 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePi-GS: Sparse-View Gaussian Splatting with Dense π^3 Initialization
Feb 03, 2026Novel view synthesis has evolved rapidly, advancing from Neural Radiance Fields to 3D Gaussian Splatting (3DGS), which offers real-time rendering and rapid training without compromising visual fidelity. However, 3DGS relies heavily on accurate camera poses and high-quality point cloud initialization, which are difficult to obtain in sparse-view scenarios. While traditional Structure from Motion (SfM) pipelines often fail in these settings, existing learning-based point estimation alternatives typically require reliable reference views and remain sensitive to pose or depth errors. In this work, we propose a robust method utilizing π^3, a reference-free point cloud estimation network. We integrate dense initialization from π^3 with a regularization scheme designed to mitigate geometric inaccuracies. Specifically, we employ uncertainty-guided depth supervision, normal consistency loss, and depth warping. Experimental results demonstrate that our approach achieves state-of-the-art performance on the Tanks and Temples, LLFF, DTU, and MipNeRF360 datasets.
A LoD of Gaussians: Unified Training and Rendering for Ultra-Large Scale Reconstruction with External Memory
Jul 01, 2025Gaussian Splatting has emerged as a high-performance technique for novel view synthesis, enabling real-time rendering and high-quality reconstruction of small scenes. However, scaling to larger environments has so far relied on partitioning the scene into chunks -- a strategy that introduces artifacts at chunk boundaries, complicates training across varying scales, and is poorly suited to unstructured scenarios such as city-scale flyovers combined with street-level views. Moreover, rendering remains fundamentally limited by GPU memory, as all visible chunks must reside in VRAM simultaneously. We introduce A LoD of Gaussians, a framework for training and rendering ultra-large-scale Gaussian scenes on a single consumer-grade GPU -- without partitioning. Our method stores the full scene out-of-core (e.g., in CPU memory) and trains a Level-of-Detail (LoD) representation directly, dynamically streaming only the relevant Gaussians. A hybrid data structure combining Gaussian hierarchies with Sequential Point Trees enables efficient, view-dependent LoD selection, while a lightweight caching and view scheduling system exploits temporal coherence to support real-time streaming and rendering. Together, these innovations enable seamless multi-scale reconstruction and interactive visualization of complex scenes -- from broad aerial views to fine-grained ground-level details.
AAA-Gaussians: Anti-Aliased and Artifact-Free 3D Gaussian Rendering
Apr 17, 2025Although 3D Gaussian Splatting (3DGS) has revolutionized 3D reconstruction, it still faces challenges such as aliasing, projection artifacts, and view inconsistencies, primarily due to the simplification of treating splats as 2D entities. We argue that incorporating full 3D evaluation of Gaussians throughout the 3DGS pipeline can effectively address these issues while preserving rasterization efficiency. Specifically, we introduce an adaptive 3D smoothing filter to mitigate aliasing and present a stable view-space bounding method that eliminates popping artifacts when Gaussians extend beyond the view frustum. Furthermore, we promote tile-based culling to 3D with screen-space planes, accelerating rendering and reducing sorting costs for hierarchical rasterization. Our method achieves state-of-the-art quality on in-distribution evaluation sets and significantly outperforms other approaches for out-of-distribution views. Our qualitative evaluations further demonstrate the effective removal of aliasing, distortions, and popping artifacts, ensuring real-time, artifact-free rendering.
LORD: Leveraging Open-Set Recognition with Unknown Data
Aug 24, 2023



Handling entirely unknown data is a challenge for any deployed classifier. Classification models are typically trained on a static pre-defined dataset and are kept in the dark for the open unassigned feature space. As a result, they struggle to deal with out-of-distribution data during inference. Addressing this task on the class-level is termed open-set recognition (OSR). However, most OSR methods are inherently limited, as they train closed-set classifiers and only adapt the downstream predictions to OSR. This work presents LORD, a framework to Leverage Open-set Recognition by exploiting unknown Data. LORD explicitly models open space during classifier training and provides a systematic evaluation for such approaches. We identify three model-agnostic training strategies that exploit background data and applied them to well-established classifiers. Due to LORD's extensive evaluation protocol, we consistently demonstrate improved recognition of unknown data. The benchmarks facilitate in-depth analysis across various requirement levels. To mitigate dependency on extensive and costly background datasets, we explore mixup as an off-the-shelf data generation technique. Our experiments highlight mixup's effectiveness as a substitute for background datasets. Lightweight constraints on mixup synthesis further improve OSR performance.
Exploring the Open World Using Incremental Extreme Value Machines
May 30, 2022

