 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoutine Usage of AI-based Chest X-ray Reading Support in a Multi-site Medical Supply Center
Oct 17, 2022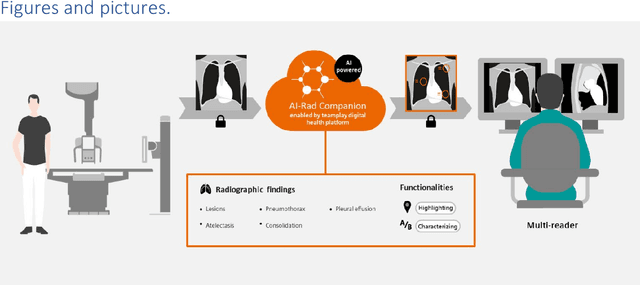
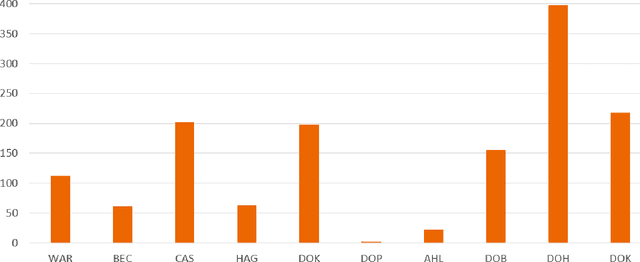
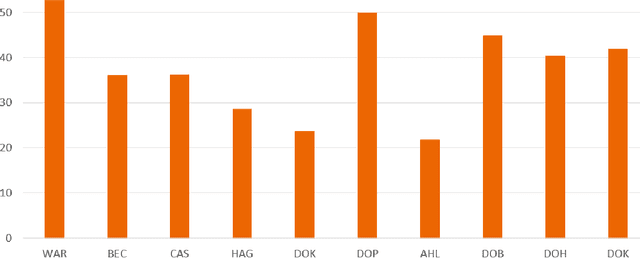
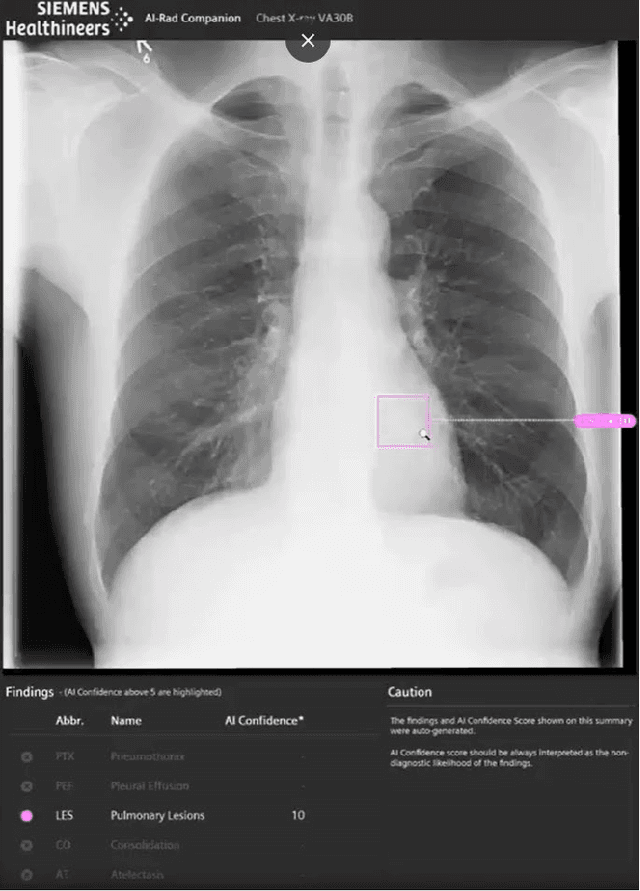
Research question: How can we establish an AI support for reading of chest X-rays in clinical routine and which benefits emerge for the clinicians and radiologists. Can it perform 24/7 support for practicing clinicians? 2. Findings: We installed an AI solution for Chest X-ray in a given structure (MVZ Uhlenbrock & Partner, Germany). We could demonstrate the practicability, performance, and benefits in 10 connected clinical sites. 3. Meaning: A commercially available AI solution for the evaluation of Chest X-ray images is able to help radiologists and clinical colleagues 24/7 in a complex environment. The system performs in a robust manner, supporting radiologists and clinical colleagues in their important decisions, in practises and hospitals regardless of the user and X-ray system type producing the image-data.
