 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparative study between vision transformers and CNNs in digital pathology
Jun 01, 2022
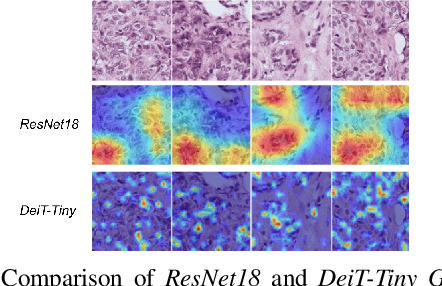


Recently, vision transformers were shown to be capable of outperforming convolutional neural networks when pretrained on sufficient amounts of data. In comparison to convolutional neural networks, vision transformers have a weaker inductive bias and therefore allow a more flexible feature detection. Due to their promising feature detection, this work explores vision transformers for tumor detection in digital pathology whole slide images in four tissue types, and for tissue type identification. We compared the patch-wise classification performance of the vision transformer DeiT-Tiny to the state-of-the-art convolutional neural network ResNet18. Due to the sparse availability of annotated whole slide images, we further compared both models pretrained on large amounts of unlabeled whole-slide images using state-of-the-art self-supervised approaches. The results show that the vision transformer performed slightly better than the ResNet18 for three of four tissue types for tumor detection while the ResNet18 performed slightly better for the remaining tasks. The aggregated predictions of both models on slide level were correlated, indicating that the models captured similar imaging features. All together, the vision transformer models performed on par with the ResNet18 while requiring more effort to train. In order to surpass the performance of convolutional neural networks, vision transformers might require more challenging tasks to benefit from their weak inductive bias.
Deep autofocus with cone-beam CT consistency constraint
Dec 04, 2019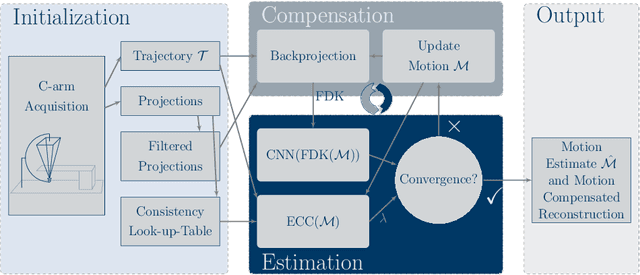
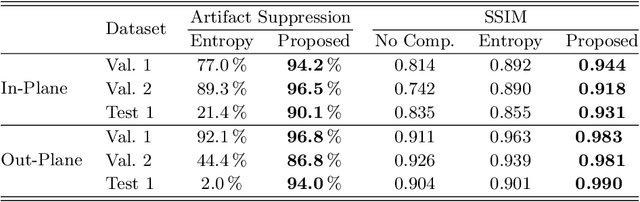
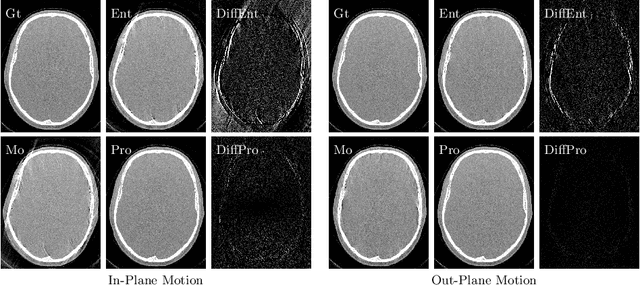
High quality reconstruction with interventional C-arm cone-beam computed tomography (CBCT) requires exact geometry information. If the geometry information is corrupted, e. g., by unexpected patient or system movement, the measured signal is misplaced in the backprojection operation. With prolonged acquisition times of interventional C-arm CBCT the likelihood of rigid patient motion increases. To adapt the backprojection operation accordingly, a motion estimation strategy is necessary. Recently, a novel learning-based approach was proposed, capable of compensating motions within the acquisition plane. We extend this method by a CBCT consistency constraint, which was proven to be efficient for motions perpendicular to the acquisition plane. By the synergistic combination of these two measures, in and out-plane motion is well detectable, achieving an average artifact suppression of 93 [percent]. This outperforms the entropy-based state-of-the-art autofocus measure which achieves on average an artifact suppression of 54 [percent].