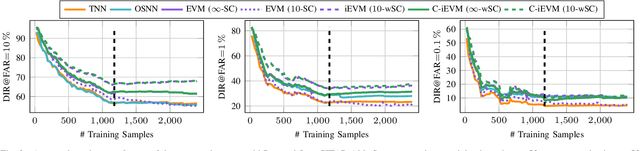

Dynamic environments require adaptive applications. One particular machine learning problem in dynamic environments is open world recognition. It characterizes a continuously changing domain where only some classes are seen in one batch of the training data and such batches can only be learned incrementally. Open world recognition is a demanding task that is, to the best of our knowledge, addressed by only a few methods. This work introduces a modification of the widely known Extreme Value Machine (EVM) to enable open world recognition. Our proposed method extends the EVM with a partial model fitting function by neglecting unaffected space during an update. This reduces the training time by a factor of 28. In addition, we provide a modified model reduction using weighted maximum K-set cover to strictly bound the model complexity and reduce the computational effort by a factor of 3.5 from 2.1 s to 0.6 s. In our experiments, we rigorously evaluate openness with two novel evaluation protocols. The proposed method achieves superior accuracy of about 12 % and computational efficiency in the tasks of image classification and face recognition.
Joint Super-Resolution and Rectification for Solar Cell Inspection
Nov 10, 2020
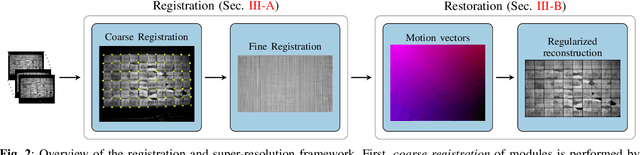
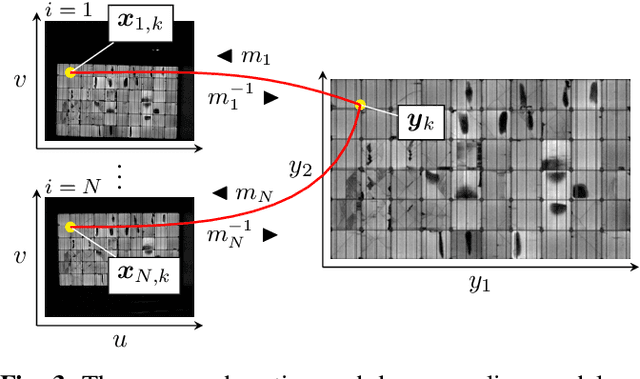

Visual inspection of solar modules is an important monitoring facility in photovoltaic power plants. Since a single measurement of fast CMOS sensors is limited in spatial resolution and often not sufficient to reliably detect small defects, we apply multi-frame super-resolution (MFSR) to a sequence of low resolution measurements. In addition, the rectification and removal of lens distortion simplifies subsequent analysis. Therefore, we propose to fuse this pre-processing with standard MFSR algorithms. This is advantageous, because we omit a separate processing step, the motion estimation becomes more stable and the spacing of high-resolution (HR) pixels on the rectified module image becomes uniform w.r.t. the module plane, regardless of perspective distortion. We present a comprehensive user study showing that MFSR is beneficial for defect recognition by human experts and that the proposed method performs better than the state of the art. Furthermore, we apply automated crack segmentation and show that the proposed method performs 3x better than bicubic upsampling and 2x better than the state of the art for automated inspection.
Merging-ISP: Multi-Exposure High Dynamic Range Image Signal Processing
Nov 12, 2019
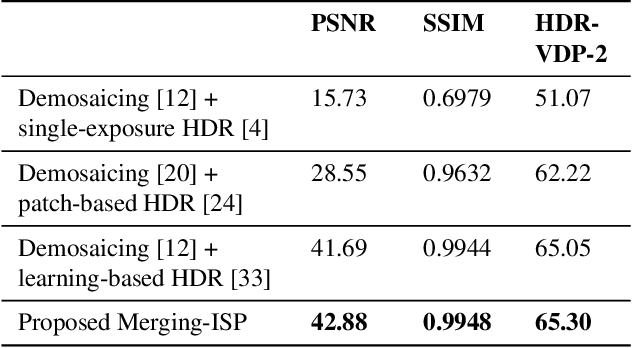

