 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSure! Here's a short and concise title for your paper: "Contamination in Generated Text Detection Benchmarks"
Nov 12, 2025

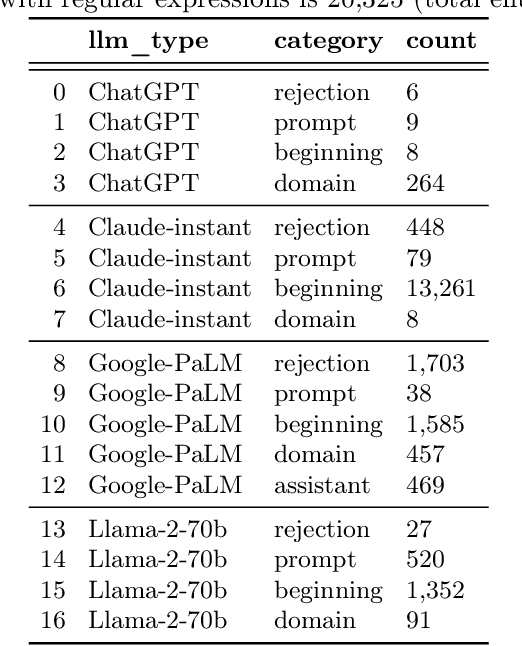

Large language models are increasingly used for many applications. To prevent illicit use, it is desirable to be able to detect AI-generated text. Training and evaluation of such detectors critically depend on suitable benchmark datasets. Several groups took on the tedious work of collecting, curating, and publishing large and diverse datasets for this task. However, it remains an open challenge to ensure high quality in all relevant aspects of such a dataset. For example, the DetectRL benchmark exhibits relatively simple patterns of AI-generation in 98.5% of the Claude-LLM data. These patterns may include introductory words such as "Sure! Here is the academic article abstract:", or instances where the LLM rejects the prompted task. In this work, we demonstrate that detectors trained on such data use such patterns as shortcuts, which facilitates spoofing attacks on the trained detectors. We consequently reprocessed the DetectRL dataset with several cleansing operations. Experiments show that such data cleansing makes direct attacks more difficult. The reprocessed dataset is publicly available.
BranchNet: A Neuro-Symbolic Learning Framework for Structured Multi-Class Classification
Jul 02, 2025We introduce BranchNet, a neuro-symbolic learning framework that transforms decision tree ensembles into sparse, partially connected neural networks. Each branch, defined as a decision path from root to a parent of leaves, is mapped to a hidden neuron, preserving symbolic structure while enabling gradient-based optimization. The resulting models are compact, interpretable, and require no manual architecture tuning. Evaluated on a suite of structured multi-class classification benchmarks, BranchNet consistently outperforms XGBoost in accuracy, with statistically significant gains. We detail the architecture, training procedure, and sparsity dynamics, and discuss the model's strengths in symbolic interpretability as well as its current limitations, particularly on binary tasks where further adaptive calibration may be beneficial.
Three Forensic Cues for JPEG AI Images
Apr 04, 2025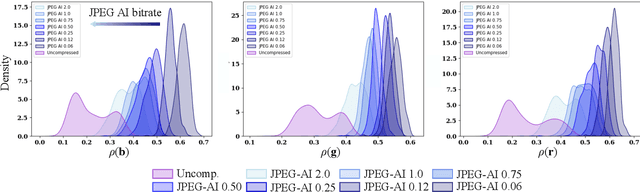

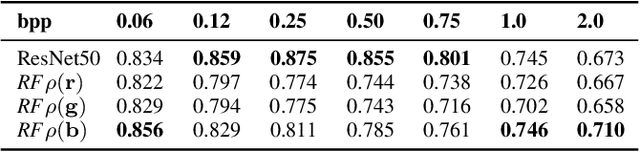
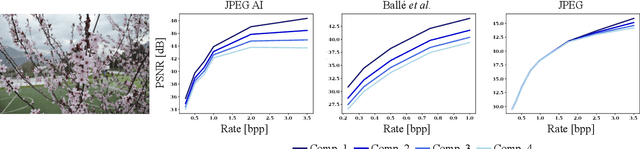
The JPEG standard was vastly successful. Currently, the first AI-based compression method ``JPEG AI'' will be standardized. JPEG AI brings remarkable benefits. JPEG AI images exhibit impressive image quality at bitrates that are an order of magnitude lower than images compressed with traditional JPEG. However, forensic analysis of JPEG AI has to be completely re-thought: forensic tools for traditional JPEG do not transfer to JPEG AI, and artifacts from JPEG AI are easily confused with artifacts from artificially generated images (``DeepFakes''). This creates a need for novel forensic approaches to detection and distinction of JPEG AI images. In this work, we make a first step towards a forensic JPEG AI toolset. We propose three cues for forensic algorithms for JPEG AI. These algorithms address three forensic questions: first, we show that the JPEG AI preprocessing introduces correlations in the color channels that do not occur in uncompressed images. Second, we show that repeated compression of JPEG AI images leads to diminishing distortion differences. This can be used to detect recompression, in a spirit similar to some classic JPEG forensics methods. Third, we show that the quantization of JPEG AI images in the latent space can be used to distinguish real images with JPEG AI compression from synthetically generated images. The proposed methods are interpretable for a forensic analyst, and we hope that they inspire further research in the forensics of AI-compressed images.
Trustworthy Compression? Impact of AI-based Codecs on Biometrics for Law Enforcement
Aug 20, 2024

