 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit&Splat: Zero-Shot Panoptic Segmentation via Explicit Instance Modeling and 3D Gaussian Splatting
Feb 01, 20263D Gaussian Splatting (GS) enables fast and high-quality scene reconstruction, but it lacks an object-consistent and semantically aware structure. We propose Split&Splat, a framework for panoptic scene reconstruction using 3DGS. Our approach explicitly models object instances. It first propagates instance masks across views using depth, thus producing view-consistent 2D masks. Each object is then reconstructed independently and merged back into the scene while refining its boundaries. Finally, instance-level semantic descriptors are embedded in the reconstructed objects, supporting various applications, including panoptic segmentation, object retrieval, and 3D editing. Unlike existing methods, Split&Splat tackles the problem by first segmenting the scene and then reconstructing each object individually. This design naturally supports downstream tasks and allows Split&Splat to achieve state-of-the-art performance on the ScanNetv2 segmentation benchmark.
MOCHA: Multi-modal Objects-aware Cross-arcHitecture Alignment
Sep 17, 2025We introduce MOCHA (Multi-modal Objects-aware Cross-arcHitecture Alignment), a knowledge distillation approach that transfers region-level multimodal semantics from a large vision-language teacher (e.g., LLaVa) into a lightweight vision-only object detector student (e.g., YOLO). A translation module maps student features into a joint space, where the training of the student and translator is guided by a dual-objective loss that enforces both local alignment and global relational consistency. Unlike prior approaches focused on dense or global alignment, MOCHA operates at the object level, enabling efficient transfer of semantics without modifying the teacher or requiring textual input at inference. We validate our method across four personalized detection benchmarks under few-shot regimes. Results show consistent gains over baselines, with a +10.1 average score improvement. Despite its compact architecture, MOCHA reaches performance on par with larger multimodal models, proving its suitability for real-world deployment.
TeLL Me what you cant see
Mar 25, 2025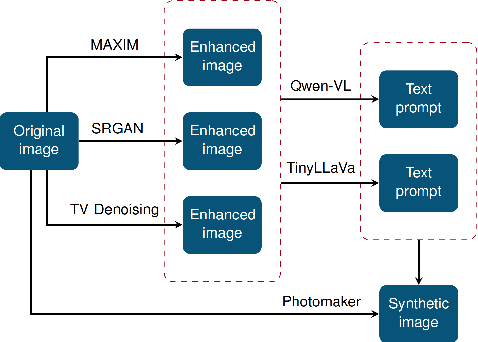

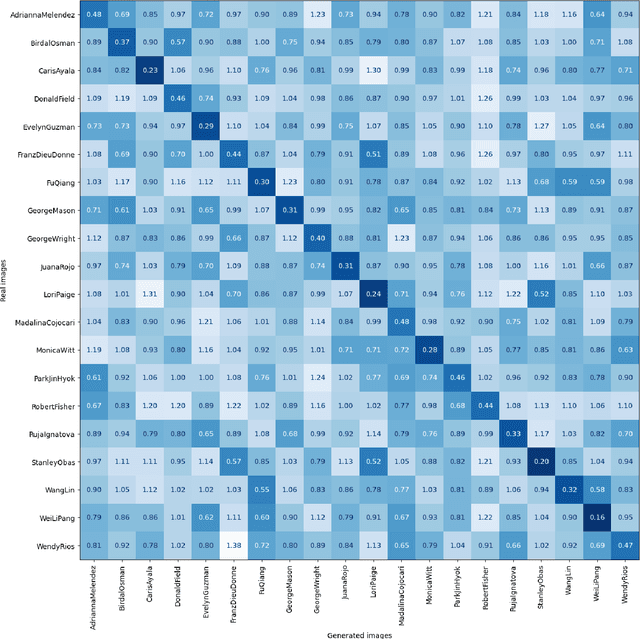
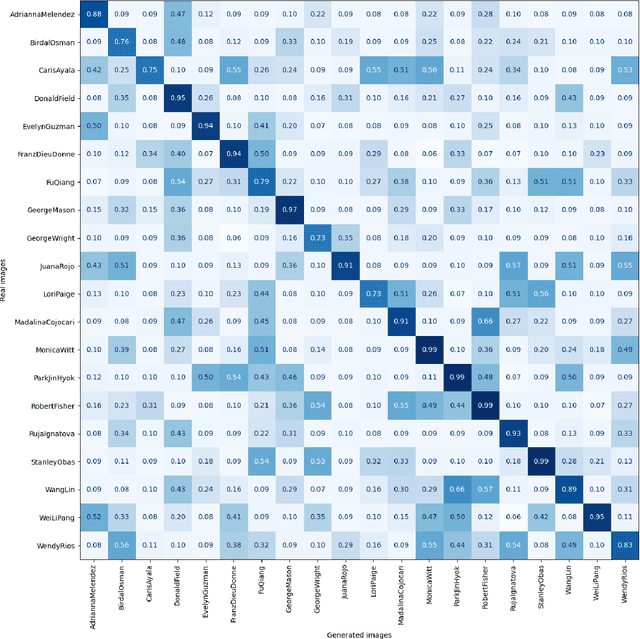
During criminal investigations, images of persons of interest directly influence the success of identification procedures. However, law enforcement agencies often face challenges related to the scarcity of high-quality images or their obsolescence, which can affect the accuracy and success of people searching processes. This paper introduces a novel forensic mugshot augmentation framework aimed at addressing these limitations. Our approach enhances the identification probability of individuals by generating additional, high-quality images through customizable data augmentation techniques, while maintaining the biometric integrity and consistency of the original data. Several experimental results show that our method significantly improves identification accuracy and robustness across various forensic scenarios, demonstrating its effectiveness as a trustworthy tool law enforcement applications. Index Terms: Digital Forensics, Person re-identification, Feature extraction, Data augmentation, Visual-Language models.