Projection-to-Projection Translation for Hybrid X-ray and Magnetic Resonance Imaging
Nov 19, 2019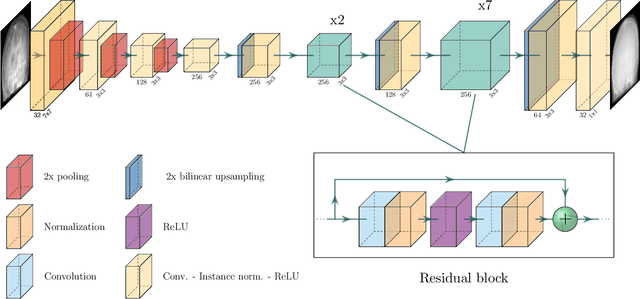
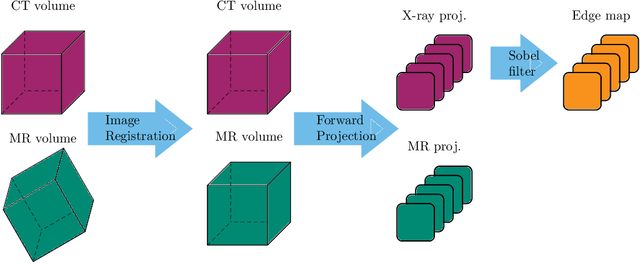
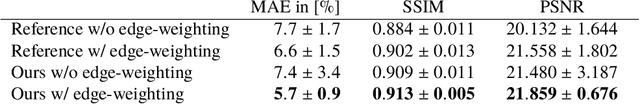

Hybrid X-ray and magnetic resonance (MR) imaging promises large potential in interventional medical imaging applications due to the broad variety of contrast of MRI combined with fast imaging of X-ray-based modalities. To fully utilize the potential of the vast amount of existing image enhancement techniques, the corresponding information from both modalities must be present in the same domain. For image-guided interventional procedures, X-ray fluoroscopy has proven to be the modality of choice. Synthesizing one modality from another in this case is an ill-posed problem due to ambiguous signal and overlapping structures in projective geometry. To take on these challenges, we present a learning-based solution to MR to X-ray projection-to-projection translation. We propose an image generator network that focuses on high representation capacity in higher resolution layers to allow for accurate synthesis of fine details in the projection images. Additionally, a weighting scheme in the loss computation that favors high-frequency structures is proposed to focus on the important details and contours in projection imaging. The proposed extensions prove valuable in generating X-ray projection images with natural appearance. Our approach achieves a deviation from the ground truth of only $6$% and structural similarity measure of $0.913\,\pm\,0.005$. In particular the high frequency weighting assists in generating projection images with sharp appearance and reduces erroneously synthesized fine details.