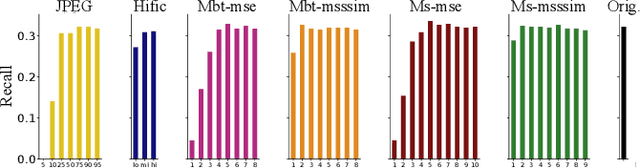
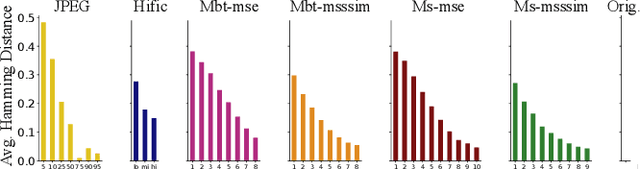
Image-based biometrics can aid law enforcement in various aspects, for example in iris, fingerprint and soft-biometric recognition. A critical precondition for recognition is the availability of sufficient biometric information in images. It is visually apparent that strong JPEG compression removes such details. However, latest AI-based image compression seemingly preserves many image details even for very strong compression factors. Yet, these perceived details are not necessarily grounded in measurements, which raises the question whether these images can still be used for biometric recognition. In this work, we investigate how AI compression impacts iris, fingerprint and soft-biometric (fabrics and tattoo) images. We also investigate the recognition performance for iris and fingerprint images after AI compression. It turns out that iris recognition can be strongly affected, while fingerprint recognition is quite robust. The loss of detail is qualitatively best seen in fabrics and tattoos images. Overall, our results show that AI-compression still permits many biometric tasks, but attention to strong compression factors in sensitive tasks is advisable.
Can We Identify Unknown Audio Recording Environments in Forensic Scenarios?
May 03, 2024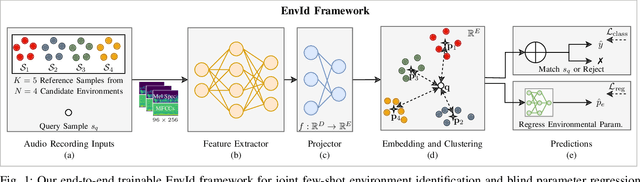
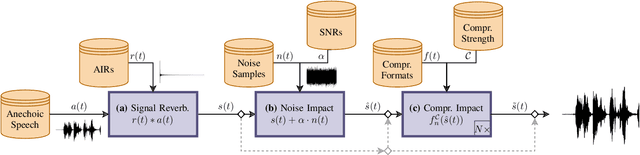
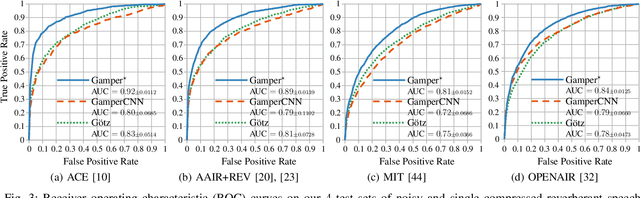
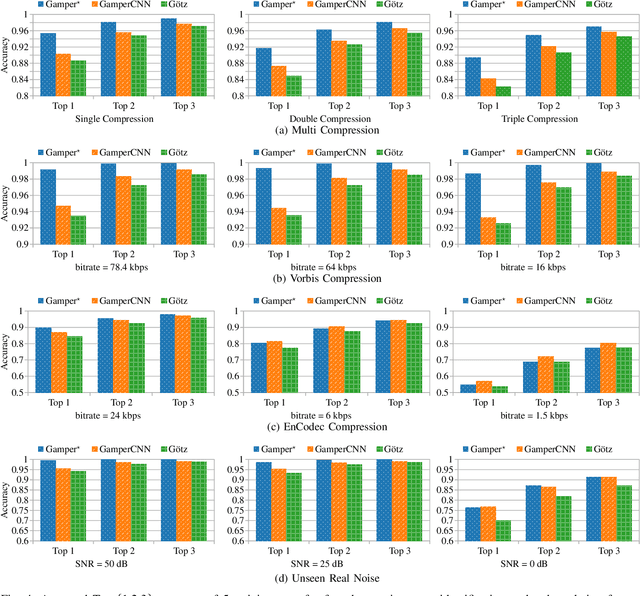
Audio recordings may provide important evidence in criminal investigations. One such case is the forensic association of the recorded audio to the recording location. For example, a voice message may be the only investigative cue to narrow down the candidate sites for a crime. Up to now, several works provide tools for closed-set recording environment classification under relatively clean recording conditions. However, in forensic investigations, the candidate locations are case-specific. Thus, closed-set tools are not applicable without retraining on a sufficient amount of training samples for each case and respective candidate set. In addition, a forensic tool has to deal with audio material from uncontrolled sources with variable properties and quality. In this work, we therefore attempt a major step towards practical forensic application scenarios. We propose a representation learning framework called EnvId, short for environment identification. EnvId avoids case-specific retraining. Instead, it is the first tool for robust few-shot classification of unseen environment locations. We demonstrate that EnvId can handle forensically challenging material. It provides good quality predictions even under unseen signal degradations, environment characteristics or recording position mismatches. Our code and datasets will be made publicly available upon acceptance.
LORD: Leveraging Open-Set Recognition with Unknown Data
Aug 24, 2023



