 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapted Foundation Models for Breast MRI Triaging in Contrast-Enhanced and Non-Contrast Enhanced Protocols
Nov 08, 2025Background: Magnetic resonance imaging (MRI) has high sensitivity for breast cancer detection, but interpretation is time-consuming. Artificial intelligence may aid in pre-screening. Purpose: To evaluate the DINOv2-based Medical Slice Transformer (MST) for ruling out significant findings (Breast Imaging Reporting and Data System [BI-RADS] >=4) in contrast-enhanced and non-contrast-enhanced abbreviated breast MRI. Materials and Methods: This institutional review board approved retrospective study included 1,847 single-breast MRI examinations (377 BI-RADS >=4) from an in-house dataset and 924 from an external validation dataset (Duke). Four abbreviated protocols were tested: T1-weighted early subtraction (T1sub), diffusion-weighted imaging with b=1500 s/mm2 (DWI1500), DWI1500+T2-weighted (T2w), and T1sub+T2w. Performance was assessed at 90%, 95%, and 97.5% sensitivity using five-fold cross-validation and area under the receiver operating characteristic curve (AUC) analysis. AUC differences were compared with the DeLong test. False negatives were characterized, and attention maps of true positives were rated in the external dataset. Results: A total of 1,448 female patients (mean age, 49 +/- 12 years) were included. T1sub+T2w achieved an AUC of 0.77 +/- 0.04; DWI1500+T2w, 0.74 +/- 0.04 (p=0.15). At 97.5% sensitivity, T1sub+T2w had the highest specificity (19% +/- 7%), followed by DWI1500+T2w (17% +/- 11%). Missed lesions had a mean diameter <10 mm at 95% and 97.5% thresholds for both T1sub and DWI1500, predominantly non-mass enhancements. External validation yielded an AUC of 0.77, with 88% of attention maps rated good or moderate. Conclusion: At 97.5% sensitivity, the MST framework correctly triaged cases without BI-RADS >=4, achieving 19% specificity for contrast-enhanced and 17% for non-contrast-enhanced MRI. Further research is warranted before clinical implementation.
Deep OCT Angiography Image Generation for Motion Artifact Suppression
Jan 08, 2020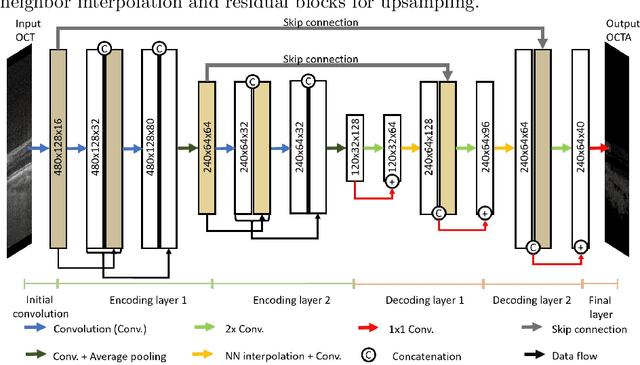
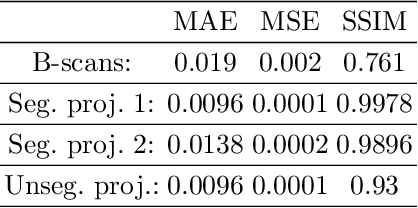
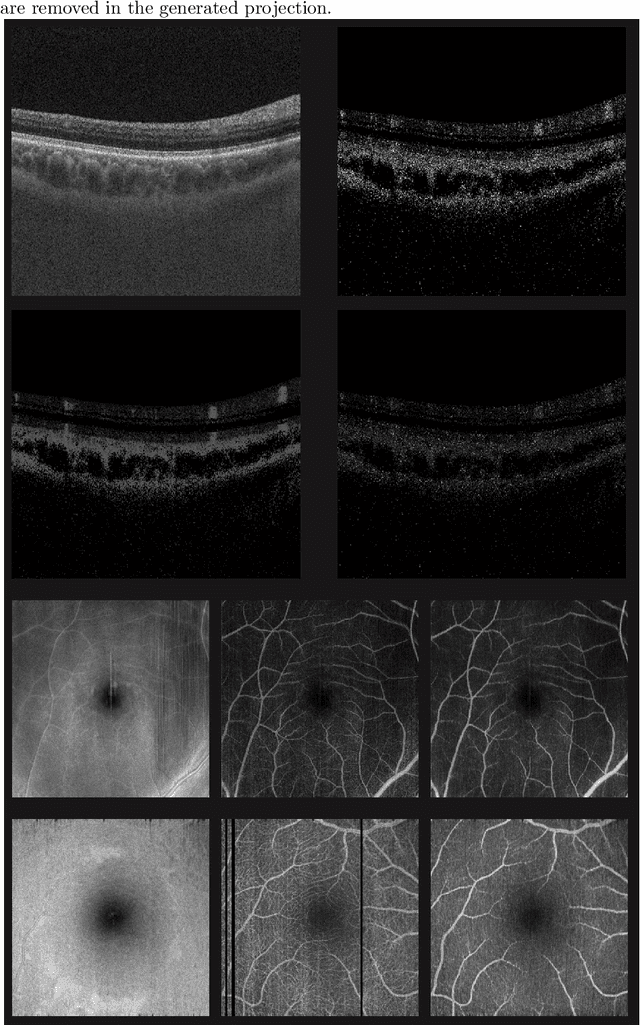
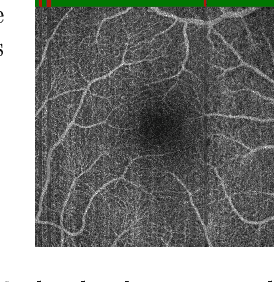
Eye movements, blinking and other motion during the acquisition of optical coherence tomography (OCT) can lead to artifacts, when processed to OCT angiography (OCTA) images. Affected scans emerge as high intensity (white) or missing (black) regions, resulting in lost information. The aim of this research is to fill these gaps using a deep generative model for OCT to OCTA image translation relying on a single intact OCT scan. Therefore, a U-Net is trained to extract the angiographic information from OCT patches. At inference, a detection algorithm finds outlier OCTA scans based on their surroundings, which are then replaced by the trained network. We show that generative models can augment the missing scans. The augmented volumes could then be used for 3-D segmentation or increase the diagnostic value.