 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultivariate Variational Autoencoder
Nov 08, 2025



We present the Multivariate Variational Autoencoder (MVAE), a VAE variant that preserves Gaussian tractability while lifting the diagonal posterior restriction. MVAE factorizes each posterior covariance, where a \emph{global} coupling matrix $\mathbf{C}$ induces dataset-wide latent correlations and \emph{per-sample} diagonal scales modulate local uncertainty. This yields a full-covariance family with analytic KL and an efficient reparameterization via $\mathbf{L}=\mathbf{C}\mathrm{diag}(\boldsymbolσ)$. Across Larochelle-style MNIST variants, Fashion-MNIST, CIFAR-10, and CIFAR-100, MVAE consistently matches or improves reconstruction (MSE~$\downarrow$) and delivers robust gains in calibration (NLL/Brier/ECE~$\downarrow$) and unsupervised structure (NMI/ARI~$\uparrow$) relative to diagonal-covariance VAEs with matched capacity, especially at mid-range latent sizes. Latent-plane visualizations further indicate smoother, more coherent factor traversals and sharper local detail. We release a fully reproducible implementation with training/evaluation scripts and sweep utilities to facilitate fair comparison and reuse.
Geopolitical Parallax: Beyond Walter Lippmann Just After Large Language Models
Aug 27, 2025



Objectivity in journalism has long been contested, oscillating between ideals of neutral, fact-based reporting and the inevitability of subjective framing. With the advent of large language models (LLMs), these tensions are now mediated by algorithmic systems whose training data and design choices may themselves embed cultural or ideological biases. This study investigates geopolitical parallax-systematic divergence in news quality and subjectivity assessments-by comparing article-level embeddings from Chinese-origin (Qwen, BGE, Jina) and Western-origin (Snowflake, Granite) model families. We evaluate both on a human-annotated news quality benchmark spanning fifteen stylistic, informational, and affective dimensions, and on parallel corpora covering politically sensitive topics, including Palestine and reciprocal China-United States coverage. Using logistic regression probes and matched-topic evaluation, we quantify per-metric differences in predicted positive-class probabilities between model families. Our findings reveal consistent, non-random divergences aligned with model origin. In Palestine-related coverage, Western models assign higher subjectivity and positive emotion scores, while Chinese models emphasize novelty and descriptiveness. Cross-topic analysis shows asymmetries in structural quality metrics Chinese-on-US scoring notably lower in fluency, conciseness, technicality, and overall quality-contrasted by higher negative emotion scores. These patterns align with media bias theory and our distinction between semantic, emotional, and relational subjectivity, and extend LLM bias literature by showing that geopolitical framing effects persist in downstream quality assessment tasks. We conclude that LLM-based media evaluation pipelines require cultural calibration to avoid conflating content differences with model-induced bias.
Variational Self-Supervised Learning
Apr 06, 2025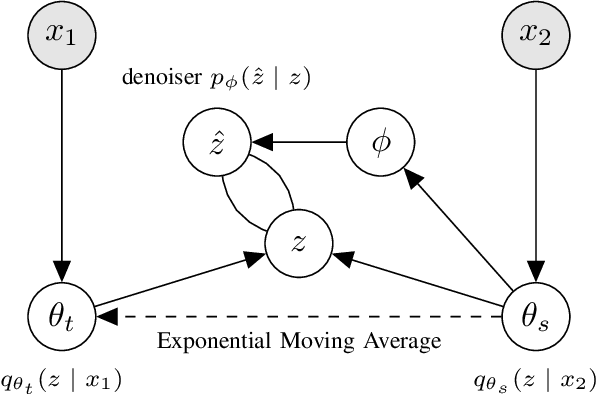
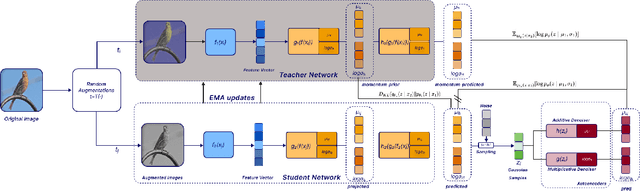
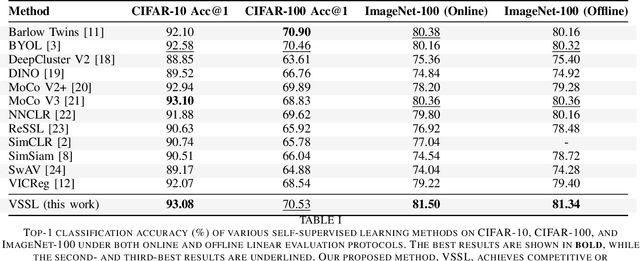
We present Variational Self-Supervised Learning (VSSL), a novel framework that combines variational inference with self-supervised learning to enable efficient, decoder-free representation learning. Unlike traditional VAEs that rely on input reconstruction via a decoder, VSSL symmetrically couples two encoders with Gaussian outputs. A momentum-updated teacher network defines a dynamic, data-dependent prior, while the student encoder produces an approximate posterior from augmented views. The reconstruction term in the ELBO is replaced with a cross-view denoising objective, preserving the analytical tractability of Gaussian KL divergence. We further introduce cosine-based formulations of KL and log-likelihood terms to enhance semantic alignment in high-dimensional latent spaces. Experiments on CIFAR-10, CIFAR-100, and ImageNet-100 show that VSSL achieves competitive or superior performance to leading self-supervised methods, including BYOL and MoCo V3. VSSL offers a scalable, probabilistically grounded approach to learning transferable representations without generative reconstruction, bridging the gap between variational modeling and modern self-supervised techniques.
