of voices in a beat-quantized form, and predicts a 4-level hierarchical metrical structure from downbeat-level to section-level. We also annotate a dataset using RWC-POP MIDI files to facilitate training and evaluation. We show by experiments that the proposed method performs better than the rule-based approach under different orchestration settings. We also perform some simple musicological analysis on the model predictions. All demos, datasets and pre-trained models are publicly available on Github.
Measuring a Six-hole Recorder Flute's Response to Breath Pressure Variations and Fitting a Model
Jul 19, 2021

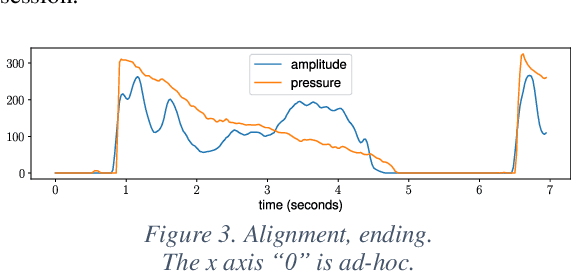
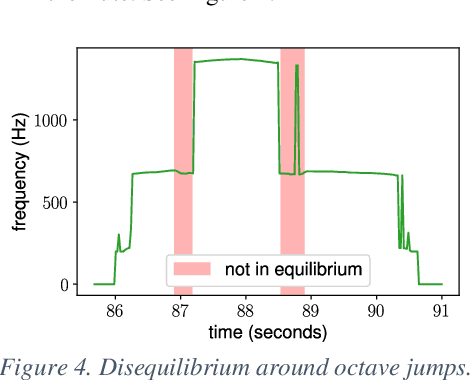
We propose the Siamese-flute method that measures the breath pressure and the acoustic sound in parallel. We fit a 6-DoF model to describe how the breath pressure affects the octave and the microtonal pitch bend, revealing the octave hysteresis. We release both our model parameters and our data analysis tools.