SAGE: Semantic-Driven Adaptive Gaussian Splatting in Extended Reality
Mar 20, 2025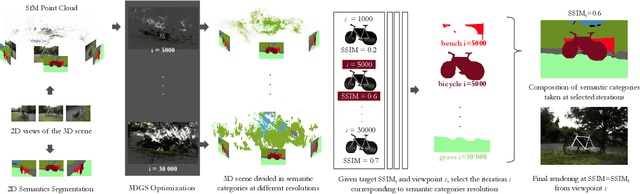

3D Gaussian Splatting (3DGS) has significantly improved the efficiency and realism of three-dimensional scene visualization in several applications, ranging from robotics to eXtended Reality (XR). This work presents SAGE (Semantic-Driven Adaptive Gaussian Splatting in Extended Reality), a novel framework designed to enhance the user experience by dynamically adapting the Level of Detail (LOD) of different 3DGS objects identified via a semantic segmentation. Experimental results demonstrate how SAGE effectively reduces memory and computational overhead while keeping a desired target visual quality, thus providing a powerful optimization for interactive XR applications.
Point Cloud Geometry Scalable Coding Using a Resolution and Quality-conditioned Latents Probability Estimator
Feb 19, 2025In the current age, users consume multimedia content in very heterogeneous scenarios in terms of network, hardware, and display capabilities. A naive solution to this problem is to encode multiple independent streams, each covering a different possible requirement for the clients, with an obvious negative impact in both storage and computational requirements. These drawbacks can be avoided by using codecs that enable scalability, i.e., the ability to generate a progressive bitstream, containing a base layer followed by multiple enhancement layers, that allow decoding the same bitstream serving multiple reconstructions and visualization specifications. While scalable coding is a well-known and addressed feature in conventional image and video codecs, this paper focuses on a new and very different problem, notably the development of scalable coding solutions for deep learning-based Point Cloud (PC) coding. The peculiarities of this 3D representation make it hard to implement flexible solutions that do not compromise the other functionalities of the codec. This paper proposes a joint quality and resolution scalability scheme, named Scalable Resolution and Quality Hyperprior (SRQH), that, contrary to previous solutions, can model the relationship between latents obtained with models trained for different RD tradeoffs and/or at different resolutions. Experimental results obtained by integrating SRQH in the emerging JPEG Pleno learning-based PC coding standard show that SRQH allows decoding the PC at different qualities and resolutions with a single bitstream while incurring only in a limited RD penalty and increment in complexity w.r.t. non-scalable JPEG PCC that would require one bitstream per coding configuration.