Multi-modal Deep Guided Filtering for Comprehensible Medical Image Processing
Nov 18, 2019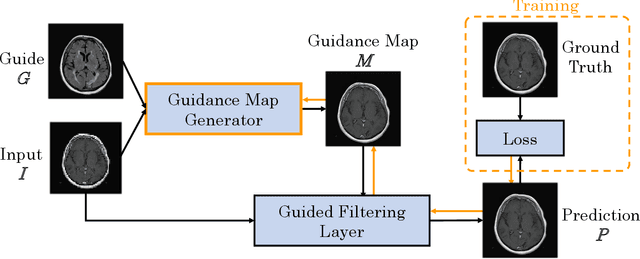
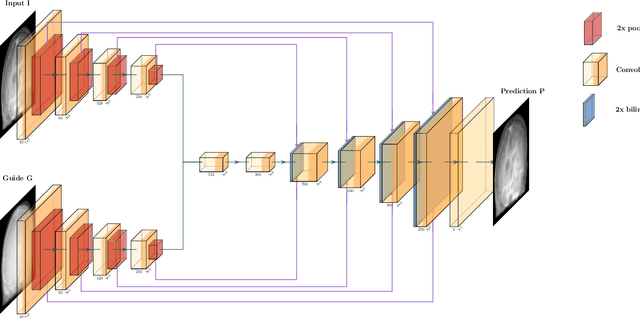
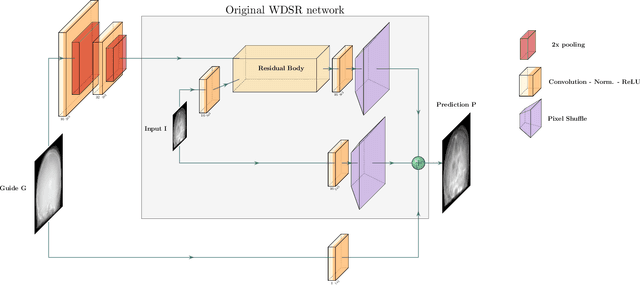
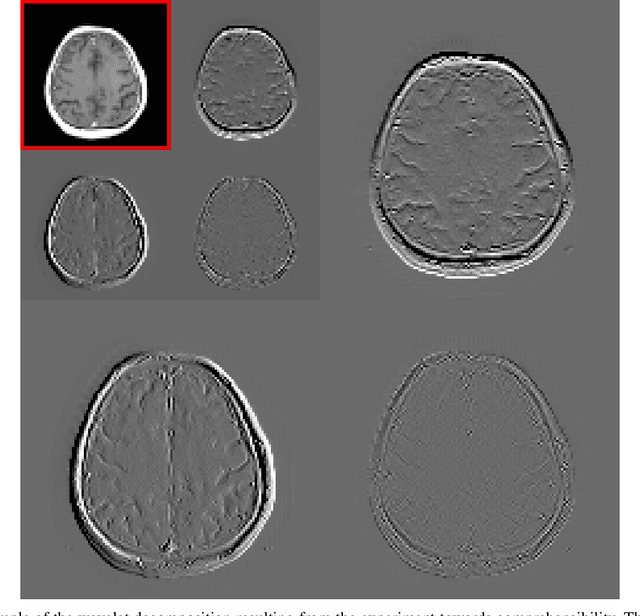
Deep learning-based image processing is capable of creating highly appealing results. However, it is still widely considered as a "blackbox" transformation. In medical imaging, this lack of comprehensibility of the results is a sensitive issue. The integration of known operators into the deep learning environment has proven to be advantageous for the comprehensibility and reliability of the computations. Consequently, we propose the use of the locally linear guided filter in combination with a learned guidance map for general purpose medical image processing. The output images are only processed by the guided filter while the guidance map can be trained to be task-optimal in an end-to-end fashion. We investigate the performance based on two popular tasks: image super resolution and denoising. The evaluation is conducted based on pairs of multi-modal magnetic resonance imaging and cross-modal computed tomography and magnetic resonance imaging datasets. For both tasks, the proposed approach is on par with state-of-the-art approaches. Additionally, we can show that the input image's content is almost unchanged after the processing which is not the case for conventional deep learning approaches. On top, the proposed pipeline offers increased robustness against degraded input as well as adversarial attacks.