X-ray Scatter Estimation Using Deep Splines
Jan 22, 2021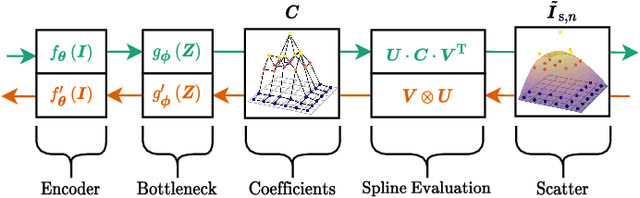
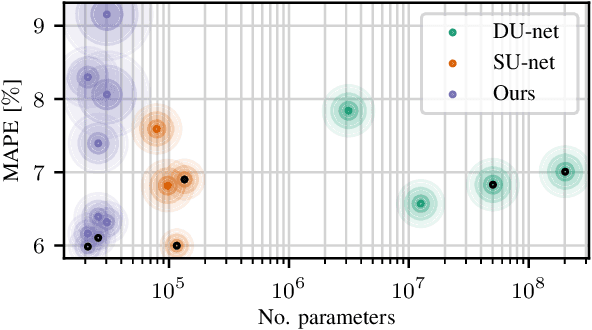
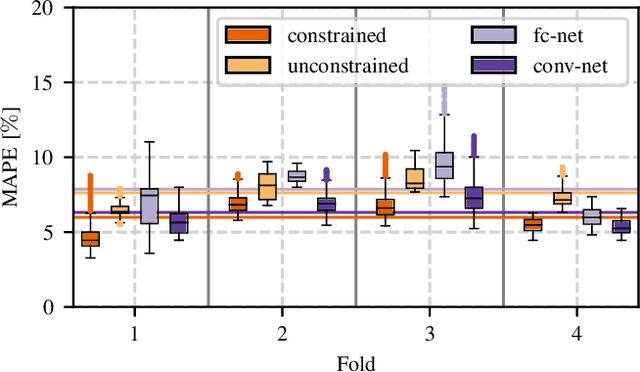
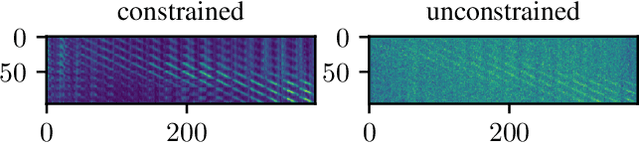
Algorithmic X-ray scatter compensation is a desirable technique in flat-panel X-ray imaging and cone-beam computed tomography. State-of-the-art U-net based image translation approaches yielded promising results. As there are no physics constraints applied to the output of the U-Net, it cannot be ruled out that it yields spurious results. Unfortunately, those may be misleading in the context of medical imaging. To overcome this problem, we propose to embed B-splines as a known operator into neural networks. This inherently limits their predictions to well-behaved and smooth functions. In a study using synthetic head and thorax data as well as real thorax phantom data, we found that our approach performed on par with U-net when comparing both algorithms based on quantitative performance metrics. However, our approach not only reduces runtime and parameter complexity, but we also found it much more robust to unseen noise levels. While the U-net responded with visible artifacts, our approach preserved the X-ray signal's frequency characteristics.
