 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Annealing Feature Selection on Light-weight Medical Image Datasets
Feb 26, 2025We investigate the use of quantum computing algorithms on real quantum hardware to tackle the computationally intensive task of feature selection for light-weight medical image datasets. Feature selection is often formulated as a k of n selection problem, where the complexity grows binomially with increasing k and n. As problem sizes grow, classical approaches struggle to scale efficiently. Quantum computers, particularly quantum annealers, are well-suited for such problems, offering potential advantages in specific formulations. We present a method to solve larger feature selection instances than previously presented on commercial quantum annealers. Our approach combines a linear Ising penalty mechanism with subsampling and thresholding techniques to enhance scalability. The method is tested in a toy problem where feature selection identifies pixel masks used to reconstruct small-scale medical images. The results indicate that quantum annealing-based feature selection is effective for this simplified use case, demonstrating its potential in high-dimensional optimization tasks. However, its applicability to broader, real-world problems remains uncertain, given the current limitations of quantum computing hardware.
Hybrid adiabatic quantum computing for tomographic image reconstruction -- opportunities and limitations
Dec 02, 2022


Our goal is to reconstruct tomographic images with few measurements and a low signal-to-noise ratio. In clinical imaging, this helps to improve patient comfort and reduce radiation exposure. As quantum computing advances, we propose to use an adiabatic quantum computer and associated hybrid methods to solve the reconstruction problem. Tomographic reconstruction is an ill-posed inverse problem. We test our reconstruction technique for image size, noise content, and underdetermination of the measured projection data. We then present the reconstructed binary and integer-valued images of up to 32 by 32 pixels. The demonstrated method competes with traditional reconstruction algorithms and is superior in terms of robustness to noise and reconstructions from few projections. We postulate that hybrid quantum computing will soon reach maturity for real applications in tomographic reconstruction. Finally, we point out the current limitations regarding the problem size and interpretability of the algorithm.
SEMPAI: a Self-Enhancing Multi-Photon Artificial Intelligence for prior-informed assessment of muscle function and pathology
Oct 28, 2022Deep learning (DL) shows notable success in biomedical studies. However, most DL algorithms work as a black box, exclude biomedical experts, and need extensive data. We introduce the Self-Enhancing Multi-Photon Artificial Intelligence (SEMPAI), that integrates hypothesis-driven priors in a data-driven DL approach for research on multiphoton microscopy (MPM) of muscle fibers. SEMPAI utilizes meta-learning to optimize prior integration, data representation, and neural network architecture simultaneously. This allows hypothesis testing and provides interpretable feedback about the origin of biological information in MPM images. SEMPAI performs joint learning of several tasks to enable prediction for small datasets. The method is applied on an extensive multi-study dataset resulting in the largest joint analysis of pathologies and function for single muscle fibers. SEMPAI outperforms state-of-the-art biomarkers in six of seven predictive tasks, including those with scarce data. SEMPAI's DL models with integrated priors are superior to those without priors and to prior-only machine learning approaches.
