 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Self-Supervised Learning
Apr 06, 2025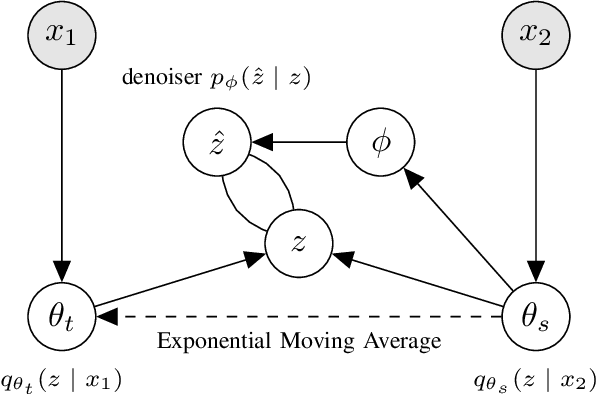
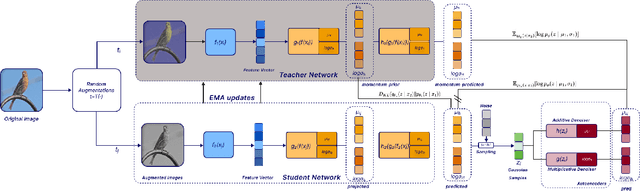
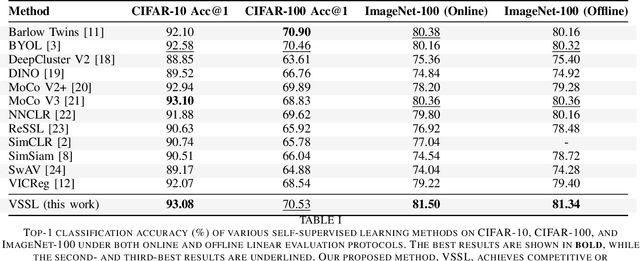
We present Variational Self-Supervised Learning (VSSL), a novel framework that combines variational inference with self-supervised learning to enable efficient, decoder-free representation learning. Unlike traditional VAEs that rely on input reconstruction via a decoder, VSSL symmetrically couples two encoders with Gaussian outputs. A momentum-updated teacher network defines a dynamic, data-dependent prior, while the student encoder produces an approximate posterior from augmented views. The reconstruction term in the ELBO is replaced with a cross-view denoising objective, preserving the analytical tractability of Gaussian KL divergence. We further introduce cosine-based formulations of KL and log-likelihood terms to enhance semantic alignment in high-dimensional latent spaces. Experiments on CIFAR-10, CIFAR-100, and ImageNet-100 show that VSSL achieves competitive or superior performance to leading self-supervised methods, including BYOL and MoCo V3. VSSL offers a scalable, probabilistically grounded approach to learning transferable representations without generative reconstruction, bridging the gap between variational modeling and modern self-supervised techniques.
