 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Model for Zero-shot Music Source Separation, Transcription and Synthesis
Paper and Code
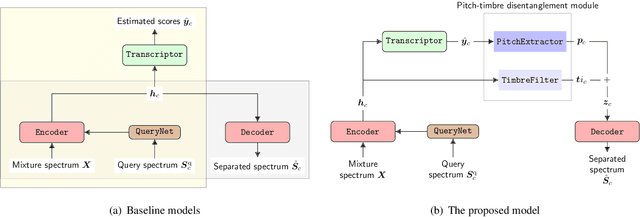

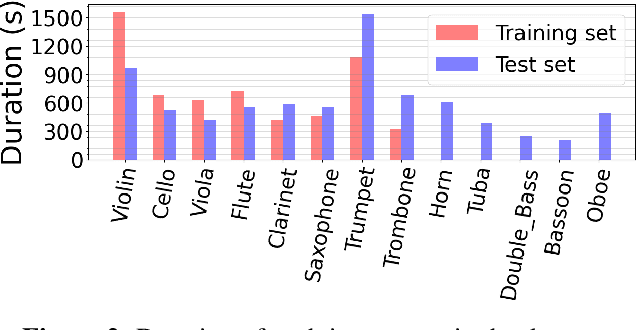
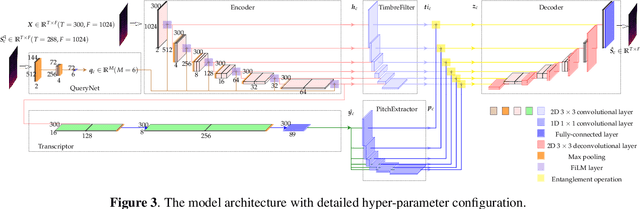
We propose a unified model for three inter-related tasks: 1) to \textit{separate} individual sound sources from a mixed music audio, 2) to \textit{transcribe} each sound source to MIDI notes, and 3) to\textit{ synthesize} new pieces based on the timbre of separated sources. The model is inspired by the fact that when humans listen to music, our minds can not only separate the sounds of different instruments, but also at the same time perceive high-level representations such as score and timbre. To mirror such capability computationally, we designed a pitch-timbre disentanglement module based on a popular encoder-decoder neural architecture for source separation. The key inductive biases are vector-quantization for pitch representation and pitch-transformation invariant for timbre representation. In addition, we adopted a query-by-example method to achieve \textit{zero-shot} learning, i.e., the model is capable of doing source separation, transcription, and synthesis for \textit{unseen} instruments. The current design focuses on audio mixtures of two monophonic instruments. Experimental results show that our model outperforms existing multi-task baselines, and the transcribed score serves as a powerful auxiliary for separation tasks.