2-D Respiration Navigation Framework for 3-D Continuous Cardiac Magnetic Resonance Imaging
Dec 26, 2020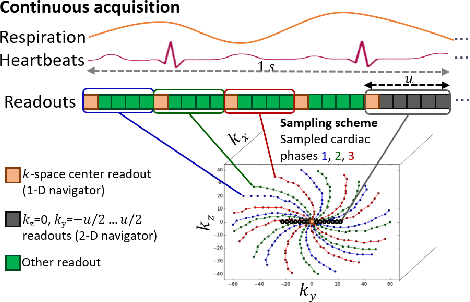

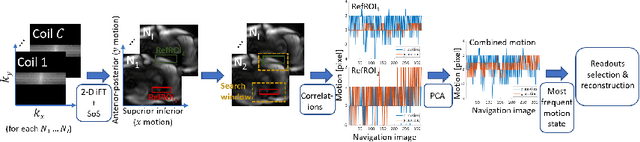
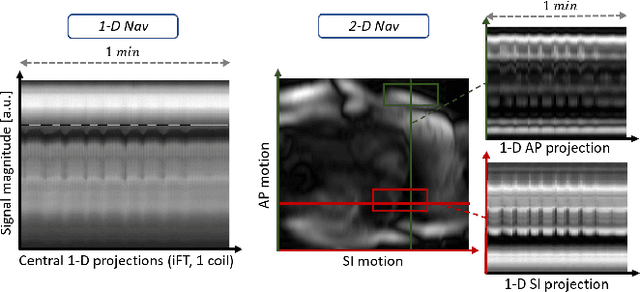
Continuous protocols for cardiac magnetic resonance imaging enable sampling of the cardiac anatomy simultaneously resolved into cardiac phases. To avoid respiration artifacts, associated motion during the scan has to be compensated for during reconstruction. In this paper, we propose a sampling adaption to acquire 2-D respiration information during a continuous scan. Further, we develop a pipeline to extract the different respiration states from the acquired signals, which are used to reconstruct data from one respiration phase. Our results show the benefit of the proposed workflow on the image quality compared to no respiration compensation, as well as a previous 1-D respiration navigation approach.
Reconstruction of Voxels with Position- and Angle-Dependent Weightings
Oct 27, 2020

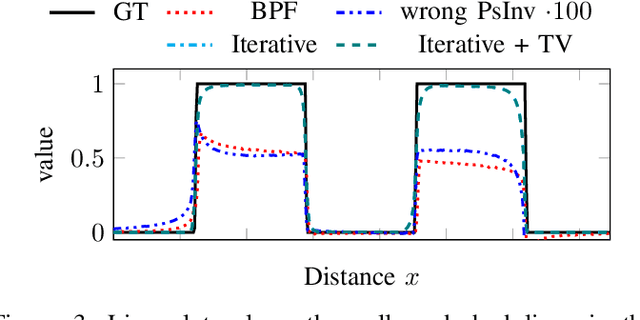
The reconstruction problem of voxels with individual weightings can be modeled a position- and angle- dependent function in the forward-projection. This changes the system matrix and prohibits to use standard filtered backprojection. In this work we first formulate this reconstruction problem in terms of a system matrix and weighting part. We compute the pseudoinverse and show that the solution is rank-deficient and hence very ill posed. This is a fundamental limitation for reconstruction. We then derive an iterative solution and experimentally show its uperiority to any closed-form solution.