Dealing with Annotator Disagreement in Hate Speech Classification
Feb 12, 2025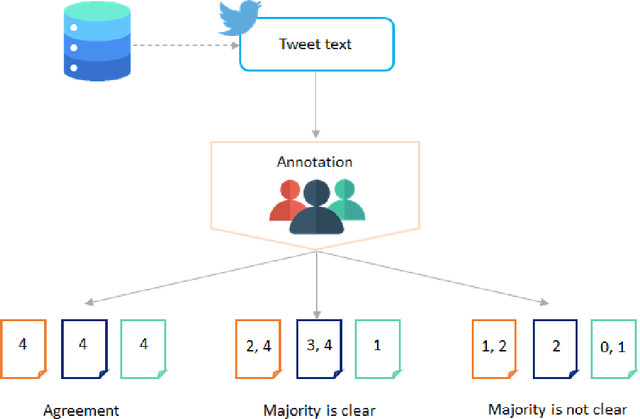
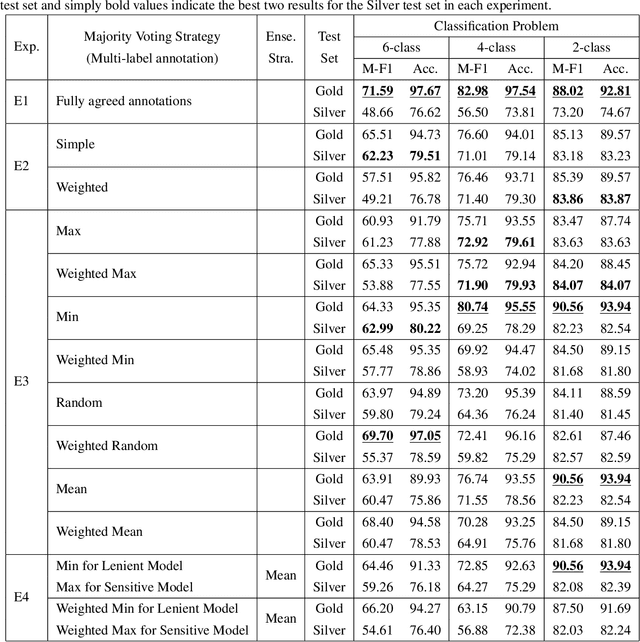
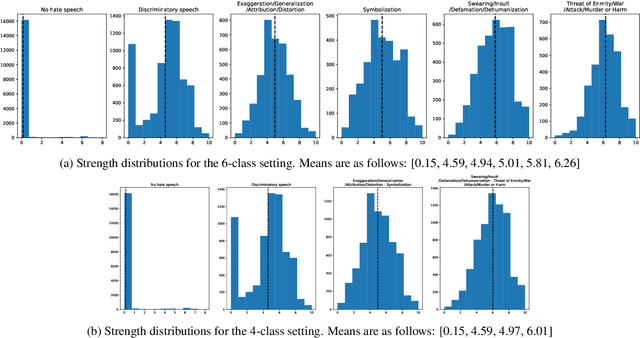
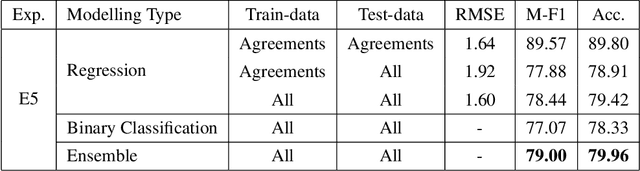
Hate speech detection is a crucial task, especially on social media, where harmful content can spread quickly. Implementing machine learning models to automatically identify and address hate speech is essential for mitigating its impact and preventing its proliferation. The first step in developing an effective hate speech detection model is to acquire a high-quality dataset for training. Labeled data is foundational for most natural language processing tasks, but categorizing hate speech is difficult due to the diverse and often subjective nature of hate speech, which can lead to varying interpretations and disagreements among annotators. This paper examines strategies for addressing annotator disagreement, an issue that has been largely overlooked. In particular, we evaluate different approaches to deal with annotator disagreement regarding hate speech classification in Turkish tweets, based on a fine-tuned BERT model. Our work highlights the importance of the problem and provides state-of-art benchmark results for detection and understanding of hate speech in online discourse.