Effectiveness of learning-based image codecs on fingerprint storage
Sep 27, 2024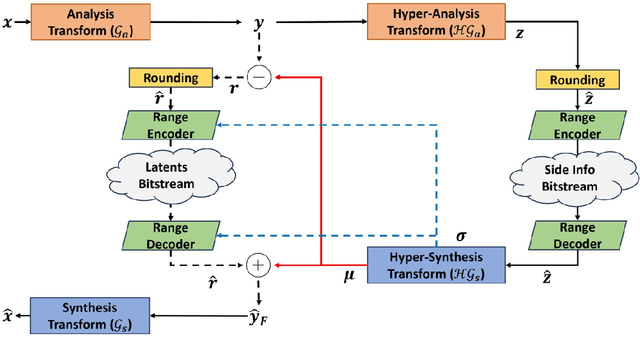

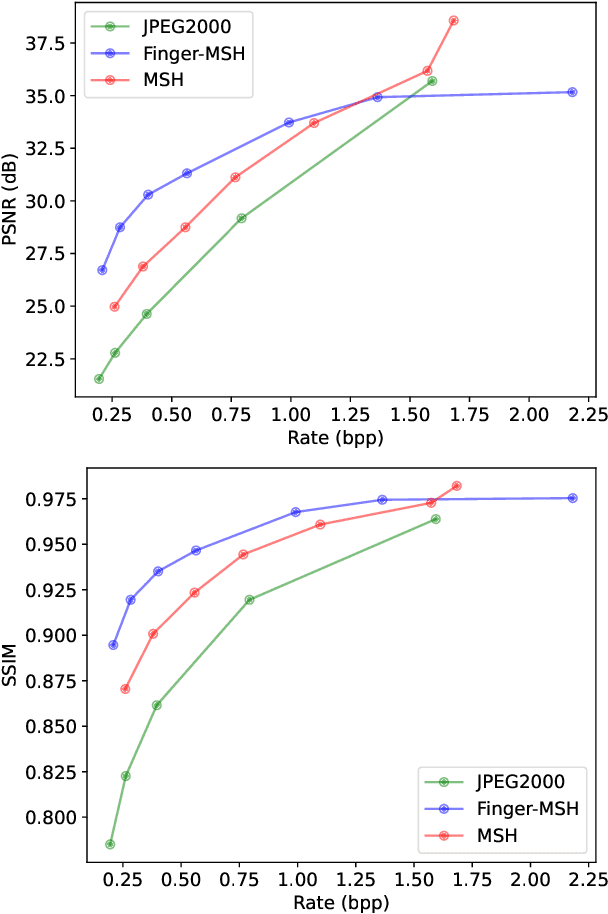
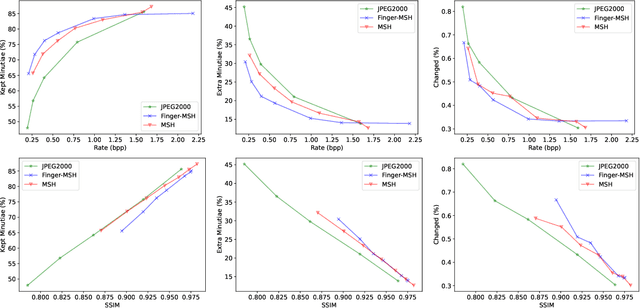
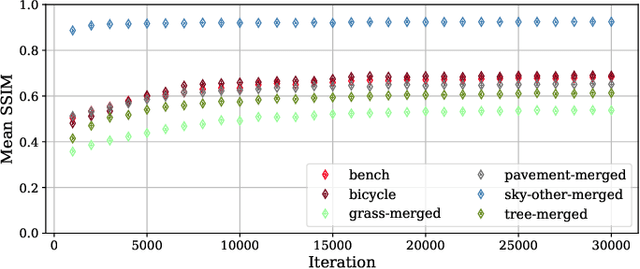
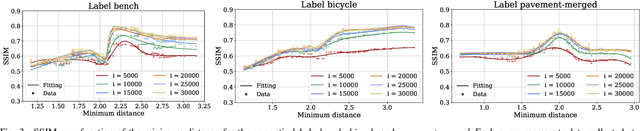
The success of learning-based coding techniques and the development of learning-based image coding standards, such as JPEG-AI, point towards the adoption of such solutions in different fields, including the storage of biometric data, like fingerprints. However, the peculiar nature of learning-based compression artifacts poses several issues concerning their impact and effectiveness on extracting biometric features and landmarks, e.g., minutiae. This problem is utterly stressed by the fact that most models are trained on natural color images, whose characteristics are very different from usual biometric images, e.g, fingerprint or iris pictures. As a matter of fact, these issues are deemed to be accurately questioned and investigated, being such analysis still largely unexplored. This study represents the first investigation about the adaptability of learning-based image codecs in the storage of fingerprint images by measuring its impact on the extraction and characterization of minutiae. Experimental results show that at a fixed rate point, learned solutions considerably outperform previous fingerprint coding standards, like JPEG2000, both in terms of distortion and minutiae preservation. Indeed, experimental results prove that the peculiarities of learned compression artifacts do not prevent automatic fingerprint identification (since minutiae types and locations are not significantly altered), nor do compromise image quality for human visual inspection (as they gain in terms of BD rate and PSNR of 47.8% and +3.97dB respectively).
Enhanced Model Robustness to Input Corruptions by Per-corruption Adaptation of Normalization Statistics