Handling entirely unknown data is a challenge for any deployed classifier. Classification models are typically trained on a static pre-defined dataset and are kept in the dark for the open unassigned feature space. As a result, they struggle to deal with out-of-distribution data during inference. Addressing this task on the class-level is termed open-set recognition (OSR). However, most OSR methods are inherently limited, as they train closed-set classifiers and only adapt the downstream predictions to OSR. This work presents LORD, a framework to Leverage Open-set Recognition by exploiting unknown Data. LORD explicitly models open space during classifier training and provides a systematic evaluation for such approaches. We identify three model-agnostic training strategies that exploit background data and applied them to well-established classifiers. Due to LORD's extensive evaluation protocol, we consistently demonstrate improved recognition of unknown data. The benchmarks facilitate in-depth analysis across various requirement levels. To mitigate dependency on extensive and costly background datasets, we explore mixup as an off-the-shelf data generation technique. Our experiments highlight mixup's effectiveness as a substitute for background datasets. Lightweight constraints on mixup synthesis further improve OSR performance.
Point to the Hidden: Exposing Speech Audio Splicing via Signal Pointer Nets
Aug 02, 2023


Verifying the integrity of voice recording evidence for criminal investigations is an integral part of an audio forensic analyst's work. Here, one focus is on detecting deletion or insertion operations, so called audio splicing. While this is a rather easy approach to alter spoken statements, careful editing can yield quite convincing results. For difficult cases or big amounts of data, automated tools can support in detecting potential editing locations. To this end, several analytical and deep learning methods have been proposed by now. Still, few address unconstrained splicing scenarios as expected in practice. With SigPointer, we propose a pointer network framework for continuous input that uncovers splice locations naturally and more efficiently than existing works. Extensive experiments on forensically challenging data like strongly compressed and noisy signals quantify the benefit of the pointer mechanism with performance increases between about 6 to 10 percentage points.
Benchmarking Probabilistic Deep Learning Methods for License Plate Recognition
Feb 02, 2023



Learning-based algorithms for automated license plate recognition implicitly assume that the training and test data are well aligned. However, this may not be the case under extreme environmental conditions, or in forensic applications where the system cannot be trained for a specific acquisition device. Predictions on such out-of-distribution images have an increased chance of failing. But this failure case is oftentimes hard to recognize for a human operator or an automated system. Hence, in this work we propose to model the prediction uncertainty for license plate recognition explicitly. Such an uncertainty measure allows to detect false predictions, indicating an analyst when not to trust the result of the automated license plate recognition. In this paper, we compare three methods for uncertainty quantification on two architectures. The experiments on synthetic noisy or blurred low-resolution images show that the predictive uncertainty reliably finds wrong predictions. We also show that a multi-task combination of classification and super-resolution improves the recognition performance by 109\% and the detection of wrong predictions by 29 %.
Synthesizing Annotated Image and Video Data Using a Rendering-Based Pipeline for Improved License Plate Recognition
Sep 28, 2022