Going Forward-Forward in Distributed Deep Learning
Mar 30, 2024
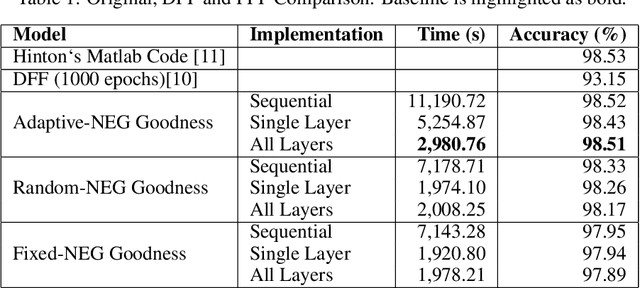
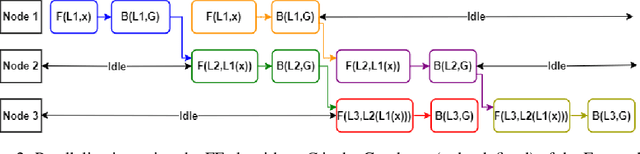

This paper introduces a new approach in distributed deep learning, utilizing Geoffrey Hinton's Forward-Forward (FF) algorithm to enhance the training of neural networks in distributed computing environments. Unlike traditional methods that rely on forward and backward passes, the FF algorithm employs a dual forward pass strategy, significantly diverging from the conventional backpropagation process. This novel method aligns more closely with the human brain's processing mechanisms, potentially offering a more efficient and biologically plausible approach to neural network training. Our research explores the implementation of the FF algorithm in distributed settings, focusing on its capability to facilitate parallel training of neural network layers. This parallelism aims to reduce training times and resource consumption, thereby addressing some of the inherent challenges in current distributed deep learning systems. By analyzing the effectiveness of the FF algorithm in distributed computing, we aim to demonstrate its potential as a transformative tool in distributed deep learning systems, offering improvements in training efficiency. The integration of the FF algorithm into distributed deep learning represents a significant step forward in the field, potentially revolutionizing the way neural networks are trained in distributed environments.
CNN-BiLSTM model for English Handwriting Recognition: Comprehensive Evaluation on the IAM Dataset
Jul 02, 2023We present a CNN-BiLSTM system for the problem of offline English handwriting recognition, with extensive evaluations on the public IAM dataset, including the effects of model size, data augmentation and the lexicon. Our best model achieves 3.59\% CER and 9.44\% WER using CNN-BiLSTM network with CTC layer. Test time augmentation with rotation and shear transformations applied to the input image, is proposed to increase recognition of difficult cases and found to reduce the word error rate by 2.5\% points. We also conduct an error analysis of our proposed method on IAM dataset, show hard cases of handwriting images and explore samples with erroneous labels. We provide our source code as public-domain, to foster further research to encourage scientific reproducibility.
