 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPRITZ-1.5C: Employing Deep Ensemble Learning for Improving the Security of Computer Networks against Adversarial Attacks
Sep 25, 2022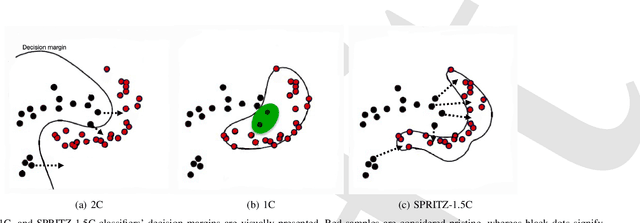
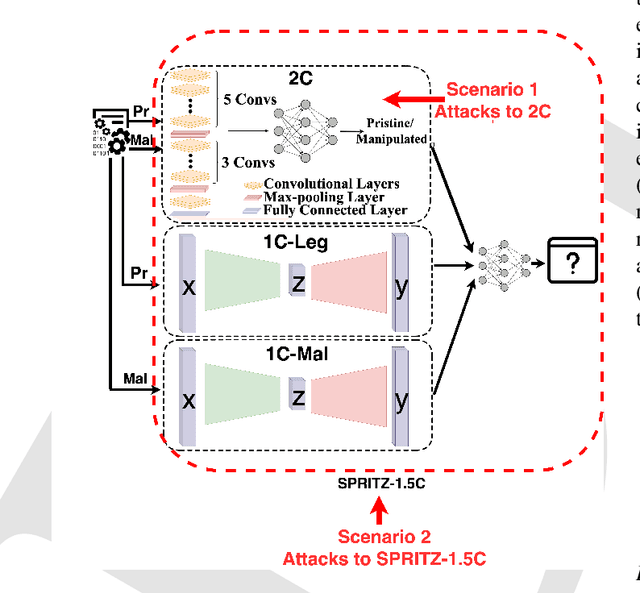
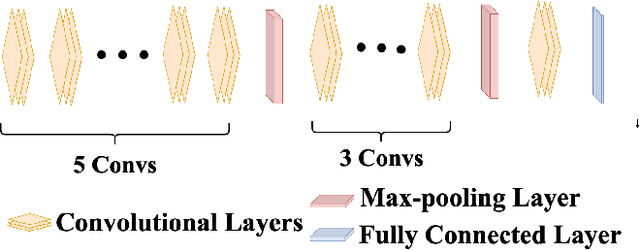
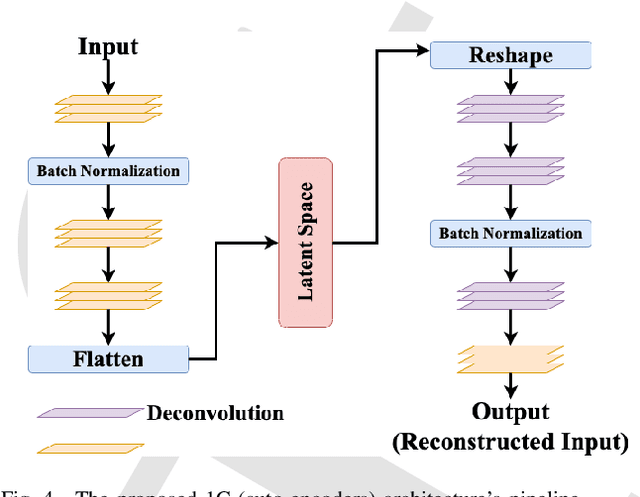
In the past few years, Convolutional Neural Networks (CNN) have demonstrated promising performance in various real-world cybersecurity applications, such as network and multimedia security. However, the underlying fragility of CNN structures poses major security problems, making them inappropriate for use in security-oriented applications including such computer networks. Protecting these architectures from adversarial attacks necessitates using security-wise architectures that are challenging to attack. In this study, we present a novel architecture based on an ensemble classifier that combines the enhanced security of 1-Class classification (known as 1C) with the high performance of conventional 2-Class classification (known as 2C) in the absence of attacks.Our architecture is referred to as the 1.5-Class (SPRITZ-1.5C) classifier and constructed using a final dense classifier, one 2C classifier (i.e., CNNs), and two parallel 1C classifiers (i.e., auto-encoders). In our experiments, we evaluated the robustness of our proposed architecture by considering eight possible adversarial attacks in various scenarios. We performed these attacks on the 2C and SPRITZ-1.5C architectures separately. The experimental results of our study showed that the Attack Success Rate (ASR) of the I-FGSM attack against a 2C classifier trained with the N-BaIoT dataset is 0.9900. In contrast, the ASR is 0.0000 for the SPRITZ-1.5C classifier.
