 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Transferability of Adversarial Attacks in Computer Networks
Oct 09, 2021
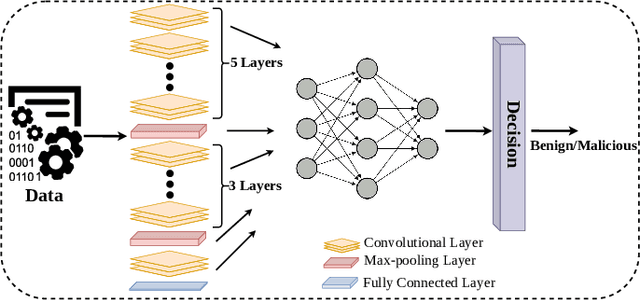
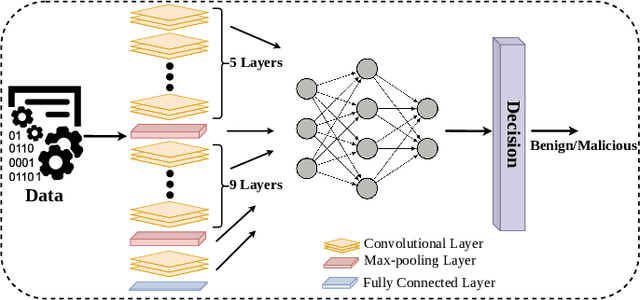

Deep Convolutional Neural Networks (CNN) models are one of the most popular networks in deep learning. With their large fields of application in different areas, they are extensively used in both academia and industry. CNN-based models include several exciting implementations such as early breast cancer detection or detecting developmental delays in children (e.g., autism, speech disorders, etc.). However, previous studies demonstrate that these models are subject to various adversarial attacks. Interestingly, some adversarial examples could potentially still be effective against different unknown models. This particular property is known as adversarial transferability, and prior works slightly analyzed this characteristic in a very limited application domain. In this paper, we aim to demystify the transferability threats in computer networks by studying the possibility of transferring adversarial examples. In particular, we provide the first comprehensive study which assesses the robustness of CNN-based models for computer networks against adversarial transferability. In our experiments, we consider five different attacks: (1) the Iterative Fast Gradient Method (I-FGSM), (2) the Jacobian-based Saliency Map attack (JSMA), (3) the L-BFGS attack, (4) the Projected Gradient Descent attack (PGD), and (5) the DeepFool attack. These attacks are performed against two well-known datasets: the N-BaIoT dataset and the Domain Generating Algorithms (DGA) dataset. Our results show that the transferability happens in specific use cases where the adversary can easily compromise the victim's network with very few knowledge of the targeted model.