Jul 08, 2024Developing a reliable vision system is a fundamental challenge for robotic technologies (e.g., indoor service robots and outdoor autonomous robots) which can ensure reliable navigation even in challenging environments such as adverse weather conditions (e.g., fog, rain), poor lighting conditions (e.g., over/under exposure), or sensor degradation (e.g., blurring, noise), and can guarantee high performance in safety-critical functions. Current solutions proposed to improve model robustness usually rely on generic data augmentation techniques or employ costly test-time adaptation methods. In addition, most approaches focus on addressing a single vision task (typically, image recognition) utilising synthetic data. In this paper, we introduce Per-corruption Adaptation of Normalization statistics (PAN) to enhance the model robustness of vision systems. Our approach entails three key components: (i) a corruption type identification module, (ii) dynamic adjustment of normalization layer statistics based on identified corruption type, and (iii) real-time update of these statistics according to input data. PAN can integrate seamlessly with any convolutional model for enhanced accuracy in several robot vision tasks. In our experiments, PAN obtains robust performance improvement on challenging real-world corrupted image datasets (e.g., OpenLoris, ExDark, ACDC), where most of the current solutions tend to fail. Moreover, PAN outperforms the baseline models by 20-30% on synthetic benchmarks in object recognition tasks.
Fingerprint Membership and Identity Inference Against Generative Adversarial Networks
Jun 21, 2024Generative models are gaining significant attention as potential catalysts for a novel industrial revolution. Since automated sample generation can be useful to solve privacy and data scarcity issues that usually affect learned biometric models, such technologies became widely spread in this field. In this paper, we assess the vulnerabilities of generative machine learning models concerning identity protection by designing and testing an identity inference attack on fingerprint datasets created by means of a generative adversarial network. Experimental results show that the proposed solution proves to be effective under different configurations and easily extendable to other biometric measurements.