Image Quality Assessment for Rigid Motion Compensation
Oct 09, 2019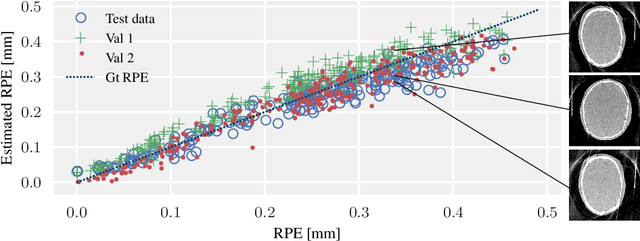
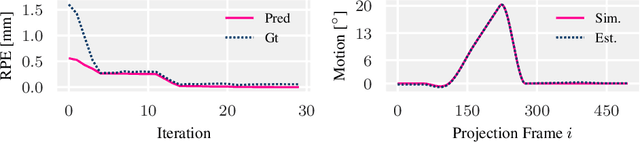
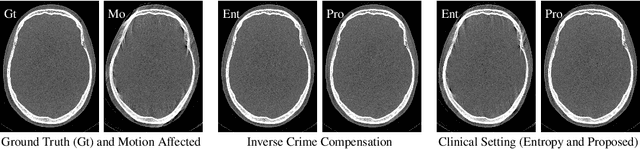
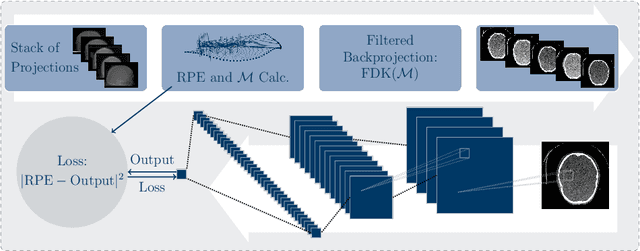
Diagnostic stroke imaging with C-arm cone-beam computed tomography (CBCT) enables reduction of time-to-therapy for endovascular procedures. However, the prolonged acquisition time compared to helical CT increases the likelihood of rigid patient motion. Rigid motion corrupts the geometry alignment assumed during reconstruction, resulting in image blurring or streaking artifacts. To reestablish the geometry, we estimate the motion trajectory by an autofocus method guided by a neural network, which was trained to regress the reprojection error, based on the image information of a reconstructed slice. The network was trained with CBCT scans from 19 patients and evaluated using an additional test patient. It adapts well to unseen motion amplitudes and achieves superior results in a motion estimation benchmark compared to the commonly used entropy-based method.
Learning with Known Operators reduces Maximum Training Error Bounds
Jul 03, 2019
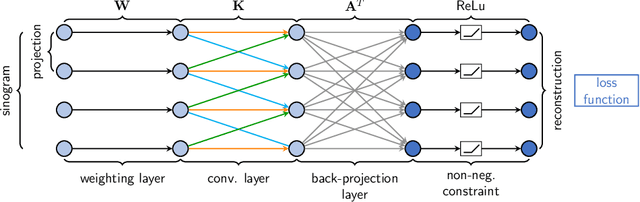
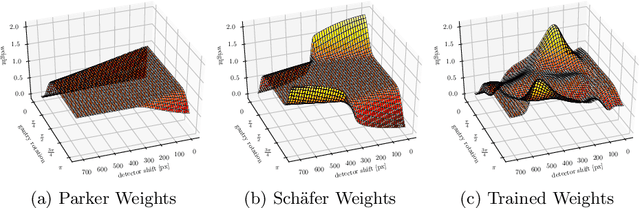
We describe an approach for incorporating prior knowledge into machine learning algorithms. We aim at applications in physics and signal processing in which we know that certain operations must be embedded into the algorithm. Any operation that allows computation of a gradient or sub-gradient towards its inputs is suited for our framework. We derive a maximal error bound for deep nets that demonstrates that inclusion of prior knowledge results in its reduction. Furthermore, we also show experimentally that known operators reduce the number of free parameters. We apply this approach to various tasks ranging from CT image reconstruction over vessel segmentation to the derivation of previously unknown imaging algorithms. As such the concept is widely applicable for many researchers in physics, imaging, and signal processing. We assume that our analysis will support further investigation of known operators in other fields of physics, imaging, and signal processing.