Efficient and high accuracy 3-D OCT angiography motion correction in pathology
Oct 14, 2020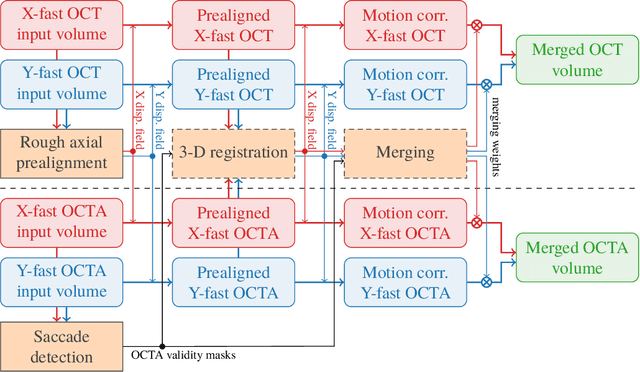
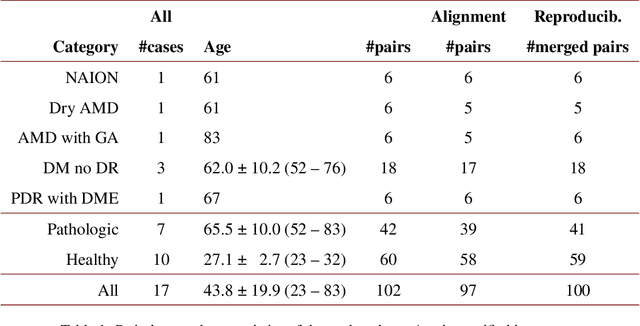
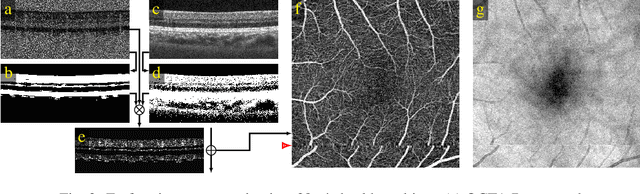
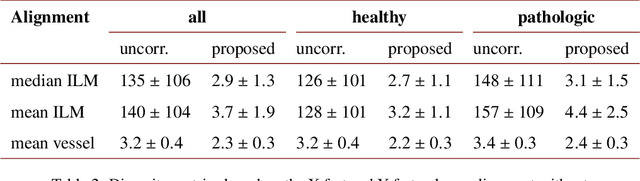
We propose a novel method for non-rigid 3-D motion correction of orthogonally raster-scanned optical coherence tomography angiography volumes. This is the first approach that aligns predominantly axial structural features like retinal layers and transverse angiographic vascular features in a joint optimization. Combined with the use of orthogonal scans and favorization of kinematically more plausible displacements, the approach allows subpixel alignment and micrometer-scale distortion correction in all 3 dimensions. As no specific structures or layers are segmented, the approach is by design robust to pathologic changes. It is furthermore designed for highly parallel implementation and brief runtime, allowing its integration in clinical routine even for high density or wide-field scans. We evaluated the algorithm with metrics related to clinically relevant features in a large-scale quantitative evaluation based on 204 volumetric scans of 17 subjects including both a wide range of pathologies and healthy controls. Using this method, we achieve state-of-the-art axial performance and show significant advances in both transverse co-alignment and distortion correction, especially in the pathologic subgroup.
Deep OCT Angiography Image Generation for Motion Artifact Suppression
Jan 08, 2020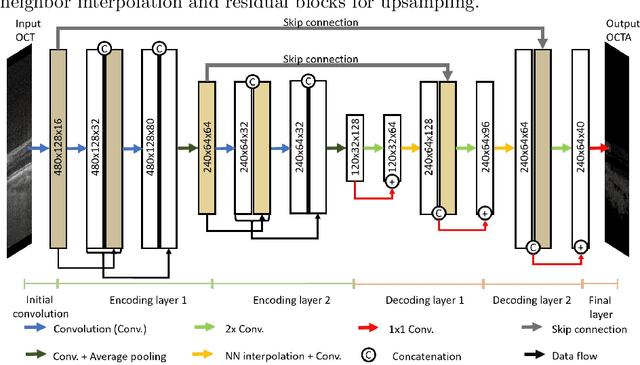
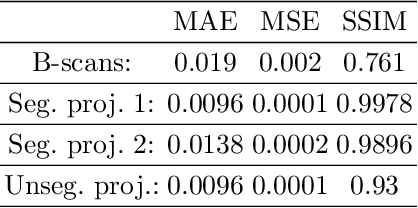
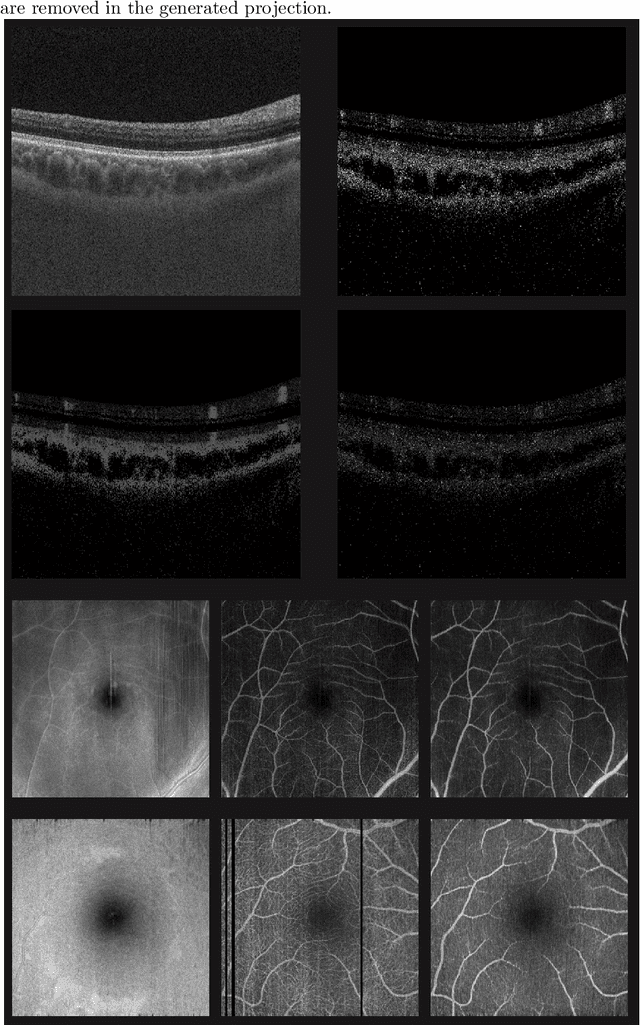
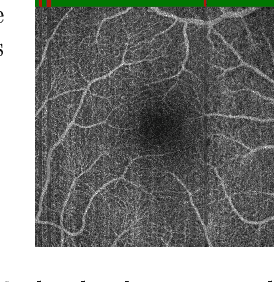
