 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Identify Unknown Audio Recording Environments in Forensic Scenarios?
May 03, 2024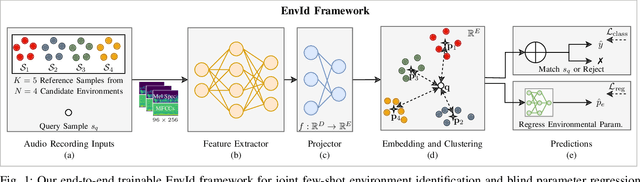
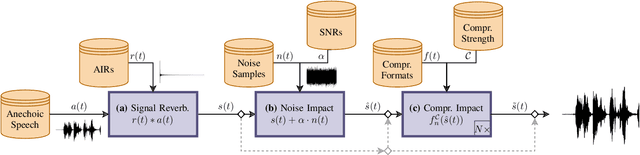
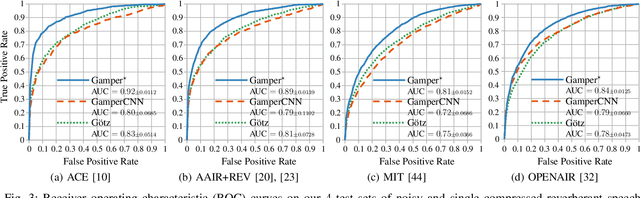
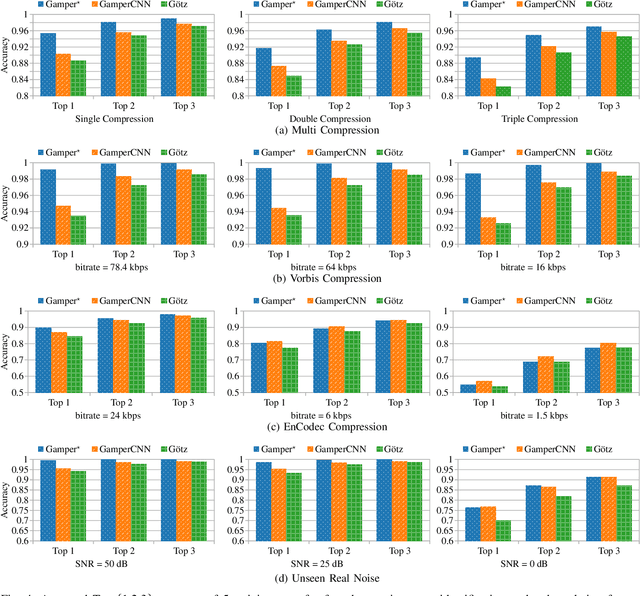
Audio recordings may provide important evidence in criminal investigations. One such case is the forensic association of the recorded audio to the recording location. For example, a voice message may be the only investigative cue to narrow down the candidate sites for a crime. Up to now, several works provide tools for closed-set recording environment classification under relatively clean recording conditions. However, in forensic investigations, the candidate locations are case-specific. Thus, closed-set tools are not applicable without retraining on a sufficient amount of training samples for each case and respective candidate set. In addition, a forensic tool has to deal with audio material from uncontrolled sources with variable properties and quality. In this work, we therefore attempt a major step towards practical forensic application scenarios. We propose a representation learning framework called EnvId, short for environment identification. EnvId avoids case-specific retraining. Instead, it is the first tool for robust few-shot classification of unseen environment locations. We demonstrate that EnvId can handle forensically challenging material. It provides good quality predictions even under unseen signal degradations, environment characteristics or recording position mismatches. Our code and datasets will be made publicly available upon acceptance.
Point to the Hidden: Exposing Speech Audio Splicing via Signal Pointer Nets
Aug 02, 2023


Verifying the integrity of voice recording evidence for criminal investigations is an integral part of an audio forensic analyst's work. Here, one focus is on detecting deletion or insertion operations, so called audio splicing. While this is a rather easy approach to alter spoken statements, careful editing can yield quite convincing results. For difficult cases or big amounts of data, automated tools can support in detecting potential editing locations. To this end, several analytical and deep learning methods have been proposed by now. Still, few address unconstrained splicing scenarios as expected in practice. With SigPointer, we propose a pointer network framework for continuous input that uncovers splice locations naturally and more efficiently than existing works. Extensive experiments on forensically challenging data like strongly compressed and noisy signals quantify the benefit of the pointer mechanism with performance increases between about 6 to 10 percentage points.
Towards Unconstrained Audio Splicing Detection and Localization with Neural Networks
Jul 29, 2022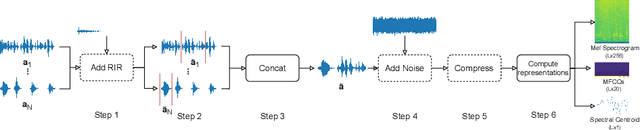
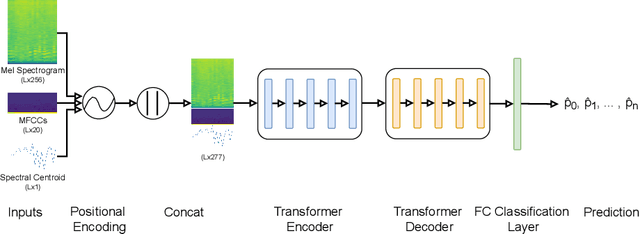
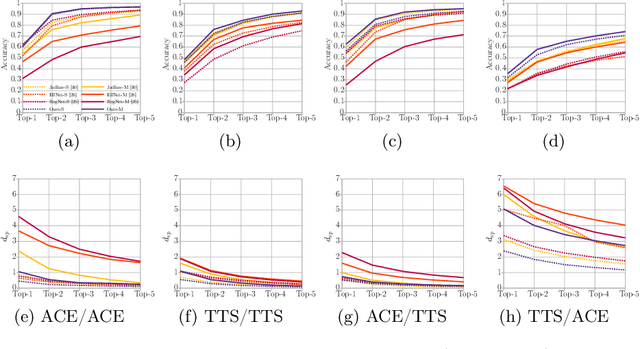
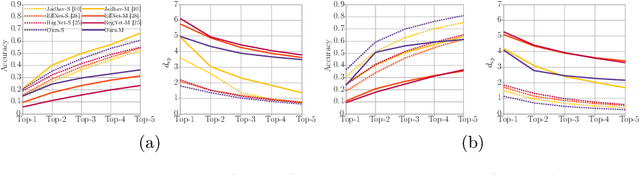
Freely available and easy-to-use audio editing tools make it straightforward to perform audio splicing. Convincing forgeries can be created by combining various speech samples from the same person. Detection of such splices is important both in the public sector when considering misinformation, and in a legal context to verify the integrity of evidence. Unfortunately, most existing detection algorithms for audio splicing use handcrafted features and make specific assumptions. However, criminal investigators are often faced with audio samples from unconstrained sources with unknown characteristics, which raises the need for more generally applicable methods. With this work, we aim to take a first step towards unconstrained audio splicing detection to address this need. We simulate various attack scenarios in the form of post-processing operations that may disguise splicing. We propose a Transformer sequence-to-sequence (seq2seq) network for splicing detection and localization. Our extensive evaluation shows that the proposed method outperforms existing dedicated approaches for splicing detection [3, 10] as well as the general-purpose networks EfficientNet [28] and RegNet [25].