PYRO-NN: Python Reconstruction Operators in Neural Networks
Apr 30, 2019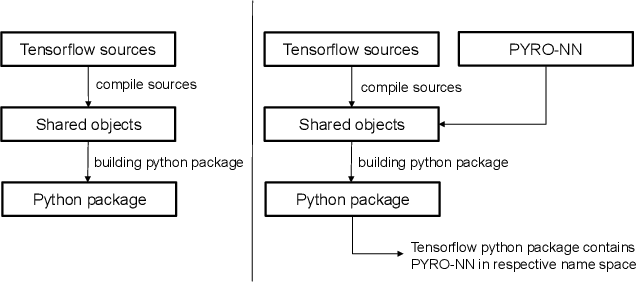
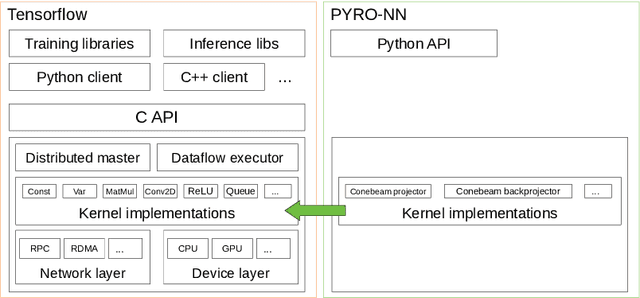
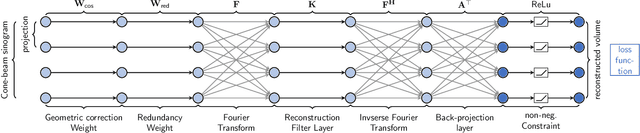
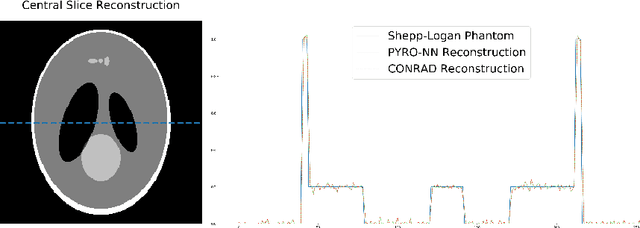
Purpose: Recently, several attempts were conducted to transfer deep learning to medical image reconstruction. An increasingly number of publications follow the concept of embedding the CT reconstruction as a known operator into a neural network. However, most of the approaches presented lack an efficient CT reconstruction framework fully integrated into deep learning environments. As a result, many approaches are forced to use workarounds for mathematically unambiguously solvable problems. Methods: PYRO-NN is a generalized framework to embed known operators into the prevalent deep learning framework Tensorflow. The current status includes state-of-the-art parallel-, fan- and cone-beam projectors and back-projectors accelerated with CUDA provided as Tensorflow layers. On top, the framework provides a high level Python API to conduct FBP and iterative reconstruction experiments with data from real CT systems. Results: The framework provides all necessary algorithms and tools to design end-to-end neural network pipelines with integrated CT reconstruction algorithms. The high level Python API allows a simple use of the layers as known from Tensorflow. To demonstrate the capabilities of the layers, the framework comes with three baseline experiments showing a cone-beam short scan FDK reconstruction, a CT reconstruction filter learning setup, and a TV regularized iterative reconstruction. All algorithms and tools are referenced to a scientific publication and are compared to existing non deep learning reconstruction frameworks. The framework is available as open-source software at \url{https://github.com/csyben/PYRO-NN}. Conclusions: PYRO-NN comes with the prevalent deep learning framework Tensorflow and allows to setup end-to-end trainable neural networks in the medical image reconstruction context. We believe that the framework will be a step towards reproducible research
Deriving Neural Network Architectures using Precision Learning: Parallel-to-fan beam Conversion
Oct 23, 2018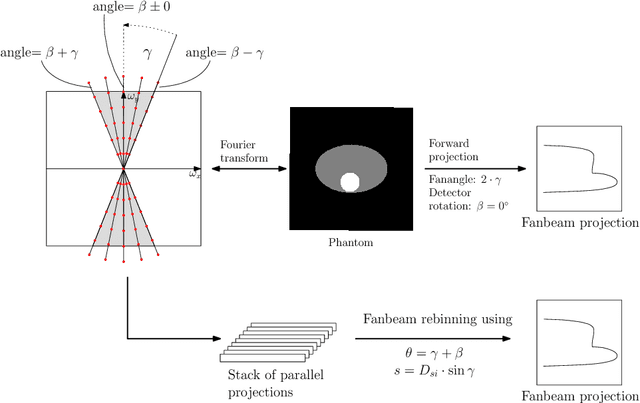
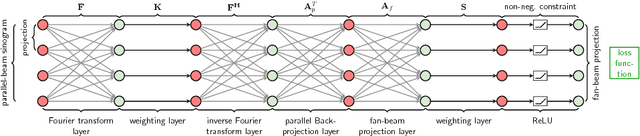

In this paper, we derive a neural network architecture based on an analytical formulation of the parallel-to-fan beam conversion problem following the concept of precision learning. The network allows to learn the unknown operators in this conversion in a data-driven manner avoiding interpolation and potential loss of resolution. Integration of known operators results in a small number of trainable parameters that can be estimated from synthetic data only. The concept is evaluated in the context of Hybrid MRI/X-ray imaging where transformation of the parallel-beam MRI projections to fan-beam X-ray projections is required. The proposed method is compared to a traditional rebinning method. The results demonstrate that the proposed method is superior to ray-by-ray interpolation and is able to deliver sharper images using the same amount of parallel-beam input projections which is crucial for interventional applications. We believe that this approach forms a basis for further work uniting deep learning, signal processing, physics, and traditional pattern recognition.