Real or Virtual: A Video Conferencing Background Manipulation-Detection System
Apr 25, 2022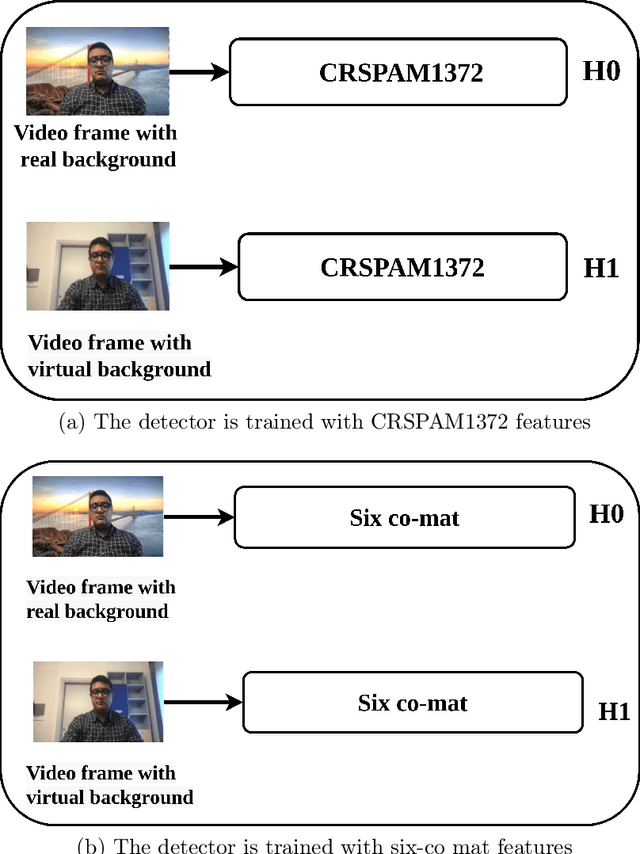
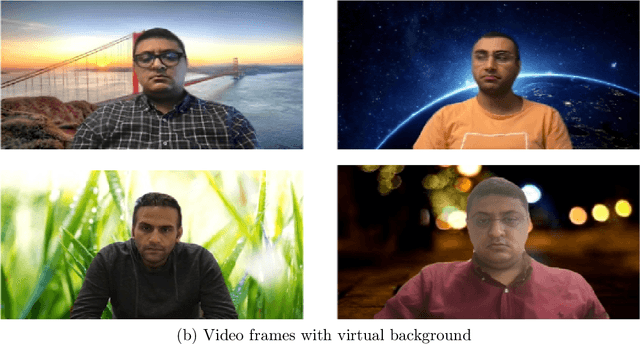

Recently, the popularity and wide use of the last-generation video conferencing technologies created an exponential growth in its market size. Such technology allows participants in different geographic regions to have a virtual face-to-face meeting. Additionally, it enables users to employ a virtual background to conceal their own environment due to privacy concerns or to reduce distractions, particularly in professional settings. Nevertheless, in scenarios where the users should not hide their actual locations, they may mislead other participants by claiming their virtual background as a real one. Therefore, it is crucial to develop tools and strategies to detect the authenticity of the considered virtual background. In this paper, we present a detection strategy to distinguish between real and virtual video conferencing user backgrounds. We demonstrate that our detector is robust against two attack scenarios. The first scenario considers the case where the detector is unaware about the attacks and inn the second scenario, we make the detector aware of the adversarial attacks, which we refer to Adversarial Multimedia Forensics (i.e, the forensically-edited frames are included in the training set). Given the lack of publicly available dataset of virtual and real backgrounds for video conferencing, we created our own dataset and made them publicly available [1]. Then, we demonstrate the robustness of our detector against different adversarial attacks that the adversary considers. Ultimately, our detector's performance is significant against the CRSPAM1372 [2] features, and post-processing operations such as geometric transformations with different quality factors that the attacker may choose. Moreover, our performance results shows that we can perfectly identify a real from a virtual background with an accuracy of 99.80%.