Resisting Deep Learning Models Against Adversarial Attack Transferability via Feature Randomization
Sep 11, 2022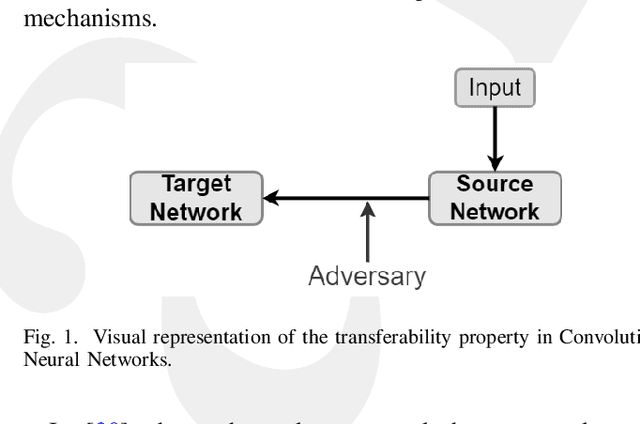
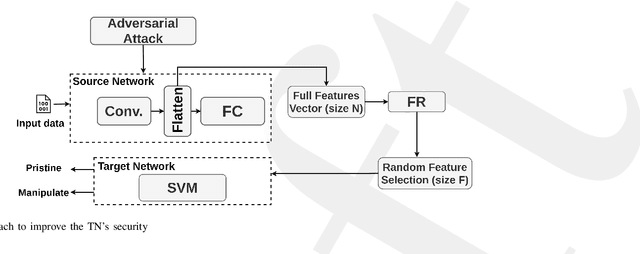

In the past decades, the rise of artificial intelligence has given us the capabilities to solve the most challenging problems in our day-to-day lives, such as cancer prediction and autonomous navigation. However, these applications might not be reliable if not secured against adversarial attacks. In addition, recent works demonstrated that some adversarial examples are transferable across different models. Therefore, it is crucial to avoid such transferability via robust models that resist adversarial manipulations. In this paper, we propose a feature randomization-based approach that resists eight adversarial attacks targeting deep learning models in the testing phase. Our novel approach consists of changing the training strategy in the target network classifier and selecting random feature samples. We consider the attacker with a Limited-Knowledge and Semi-Knowledge conditions to undertake the most prevalent types of adversarial attacks. We evaluate the robustness of our approach using the well-known UNSW-NB15 datasets that include realistic and synthetic attacks. Afterward, we demonstrate that our strategy outperforms the existing state-of-the-art approach, such as the Most Powerful Attack, which consists of fine-tuning the network model against specific adversarial attacks. Finally, our experimental results show that our methodology can secure the target network and resists adversarial attack transferability by over 60%.