Simultaneous Estimation of X-ray Back-Scatter and Forward-Scatter using Multi-Task Learning
Jul 08, 2020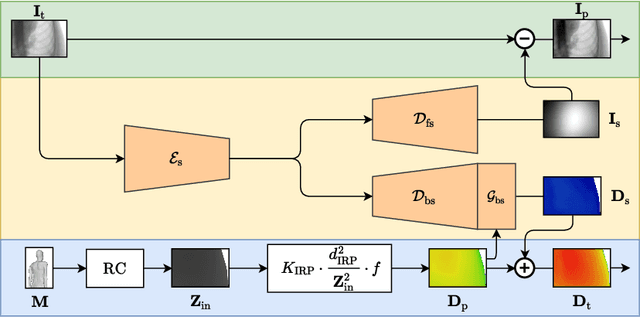
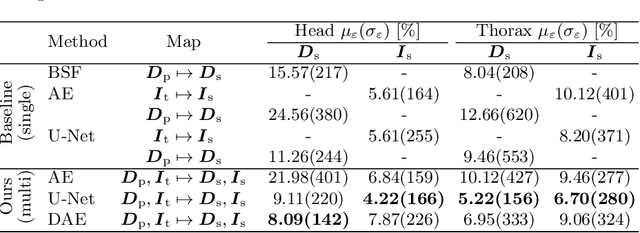
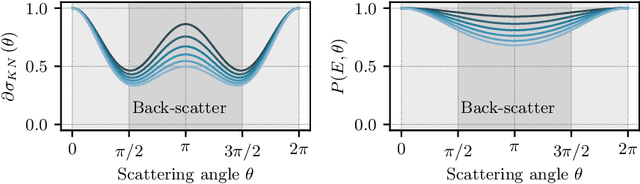

Scattered radiation is a major concern impacting X-ray image-guided procedures in two ways. First, back-scatter significantly contributes to patient (skin) dose during complicated interventions. Second, forward-scattered radiation reduces contrast in projection images and introduces artifacts in 3-D reconstructions. While conventionally employed anti-scatter grids improve image quality by blocking X-rays, the additional attenuation due to the anti-scatter grid at the detector needs to be compensated for by a higher patient entrance dose. This also increases the room dose affecting the staff caring for the patient. For skin dose quantification, back-scatter is usually accounted for by applying pre-determined scalar back-scatter factors or linear point spread functions to a primary kerma forward projection onto a patient surface point. However, as patients come in different shapes, the generalization of conventional methods is limited. Here, we propose a novel approach combining conventional techniques with learning-based methods to simultaneously estimate the forward-scatter reaching the detector as well as the back-scatter affecting the patient skin dose. Knowing the forward-scatter, we can correct X-ray projections, while a good estimate of the back-scatter component facilitates an improved skin dose assessment. To simultaneously estimate forward-scatter as well as back-scatter, we propose a multi-task approach for joint back- and forward-scatter estimation by combining X-ray physics with neural networks. We show that, in theory, highly accurate scatter estimation in both cases is possible. In addition, we identify research directions for our multi-task framework and learning-based scatter estimation in general.
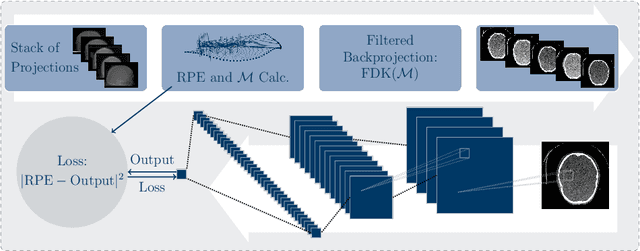
Appearance Learning for Image-based Motion Estimation in Tomography
Jun 18, 2020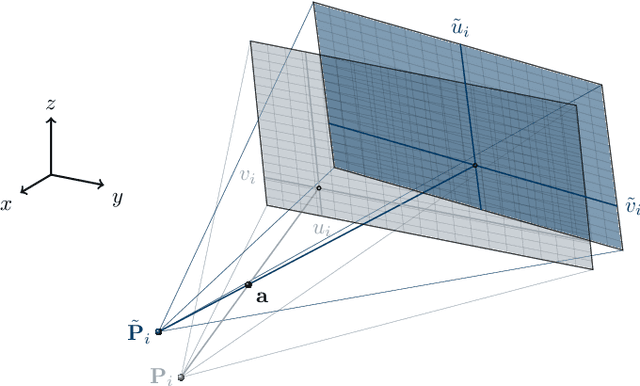
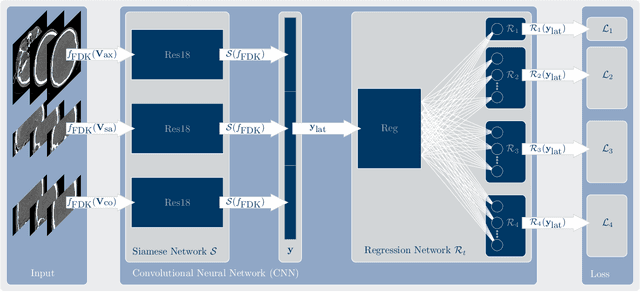
In tomographic imaging, anatomical structures are reconstructed by applying a pseudo-inverse forward model to acquired signals. Geometric information within this process is usually depending on the system setting only, i. e., the scanner position or readout direction. Patient motion therefore corrupts the geometry alignment in the reconstruction process resulting in motion artifacts. We propose an appearance learning approach recognizing the structures of rigid motion independently from the scanned object. To this end, we train a siamese triplet network to predict the reprojection error (RPE) for the complete acquisition as well as an