COVID-19 Detection in Computed Tomography Images with 2D and 3D Approaches
May 20, 2021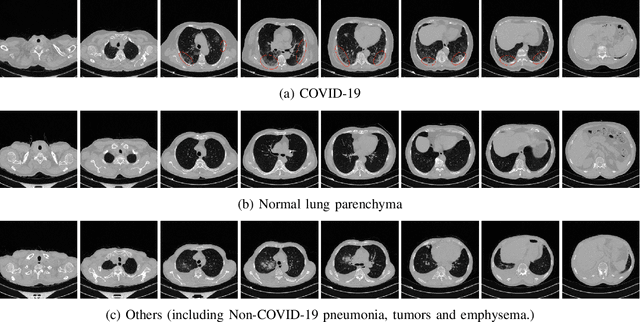
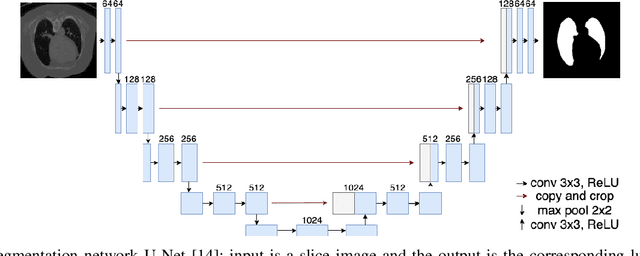
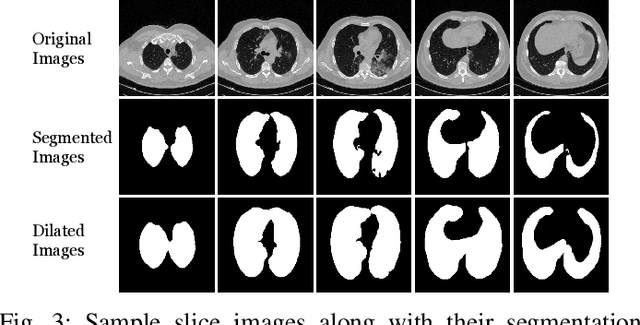
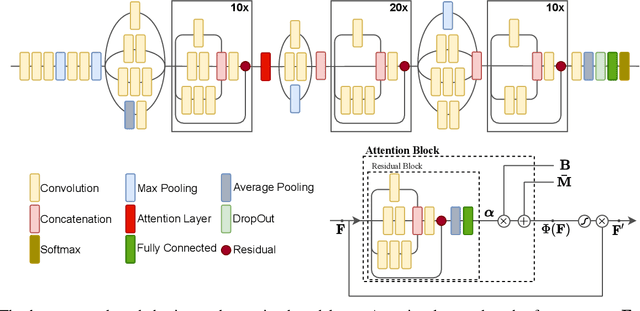
Detecting COVID-19 in computed tomography (CT) or radiography images has been proposed as a supplement to the definitive RT-PCR test. We present a deep learning ensemble for detecting COVID-19 infection, combining slice-based (2D) and volume-based (3D) approaches. The 2D system detects the infection on each CT slice independently, combining them to obtain the patient-level decision via different methods (averaging and long-short term memory networks). The 3D system takes the whole CT volume to arrive to the patient-level decision in one step. A new high resolution chest CT scan dataset, called the IST-C dataset, is also collected in this work. The proposed ensemble, called IST-CovNet, obtains 90.80% accuracy and 0.95 AUC score overall on the IST-C dataset in detecting COVID-19 among normal controls and other types of lung pathologies; and 93.69% accuracy and 0.99 AUC score on the publicly available MosMed dataset that consists of COVID-19 scans and normal controls only. The system is deployed at Istanbul University Cerrahpasa School of Medicine.
Relative Attribute Classification with Deep Rank SVM
Sep 09, 2020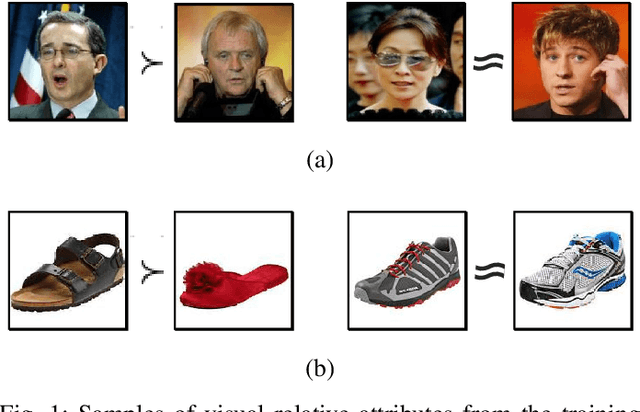
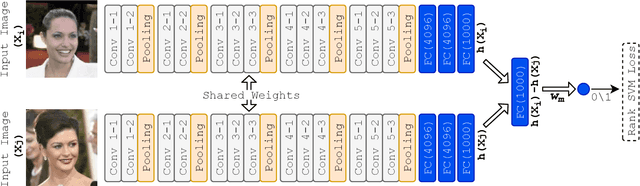

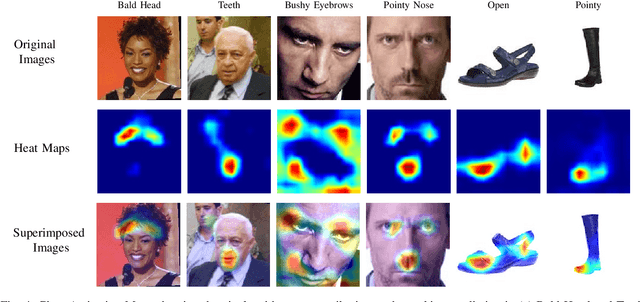
Relative attributes indicate the strength of a particular attribute between image pairs. We introduce a deep Siamese network with rank SVM loss function, called Deep Rank SVM (DRSVM), in order to decide which one of a pair of images has a stronger presence of a specific attribute. The network is trained in an end-to-end fashion to jointly learn the visual features and the ranking function. We demonstrate the effectiveness of our approach against the state-of-the-art methods on four image benchmark datasets: LFW-10, PubFig, UTZap50K-lexi and UTZap50K-2 datasets. DRSVM surpasses state-of-art in terms of the average accuracy across attributes, on three of the four image benchmark datasets.