RadGPT: Constructing 3D Image-Text Tumor Datasets
Jan 08, 2025With over 85 million CT scans performed annually in the United States, creating tumor-related reports is a challenging and time-consuming task for radiologists. To address this need, we present RadGPT, an Anatomy-Aware Vision-Language AI Agent for generating detailed reports from CT scans. RadGPT first segments tumors, including benign cysts and malignant tumors, and their surrounding anatomical structures, then transforms this information into both structured reports and narrative reports. These reports provide tumor size, shape, location, attenuation, volume, and interactions with surrounding blood vessels and organs. Extensive evaluation on unseen hospitals shows that RadGPT can produce accurate reports, with high sensitivity/specificity for small tumor (<2 cm) detection: 80/73% for liver tumors, 92/78% for kidney tumors, and 77/77% for pancreatic tumors. For large tumors, sensitivity ranges from 89% to 97%. The results significantly surpass the state-of-the-art in abdominal CT report generation. RadGPT generated reports for 17 public datasets. Through radiologist review and refinement, we have ensured the reports' accuracy, and created the first publicly available image-text 3D medical dataset, comprising over 1.8 million text tokens and 2.7 million images from 9,262 CT scans, including 2,947 tumor scans/reports of 8,562 tumor instances. Our reports can: (1) localize tumors in eight liver sub-segments and three pancreatic sub-segments annotated per-voxel; (2) determine pancreatic tumor stage (T1-T4) in 260 reports; and (3) present individual analyses of multiple tumors--rare in human-made reports. Importantly, 948 of the reports are for early-stage tumors.
Cross-D Conv: Cross-Dimensional Transferable Knowledge Base via Fourier Shifting Operation
Nov 02, 2024In biomedical imaging analysis, the dichotomy between 2D and 3D data presents a significant challenge. While 3D volumes offer superior real-world applicability, they are less available for each modality and not easy to train in large scale, whereas 2D samples are abundant but less comprehensive. This paper introduces the Cross-D Conv operation, a novel approach that bridges the dimensional gap by learning the phase shifting in the Fourier domain. Our method enables seamless weight transfer between 2D and 3D convolution operations, effectively facilitating cross-dimensional learning. The proposed architecture leverages the abundance of 2D training data to enhance 3D model performance, offering a practical solution to the multimodal data scarcity challenge in 3D medical model pretraining. Experimental validation on the RadImagenet (2D) and multimodal (3D) sets demonstrates that our approach achieves comparable or superior performance in feature quality assessment comparable to conventional methods. The enhanced convolution operation presents new opportunities for developing efficient classification and segmentation models in medical imaging. This work represents an advancement in cross-dimensional and multi-modal medical image analysis, offering a robust framework for utilizing 2D priors in 3D model pretraining or vice versa while maintaining computational efficiency.