User Loss -- A Forced-Choice-Inspired Approach to Train Neural Networks directly by User Interaction
Jul 24, 2018

In this paper, we investigate whether is it possible to train a neural network directly from user inputs. We consider this approach to be highly relevant for applications in which the point of optimality is not well-defined and user-dependent. Our application is medical image denoising which is essential in fluoroscopy imaging. In this field every user, i.e. physician, has a different flavor and image quality needs to be tailored towards each individual. To address this important problem, we propose to construct a loss function derived from a forced-choice experiment. In order to make the learning problem feasible, we operate in the domain of precision learning, i.e., we inspire the network architecture by traditional signal processing methods in order to reduce the number of trainable parameters. The algorithm that was used for this is a Laplacian pyramid with only six trainable parameters. In the experimental results, we demonstrate that two image experts who prefer different filter characteristics between sharpness and de-noising can be created using our approach. Also models trained for a specific user perform best on this users test data. This approach opens the way towards implementation of direct user feedback in deep learning and is applicable for a wide range of application.
Precision Learning: Reconstruction Filter Kernel Discretization
Jul 09, 2018
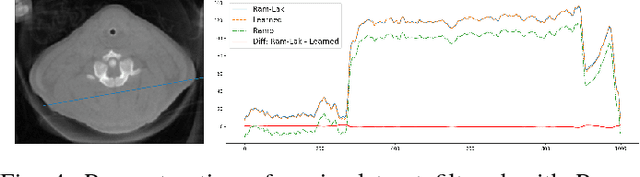
In this paper, we present substantial evidence that a deep neural network will intrinsically learn the appropriate way to discretize the ideal continuous reconstruction filter. Currently, the Ram-Lak filter or heuristic filters which impose different noise assumptions are used for filtered back-projection. All of these, however, inhibit a fully data-driven reconstruction deep learning approach. In addition, the heuristic filters are not chosen in an optimal sense. To tackle this issue, we propose a formulation to directly learn the reconstruction filter. The filter is initialized with the ideal Ramp filter as a strong pre-training and learned in frequency domain. We compare the learned filter with the Ram-Lak and the Ramp filter on a numerical phantom as well as on a real CT dataset. The results show that the network properly discretizes the continuous Ramp filter and converges towards the Ram-Lak solution. In our view these observations are interesting to gain a better understanding of deep learning techniques and traditional analytic techniques such as Wiener filtering and discretization theory. Furthermore, this will allow fully trainable data-driven reconstruction deep learning approaches.