Point Cloud Geometry Scalable Coding with a Quality-Conditioned Latents Probability Estimator
Apr 11, 2024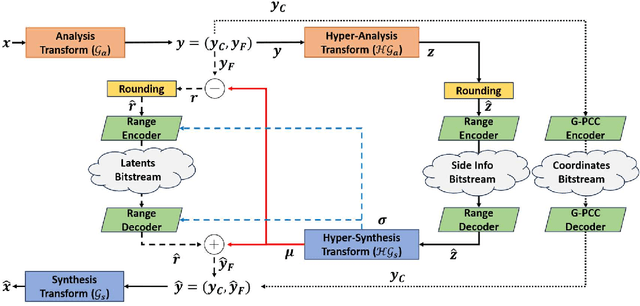
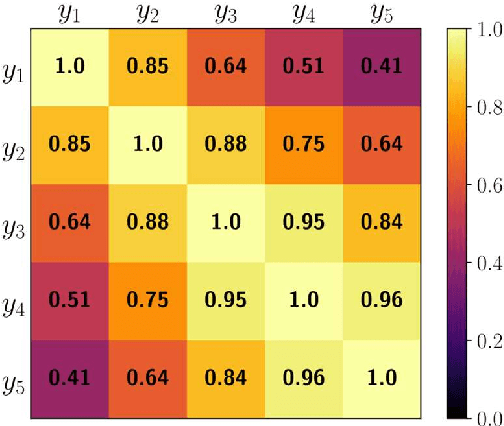

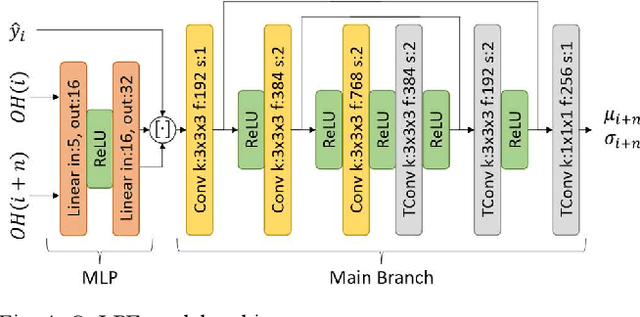
The widespread usage of point clouds (PC) for immersive visual applications has resulted in the use of very heterogeneous receiving conditions and devices, notably in terms of network, hardware, and display capabilities. In this scenario, quality scalability, i.e., the ability to reconstruct a signal at different qualities by progressively decoding a single bitstream, is a major requirement that has yet to be conveniently addressed, notably in most learning-based PC coding solutions. This paper proposes a quality scalability scheme, named Scalable Quality Hyperprior (SQH), adaptable to learning-based static point cloud geometry codecs, which uses a Quality-conditioned Latents Probability Estimator (QuLPE) to decode a high-quality version of a PC learning-based representation, based on an available lower quality base layer. SQH is integrated in the future JPEG PC coding standard, allowing to create a layered bitstream that can be used to progressively decode the PC geometry with increasing quality and fidelity. Experimental results show that SQH offers the quality scalability feature with very limited or no compression performance penalty at all when compared with the corresponding non-scalable solution, thus preserving the significant compression gains over other state-of-the-art PC codecs.
Enhancing the Rate-Distortion-Perception Flexibility of Learned Image Codecs with Conditional Diffusion Decoders
Mar 05, 2024Learned image compression codecs have recently achieved impressive compression performances surpassing the most efficient image coding architectures. However, most approaches are trained to minimize rate and distortion which often leads to unsatisfactory visual results at low bitrates since perceptual metrics are not taken into account. In this paper, we show that conditional diffusion models can lead to promising results in the generative compression task when used as a decoder, and that, given a compressed representation, they allow creating new tradeoff points between distortion and perception at the decoder side based on the sampling method.