Real or Virtual: A Video Conferencing Background Manipulation-Detection System
Apr 25, 2022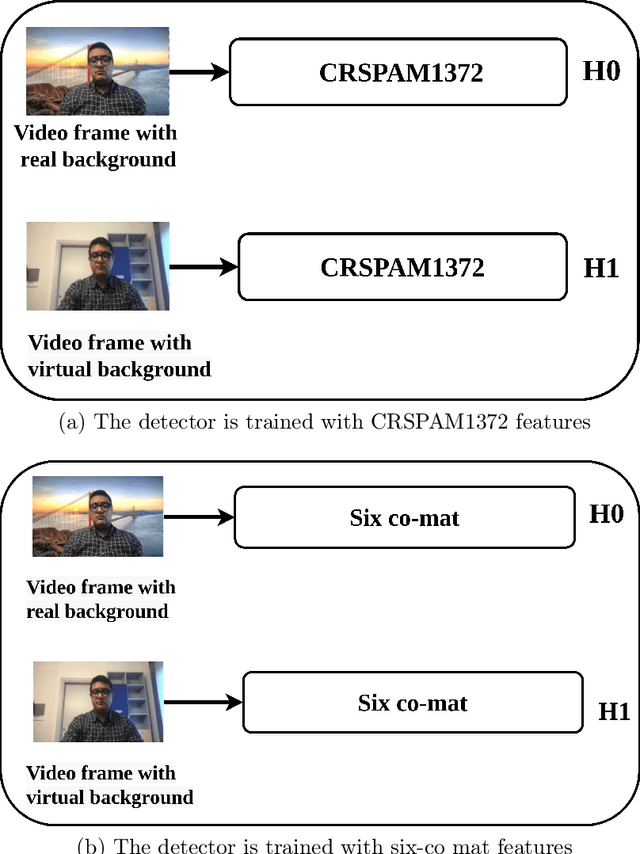
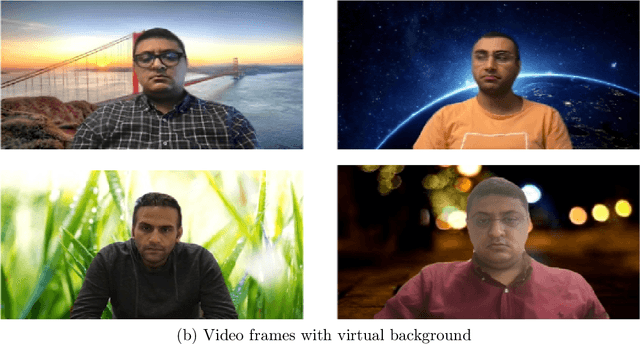

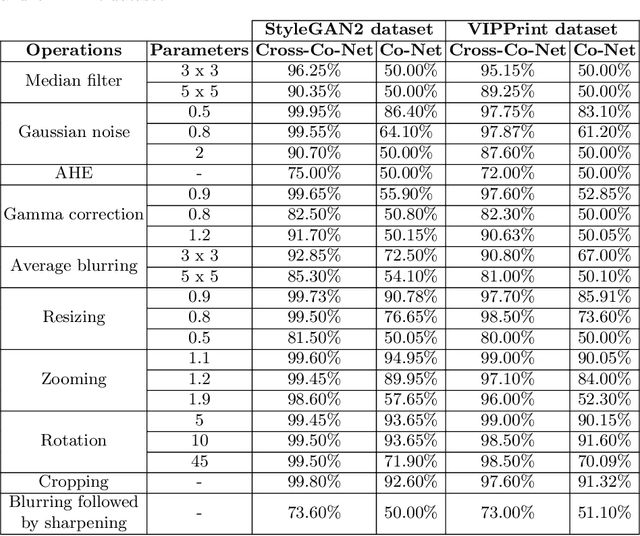
Recently, the popularity and wide use of the last-generation video conferencing technologies created an exponential growth in its market size. Such technology allows participants in different geographic regions to have a virtual face-to-face meeting. Additionally, it enables users to employ a virtual background to conceal their own environment due to privacy concerns or to reduce distractions, particularly in professional settings. Nevertheless, in scenarios where the users should not hide their actual locations, they may mislead other participants by claiming their virtual background as a real one. Therefore, it is crucial to develop tools and strategies to detect the authenticity of the considered virtual background. In this paper, we present a detection strategy to distinguish between real and virtual video conferencing user backgrounds. We demonstrate that our detector is robust against two attack scenarios. The first scenario considers the case where the detector is unaware about the attacks and inn the second scenario, we make the detector aware of the adversarial attacks, which we refer to Adversarial Multimedia Forensics (i.e, the forensically-edited frames are included in the training set). Given the lack of publicly available dataset of virtual and real backgrounds for video conferencing, we created our own dataset and made them publicly available [1]. Then, we demonstrate the robustness of our detector against different adversarial attacks that the adversary considers. Ultimately, our detector's performance is significant against the CRSPAM1372 [2] features, and post-processing operations such as geometric transformations with different quality factors that the attacker may choose. Moreover, our performance results shows that we can perfectly identify a real from a virtual background with an accuracy of 99.80%.