ECOC as a Method of Constructing Deep Convolutional Neural Network Ensembles
Sep 07, 2020
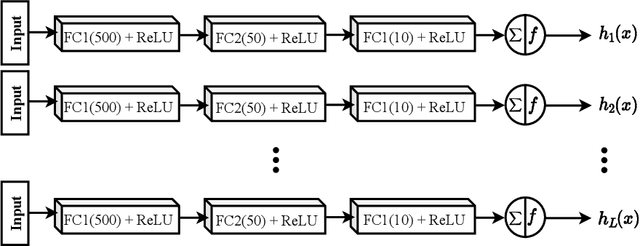
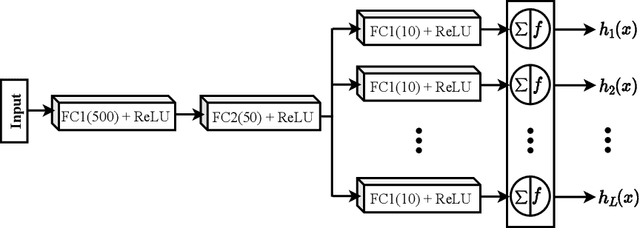
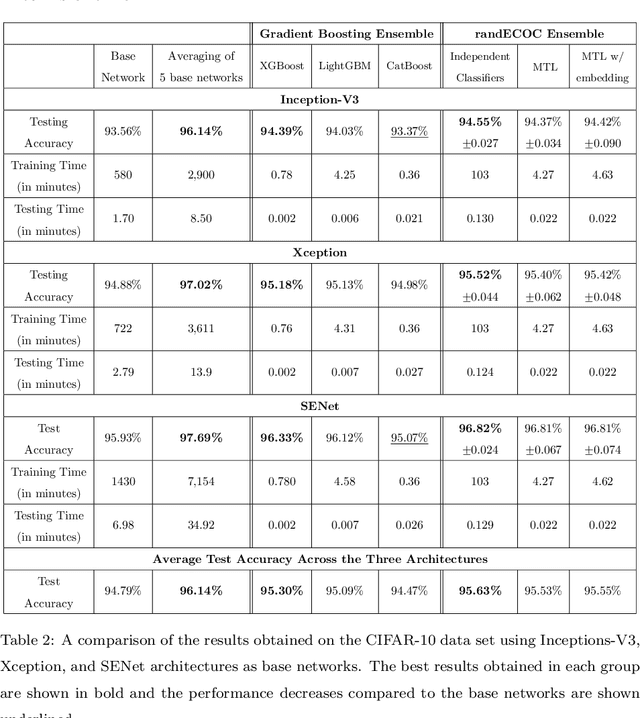
Deep neural networks have enhanced the performance of decision making systems in many applications including image understanding, and further gains can be achieved by constructing ensembles. However, designing an ensemble of deep networks is often not very beneficial since the time needed to train the constituent networks is very high or the performance gain obtained is not very significant. In this paper, we analyse error correcting output coding (ECOC) framework to be used as an ensemble technique for deep networks and propose different design strategies to address the accuracy-complexity trade-off. We carry out an extensive comparative study between the introduced ECOC designs and the state-of-the-art ensemble techniques such as ensemble averaging and gradient boosting decision trees. Furthermore, we propose a combinatory technique which is shown to reveal the highest classification performance amongst all.