Eye movements, blinking and other motion during the acquisition of optical coherence tomography (OCT) can lead to artifacts, when processed to OCT angiography (OCTA) images. Affected scans emerge as high intensity (white) or missing (black) regions, resulting in lost information. The aim of this research is to fill these gaps using a deep generative model for OCT to OCTA image translation relying on a single intact OCT scan. Therefore, a U-Net is trained to extract the angiographic information from OCT patches. At inference, a detection algorithm finds outlier OCTA scans based on their surroundings, which are then replaced by the trained network. We show that generative models can augment the missing scans. The augmented volumes could then be used for 3-D segmentation or increase the diagnostic value.
Fast and robust detection of solar modules in electroluminescence images
Jul 19, 2019



Fast, non-destructive and on-site quality control tools, mainly high sensitive imaging techniques, are important to assess the reliability of photovoltaic plants. To minimize the risk of further damages and electrical yield losses, electroluminescence (EL) imaging is used to detect local defects in an early stage, which might cause future electric losses. For an automated defect recognition on EL measurements, a robust detection and rectification of modules, as well as an optional segmentation into cells is required. This paper introduces a method to detect solar modules and crossing points between solar cells in EL images. We only require 1-D image statistics for the detection, resulting in an approach that is computationally efficient. In addition, the method is able to detect the modules under perspective distortion and in scenarios, where multiple modules are visible in the image. We compare our method to the state of the art and show that it is superior in presence of perspective distortion while the performance on images, where the module is roughly coplanar to the detector, is similar to the reference method. Finally, we show that we greatly improve in terms of computational time in comparison to the reference method.