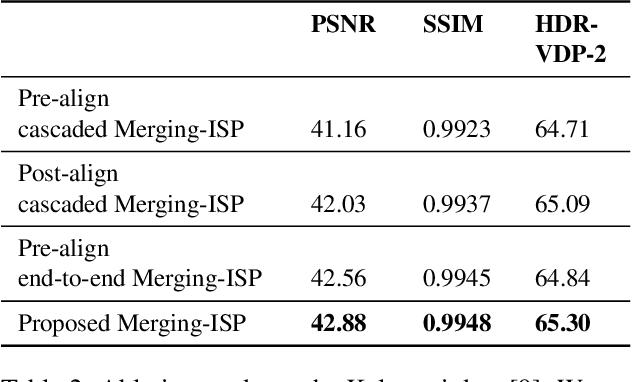
The image signal processing pipeline (ISP) is a core element of digital cameras to capture high-quality displayable images from raw data. In high dynamic range (HDR) imaging, ISPs include steps like demosaicing of raw color filter array (CFA) data at different exposure times, alignment of the exposures, conversion to HDR domain, and exposure merging into an HDR image. Traditionally, such pipelines are built by cascading algorithms addressing the individual subtasks. However, cascaded designs suffer from error propagations since simply combining multiple processing steps is not necessarily optimal for the entire imaging task. This paper proposes a multi-exposure high dynamic range image signal processing pipeline (Merging-ISP) to jointly solve all subtasks for HDR imaging. Our pipeline is modeled by a deep neural network architecture. As such, it is end-to-end trainable, circumvents the use of complex, hand-crafted algorithms in its core, and mitigates error propagation. Merging-ISP enables direct reconstructions of HDR images from multiple differently exposed raw CFA images captured from dynamic scenes. We compared Merging-ISP against different alternative cascaded pipelines. End-to-end learning leads to HDR reconstructions of high perceptual quality and quantitatively outperforms competing ISPs by more than 1 dB in terms of PSNR.
Multi-Frame Super-Resolution Reconstruction with Applications to Medical Imaging
Dec 21, 2018The optical resolution of a digital camera is one of its most crucial parameters with broad relevance for consumer electronics, surveillance systems, remote sensing, or medical imaging. However, resolution is physically limited by the optics and sensor characteristics. In addition, practical and economic reasons often stipulate the use of out-dated or low-cost hardware. Super-resolution is a class of retrospective techniques that aims at high-resolution imagery by means of software. Multi-frame algorithms approach this task by fusing multiple low-resolution frames to reconstruct high-resolution images. This work covers novel super-resolution methods along with new applications in medical imaging.
Bridging the Simulated-to-Real Gap: Benchmarking Super-Resolution on Real Data
Sep 17, 2018
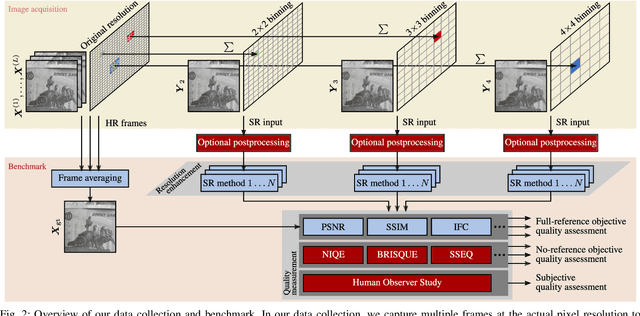

Capturing ground truth data to benchmark super-resolution (SR) is challenging. Therefore, current quantitative studies are mainly evaluated on simulated data artificially sampled from ground truth images. We argue that such evaluations overestimate the actual performance of SR methods compared to their behavior on real images. To bridge this simulated-to-real gap, we introduce the Super-Resolution Erlangen (SupER) database, the first comprehensive laboratory SR database of all-real acquisitions with pixel-wise ground truth. It consists of more than 80k images of 14 scenes combining different facets: CMOS sensor noise, real sampling at four resolution levels, nine scene motion types, two photometric conditions, and lossy video coding at five levels. As such, the database exceeds existing benchmarks by an order of magnitude in quality and quantity. This paper also benchmarks 19 popular single-image and multi-frame algorithms on our data. The benchmark comprises a quantitative study by exploiting ground truth data and qualitative evaluations in a large-scale observer study. We also rigorously investigate agreements between both evaluations from a statistical perspective. One interesting result is that top-performing methods on simulated data may be surpassed by others on real data. Our insights can spur further algorithm development, and the publicy available dataset can foster future evaluations.
Temporal and Volumetric Denoising via Quantile Sparse Image (QuaSI) Prior in Optical Coherence Tomography and Beyond
Jul 05, 2018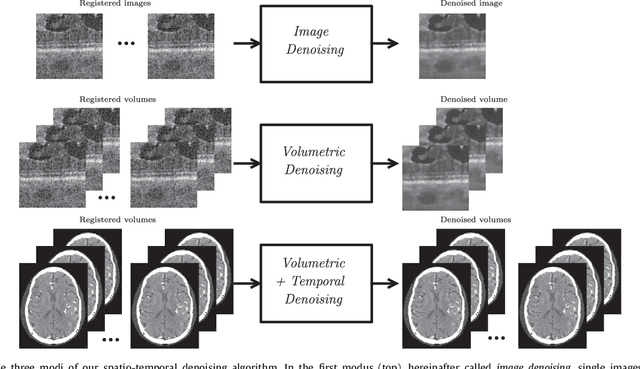


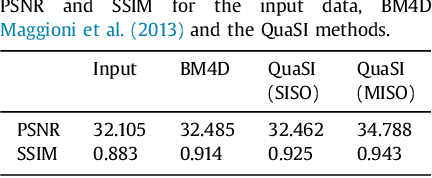
This paper introduces an universal and structure-preserving regularization term, called quantile sparse image (QuaSI) prior. The prior is suitable for denoising images from various medical imaging modalities. We demonstrate its effectiveness on volumetric optical coherence tomography (OCT) and computed tomography (CT) data, which show different noise and image characteristics. OCT offers high-resolution scans of the human retina but is inherently impaired by speckle noise. CT on the other hand has a lower resolution and shows high-frequency noise. For the purpose of denoising, we propose a variational framework based on the QuaSI prior and a Huber data fidelity model that can handle 3-D and 3-D+t data. Efficient optimization is facilitated through the use of an alternating direction method of multipliers (ADMM) scheme and the linearization of the quantile filter. Experiments on multiple datasets emphasize the excellent performance of the proposed method.