Universal and Extensible Language-Vision Models for Organ Segmentation and Tumor Detection from Abdominal Computed Tomography
May 28, 2024



The advancement of artificial intelligence (AI) for organ segmentation and tumor detection is propelled by the growing availability of computed tomography (CT) datasets with detailed, per-voxel annotations. However, these AI models often struggle with flexibility for partially annotated datasets and extensibility for new classes due to limitations in the one-hot encoding, architectural design, and learning scheme. To overcome these limitations, we propose a universal, extensible framework enabling a single model, termed Universal Model, to deal with multiple public datasets and adapt to new classes (e.g., organs/tumors). Firstly, we introduce a novel language-driven parameter generator that leverages language embeddings from large language models, enriching semantic encoding compared with one-hot encoding. Secondly, the conventional output layers are replaced with lightweight, class-specific heads, allowing Universal Model to simultaneously segment 25 organs and six types of tumors and ease the addition of new classes. We train our Universal Model on 3,410 CT volumes assembled from 14 publicly available datasets and then test it on 6,173 CT volumes from four external datasets. Universal Model achieves first place on six CT tasks in the Medical Segmentation Decathlon (MSD) public leaderboard and leading performance on the Beyond The Cranial Vault (BTCV) dataset. In summary, Universal Model exhibits remarkable computational efficiency (6x faster than other dataset-specific models), demonstrates strong generalization across different hospitals, transfers well to numerous downstream tasks, and more importantly, facilitates the extensibility to new classes while alleviating the catastrophic forgetting of previously learned classes. Codes, models, and datasets are available at https://github.com/ljwztc/CLIP-Driven-Universal-Model
COVID-19 Detection in Computed Tomography Images with 2D and 3D Approaches
May 20, 2021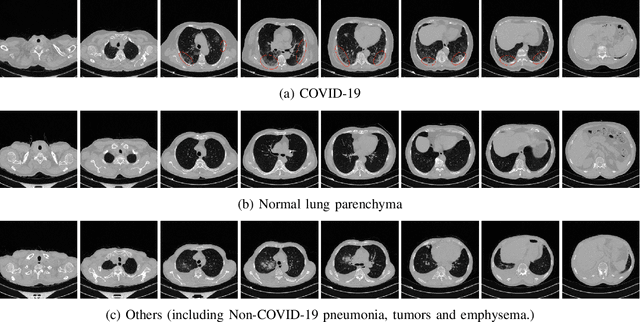
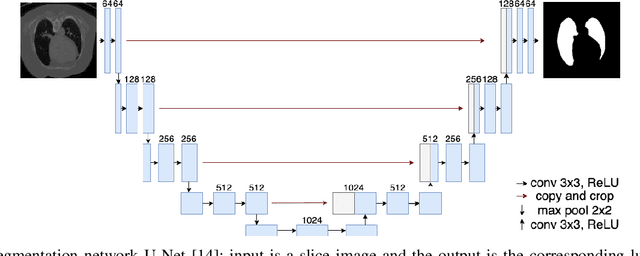
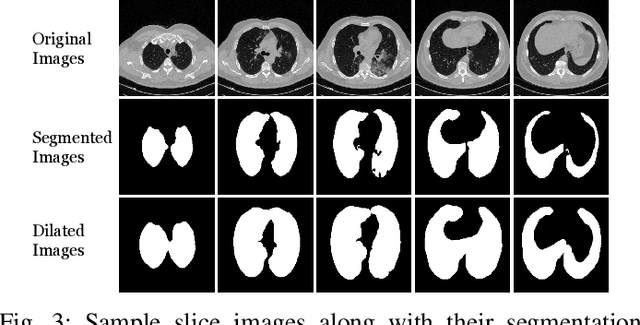
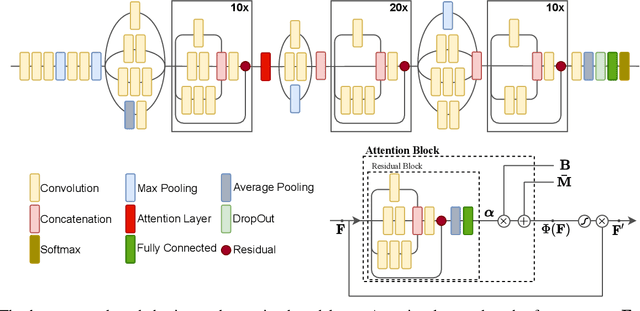
Detecting COVID-19 in computed tomography (CT) or radiography images has been proposed as a supplement to the definitive RT-PCR test. We present a deep learning ensemble for detecting COVID-19 infection, combining slice-based (2D) and volume-based (3D) approaches. The 2D system detects the infection on each CT slice independently, combining them to obtain the patient-level decision via different methods (averaging and long-short term memory networks). The 3D system takes the whole CT volume to arrive to the patient-level decision in one step. A new high resolution chest CT scan dataset, called the IST-C dataset, is also collected in this work. The proposed ensemble, called IST-CovNet, obtains 90.80% accuracy and 0.95 AUC score overall on the IST-C dataset in detecting COVID-19 among normal controls and other types of lung pathologies; and 93.69% accuracy and 0.99 AUC score on the publicly available MosMed dataset that consists of COVID-19 scans and normal controls only. The system is deployed at Istanbul University Cerrahpasa School of Medicine.