approximate distribution of the RPE along the single views from the reconstructed volume in a multi-task learning approach. The RPE measures the motioninduced geometric deviations independent of the object based on virtual marker positions, which are available during training. We train our network using 27 patients and deploy a 21-4-2 split for training, validation and testing. In average, we achieve a residual mean RPE of 0.013mm with an inter-patient standard deviation of 0.022 mm. This is twice the accuracy compared to previously published results. In a motion estimation benchmark the proposed approach achieves superior results in comparison with two state-of-the-art measures in nine out of twelve experiments. The clinical applicability of the proposed method is demonstrated on a motion-affected clinical dataset.
Data Consistent CT Reconstruction from Insufficient Data with Learned Prior Images
May 20, 2020
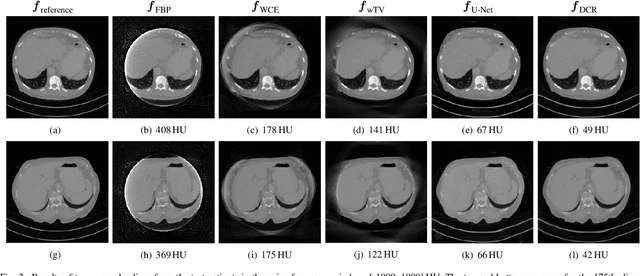

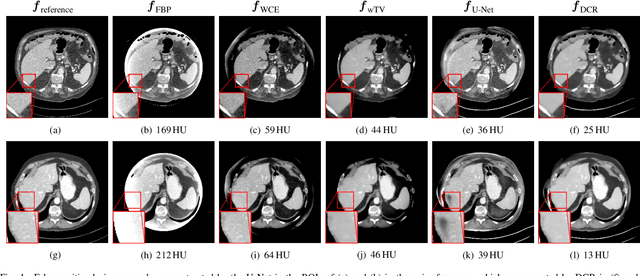
Image reconstruction from insufficient data is common in computed tomography (CT), e.g., image reconstruction from truncated data, limited-angle data and sparse-view data. Deep learning has achieved impressive results in this field. However, the robustness of deep learning methods is still a concern for clinical applications due to the following two challenges: a) With limited access to sufficient training data, a learned deep learning model may not generalize well to unseen data; b) Deep learning models are sensitive to noise. Therefore, the quality of images processed by neural networks only may be inadequate. In this work, we investigate the robustness of deep learning in CT image reconstruction by showing false negative and false positive lesion cases. Since learning-based images with incorrect structures are likely not consistent with measured projection data, we propose a data consistent reconstruction (DCR) method to improve their image quality, which combines the advantages of compressed sensing and deep learning: First, a prior image is generated by deep learning. Afterwards, unmeasured projection data are inpainted by forward projection of the prior image. Finally, iterative reconstruction with reweighted total variation regularization is applied, integrating data consistency for measured data and learned prior information for missing data. The efficacy of the proposed method is demonstrated in cone-beam CT with truncated data, limited-angle data and sparse-view data, respectively. For example, for truncated data, DCR achieves a mean root-mean-square error of 24 HU and a mean structure similarity index of 0.999 inside the field-of-view for different patients in the noisy case, while the state-of-the-art U-Net method achieves 55 HU and 0.995 respectively for these two metrics.
