 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResisting Deep Learning Models Against Adversarial Attack Transferability via Feature Randomization
Sep 11, 2022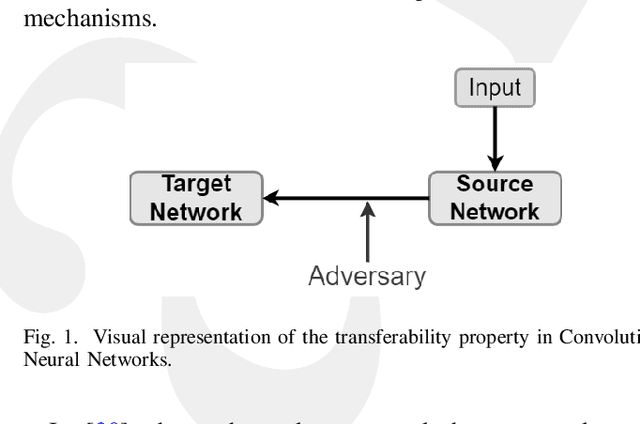
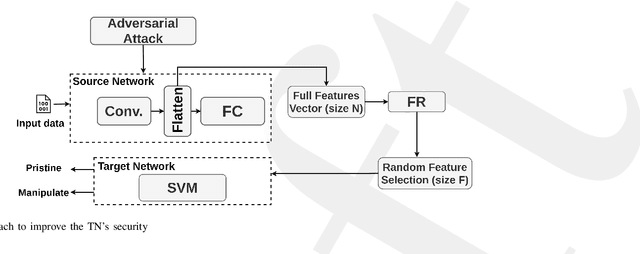

In the past decades, the rise of artificial intelligence has given us the capabilities to solve the most challenging problems in our day-to-day lives, such as cancer prediction and autonomous navigation. However, these applications might not be reliable if not secured against adversarial attacks. In addition, recent works demonstrated that some adversarial examples are transferable across different models. Therefore, it is crucial to avoid such transferability via robust models that resist adversarial manipulations. In this paper, we propose a feature randomization-based approach that resists eight adversarial attacks targeting deep learning models in the testing phase. Our novel approach consists of changing the training strategy in the target network classifier and selecting random feature samples. We consider the attacker with a Limited-Knowledge and Semi-Knowledge conditions to undertake the most prevalent types of adversarial attacks. We evaluate the robustness of our approach using the well-known UNSW-NB15 datasets that include realistic and synthetic attacks. Afterward, we demonstrate that our strategy outperforms the existing state-of-the-art approach, such as the Most Powerful Attack, which consists of fine-tuning the network model against specific adversarial attacks. Finally, our experimental results show that our methodology can secure the target network and resists adversarial attack transferability by over 60%.