GMM-Based Synthetic Samples for Classification of Hyperspectral Images With Limited Training Data
Dec 13, 2017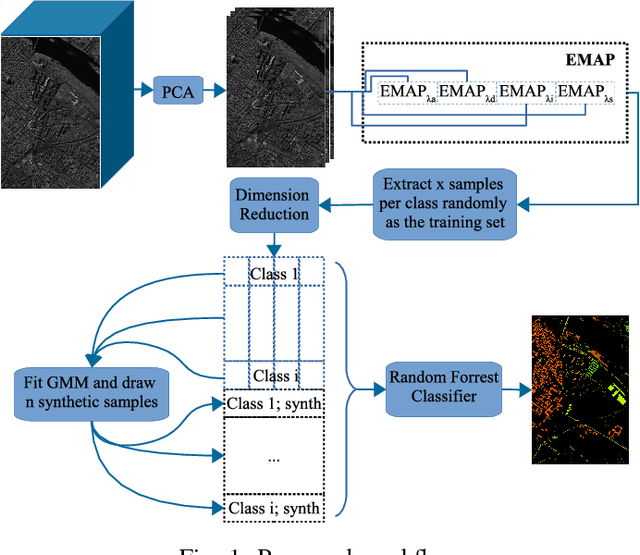
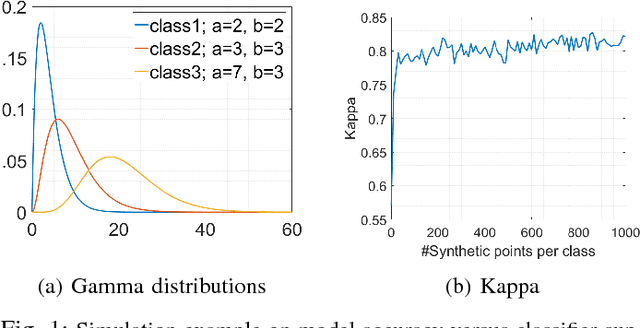
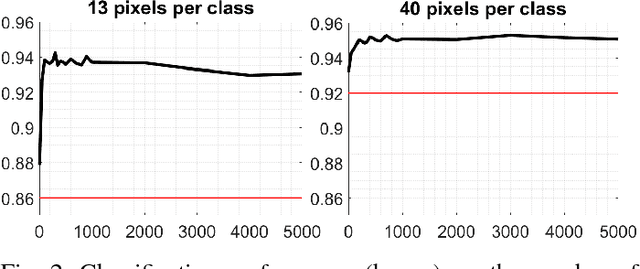
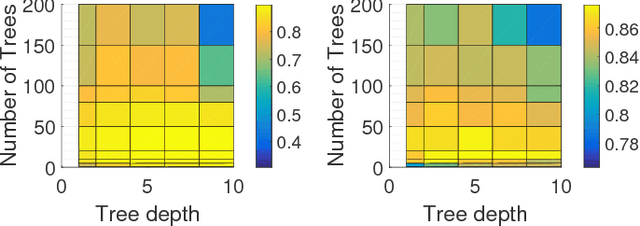
The amount of training data that is required to train a classifier scales with the dimensionality of the feature data. In hyperspectral remote sensing, feature data can potentially become very high dimensional. However, the amount of training data is oftentimes limited. Thus, one of the core challenges in hyperspectral remote sensing is how to perform multi-class classification using only relatively few training data points. In this work, we address this issue by enriching the feature matrix with synthetically generated sample points. This synthetic data is sampled from a GMM fitted to each class of the limited training data. Although, the true distribution of features may not be perfectly modeled by the fitted GMM, we demonstrate that a moderate augmentation by these synthetic samples can effectively replace a part of the missing training samples. We show the efficacy of the proposed approach on two hyperspectral datasets. The median gain in classification performance is $5\%$. It is also encouraging that this performance gain is remarkably stable for large variations in the number of added samples, which makes it much easier to apply this method to real-world applications.