Learning with Known Operators reduces Maximum Training Error Bounds
Jul 03, 2019
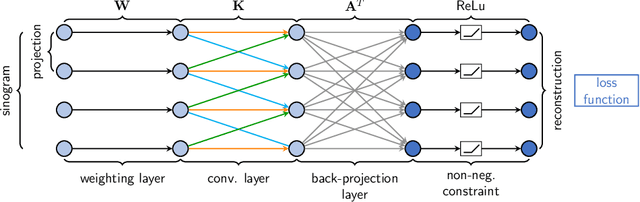
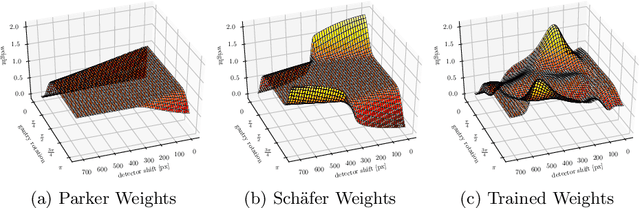
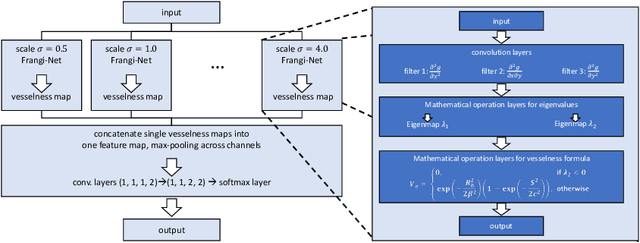
We describe an approach for incorporating prior knowledge into machine learning algorithms. We aim at applications in physics and signal processing in which we know that certain operations must be embedded into the algorithm. Any operation that allows computation of a gradient or sub-gradient towards its inputs is suited for our framework. We derive a maximal error bound for deep nets that demonstrates that inclusion of prior knowledge results in its reduction. Furthermore, we also show experimentally that known operators reduce the number of free parameters. We apply this approach to various tasks ranging from CT image reconstruction over vessel segmentation to the derivation of previously unknown imaging algorithms. As such the concept is widely applicable for many researchers in physics, imaging, and signal processing. We assume that our analysis will support further investigation of known operators in other fields of physics, imaging, and signal processing.
PYRO-NN: Python Reconstruction Operators in Neural Networks
Apr 30, 2019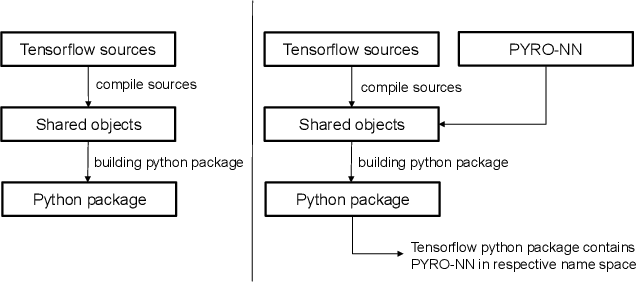
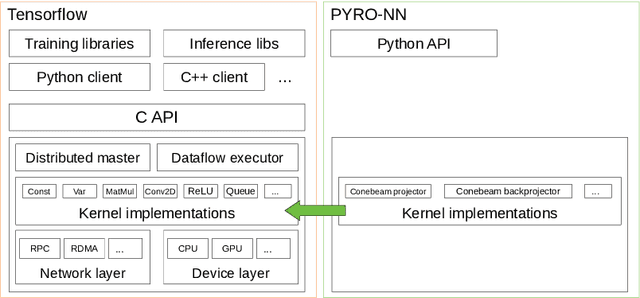
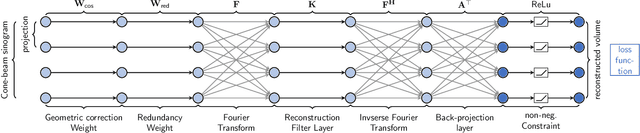
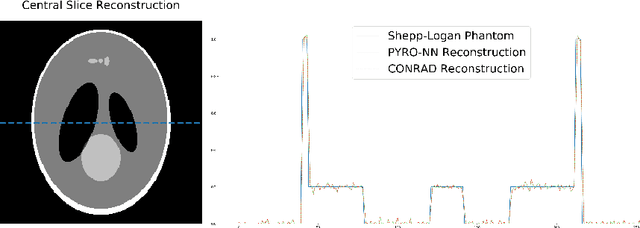
Purpose: Recently, several attempts were conducted to transfer deep learning to medical image reconstruction. An increasingly number of publications follow the concept of embedding the CT reconstruction as a known operator into a neural network. However, most of the approaches presented lack an efficient CT reconstruction framework fully integrated into deep learning environments. As a result, many approaches are forced to use workarounds for mathematically unambiguously solvable problems. Methods: PYRO-NN is a generalized framework to embed known operators into the prevalent deep learning framework Tensorflow. The current status includes state-of-the-art parallel-, fan- and cone-beam projectors and back-projectors accelerated with CUDA provided as Tensorflow layers. On top, the framework provides a high level Python API to conduct FBP and iterative reconstruction experiments with data from real CT systems. Results: The framework provides all necessary algorithms and tools to design end-to-end neural network pipelines with integrated CT reconstruction algorithms. The high level Python API allows a simple use of the layers as known from Tensorflow. To demonstrate the capabilities of the layers, the framework comes with three baseline experiments showing a cone-beam short scan FDK reconstruction, a CT reconstruction filter learning setup, and a TV regularized iterative reconstruction. All algorithms and tools are