Detecting High-Quality GAN-Generated Face Images using Neural Networks
Mar 03, 2022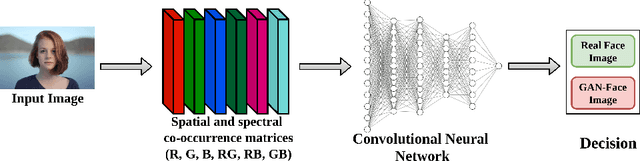


In the past decades, the excessive use of the last-generation GAN (Generative Adversarial Networks) models in computer vision has enabled the creation of artificial face images that are visually indistinguishable from genuine ones. These images are particularly used in adversarial settings to create fake social media accounts and other fake online profiles. Such malicious activities can negatively impact the trustworthiness of users identities. On the other hand, the recent development of GAN models may create high-quality face images without evidence of spatial artifacts. Therefore, reassembling uniform color channel correlations is a challenging research problem. To face these challenges, we need to develop efficient tools able to differentiate between fake and authentic face images. In this chapter, we propose a new strategy to differentiate GAN-generated images from authentic images by leveraging spectral band discrepancies, focusing on artificial face image synthesis. In particular, we enable the digital preservation of face images using the Cross-band co-occurrence matrix and spatial co-occurrence matrix. Then, we implement these techniques and feed them to a Convolutional Neural Networks (CNN) architecture to identify the real from artificial faces. Additionally, we show that the performance boost is particularly significant and achieves more than 92% in different post-processing environments. Finally, we provide several research observations demonstrating that this strategy improves a comparable detection method based only on intra-band spatial co-occurrences.
Demystifying the Transferability of Adversarial Attacks in Computer Networks
Oct 09, 2021
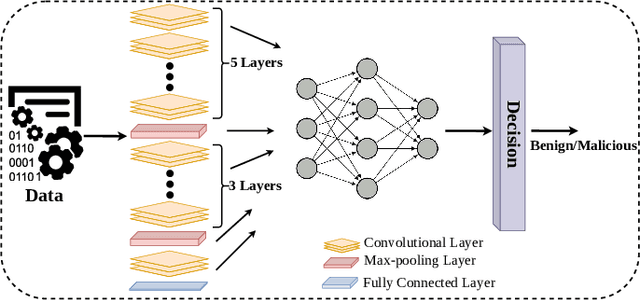
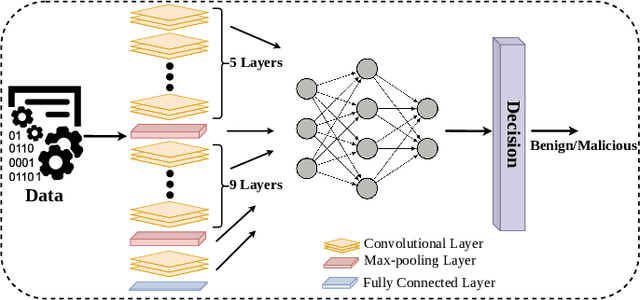

Deep Convolutional Neural Networks (CNN) models are one of the most popular networks in deep learning. With their large fields of application in different areas, they are extensively used in both academia and industry. CNN-based models include several exciting implementations such as early breast cancer detection or detecting developmental delays in children (e.g., autism, speech disorders, etc.). However, previous studies demonstrate that these models are subject to various adversarial attacks. Interestingly, some adversarial examples could potentially still be effective against different unknown models. This particular property is known as adversarial transferability, and prior works slightly analyzed this characteristic in a very limited application domain. In this paper, we aim to demystify the transferability threats in computer networks by studying the possibility of transferring adversarial examples. In particular, we provide the first comprehensive study which assesses the robustness of CNN-based models for computer networks against adversarial transferability. In our experiments, we consider five different attacks: (1) the Iterative Fast Gradient Method (I-FGSM), (2) the Jacobian-based Saliency Map attack (JSMA), (3) the L-BFGS attack, (4) the Projected Gradient Descent attack (PGD), and (5) the DeepFool attack. These attacks are performed against two well-known datasets: the N-BaIoT dataset and the Domain Generating Algorithms (DGA) dataset. Our results show that the transferability happens in specific use cases where the adversary can easily compromise the victim's network with very few knowledge of the targeted model.