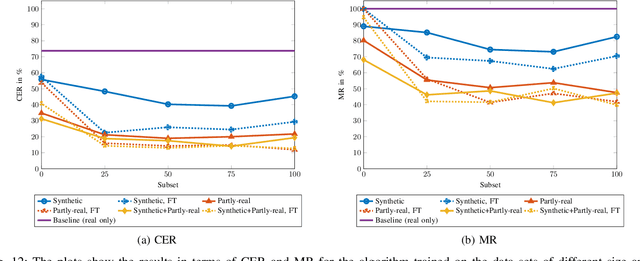
An insufficient number of training samples is a common problem in neural network applications. While data augmentation methods require at least a minimum number of samples, we propose a novel, rendering-based pipeline for synthesizing annotated data sets. Our method does not modify existing samples but synthesizes entirely new samples. The proposed rendering-based pipeline is capable of generating and annotating synthetic and partly-real image and video data in a fully automatic procedure. Moreover, the pipeline can aid the acquisition of real data. The proposed pipeline is based on a rendering process. This process generates synthetic data. Partly-real data bring the synthetic sequences closer to reality by incorporating real cameras during the acquisition process. The benefits of the proposed data generation pipeline, especially for machine learning scenarios with limited available training data, are demonstrated by an extensive experimental validation in the context of automatic license plate recognition. The experiments demonstrate a significant reduction of the character error rate and miss rate from 73.74% and 100% to 14.11% and 41.27% respectively, compared to an OCR algorithm trained on a real data set solely. These improvements are achieved by training the algorithm on synthesized data solely. When additionally incorporating real data, the error rates can be decreased further. Thereby, the character error rate and miss rate can be reduced to 11.90% and 39.88% respectively. All data used during the experiments as well as the proposed rendering-based pipeline for the automated data generation is made publicly available under (URL will be revealed upon publication).
3D Rendering Framework for Data Augmentation in Optical Character Recognition
Sep 27, 2022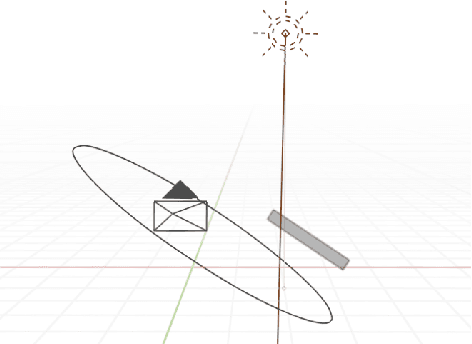
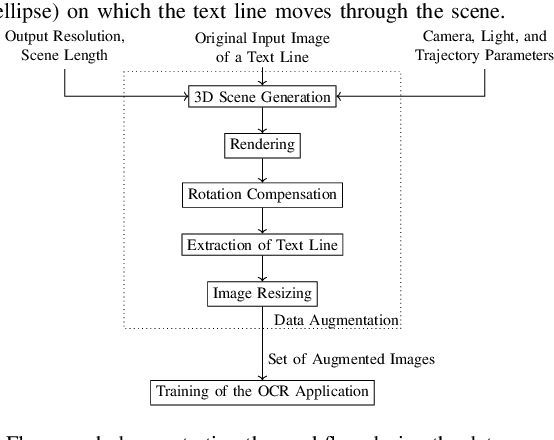

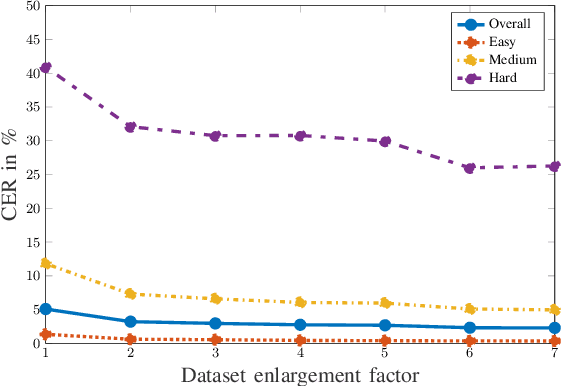
In this paper, we propose a data augmentation framework for Optical Character Recognition (OCR). The proposed framework is able to synthesize new viewing angles and illumination scenarios, effectively enriching any available OCR dataset. Its modular structure allows to be modified to match individual user requirements. The framework enables to comfortably scale the enlargement factor of the available dataset. Furthermore, the proposed method is not restricted to single frame OCR but can also be applied to video OCR. We demonstrate the performance of our framework by augmenting a 15% subset of the common Brno Mobile OCR dataset. Our proposed framework is capable of leveraging the performance of OCR applications especially for small datasets. Applying the proposed method, improvements of up to 2.79 percentage points in terms of Character Error Rate (CER), and up to 7.88 percentage points in terms of Word Error Rate (WER) are achieved on the subset. Especially the recognition of challenging text lines can be improved. The CER may be decreased by up to 14.92 percentage points and the WER by up to 18.19 percentage points for this class. Moreover, we are able to achieve smaller error rates when training on the 15% subset augmented with the proposed method than on the original non-augmented full dataset.