referenced to a scientific publication and are compared to existing non deep learning reconstruction frameworks. The framework is available as open-source software at \url{https://github.com/csyben/PYRO-NN}. Conclusions: PYRO-NN comes with the prevalent deep learning framework Tensorflow and allows to setup end-to-end trainable neural networks in the medical image reconstruction context. We believe that the framework will be a step towards reproducible research
Temporal and Volumetric Denoising via Quantile Sparse Image (QuaSI) Prior in Optical Coherence Tomography and Beyond
Jul 05, 2018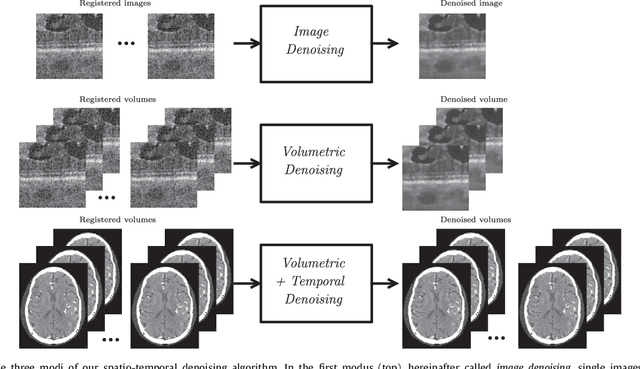


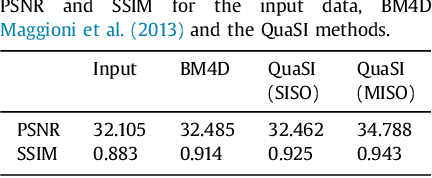
This paper introduces an universal and structure-preserving regularization term, called quantile sparse image (QuaSI) prior. The prior is suitable for denoising images from various medical imaging modalities. We demonstrate its effectiveness on volumetric optical coherence tomography (OCT) and computed tomography (CT) data, which show different noise and image characteristics. OCT offers high-resolution scans of the human retina but is inherently impaired by speckle noise. CT on the other hand has a lower resolution and shows high-frequency noise. For the purpose of denoising, we propose a variational framework based on the QuaSI prior and a Huber data fidelity model that can handle 3-D and 3-D+t data. Efficient optimization is facilitated through the use of an alternating direction method of multipliers (ADMM) scheme and the linearization of the quantile filter. Experiments on multiple datasets emphasize the excellent performance of the proposed method.
Benchmarking Super-Resolution Algorithms on Real Data
Sep 08, 2017Over the past decades, various super-resolution (SR) techniques have been developed to enhance the spatial resolution of digital images. Despite the great number of methodical contributions, there is still a lack of comparative validations of SR under practical conditions, as capturing real ground truth data is a challenging task. Therefore, current studies are either evaluated 1) on simulated data or 2) on real data without a pixel-wise ground truth. To facilitate comprehensive studies, this paper introduces the publicly available Super-Resolution Erlangen (SupER) database that includes real low-resolution images along with high-resolution ground truth data. Our database comprises image sequences with more than 20k images captured from 14 scenes under various types of motions and photometric conditions. The datasets cover four spatial resolution levels using camera hardware binning. With this database, we benchmark 15 single-image and multi-frame SR algorithms. Our experiments quantitatively analyze SR accuracy and robustness under realistic conditions including independent object and camera motion or photometric variations.