Field of View Extension in Computed Tomography Using Deep Learning Prior
Dec 09, 2019
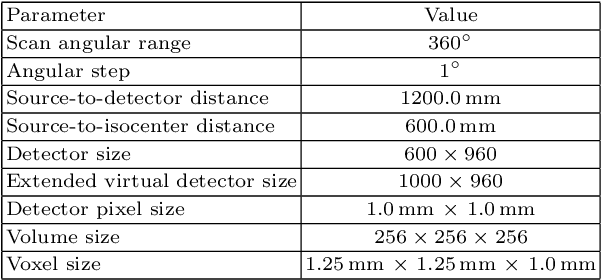
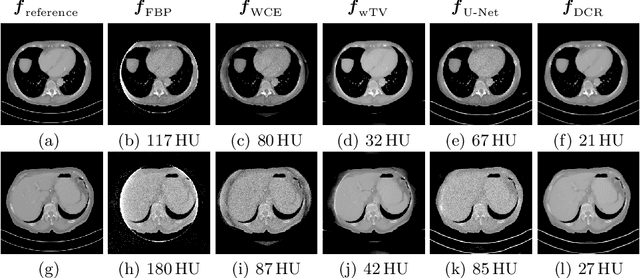
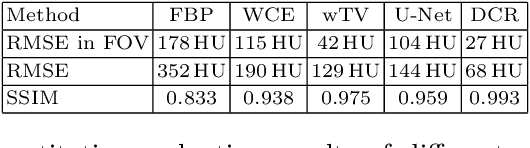
In computed tomography (CT), data truncation is a common problem. Images reconstructed by the standard filtered back-projection algorithm from truncated data suffer from cupping artifacts inside the field-of-view (FOV), while anatomical structures are severely distorted or missing outside the FOV. Deep learning, particularly the U-Net, has been applied to extend the FOV as a post-processing method. Since image-to-image prediction neglects the data fidelity to measured projection data, incorrect structures, even inside the FOV, might be reconstructed by such an approach. Therefore, generating reconstructed images directly from a post-processing neural network is inadequate. In this work, we propose a data consistent reconstruction method, which utilizes deep learning reconstruction as prior for extrapolating truncated projections and a conventional iterative reconstruction to constrain the reconstruction consistent to measured raw data. Its efficacy is demonstrated in our study, achieving small average root-mean-square error of 24 HU inside the FOV and a high structure similarity index of 0.993 for the whole body area on a test patient's CT data.
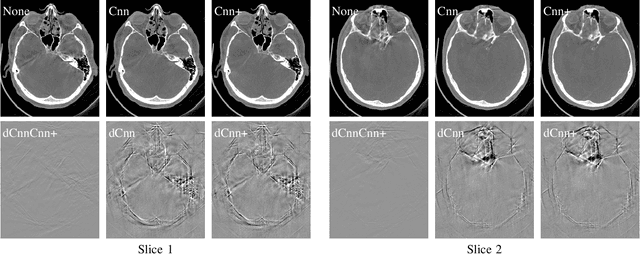
Deep autofocus with cone-beam CT consistency constraint
Dec 04, 2019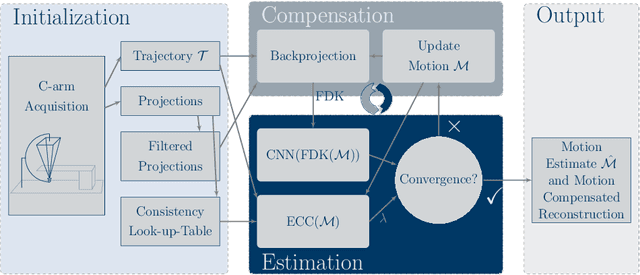
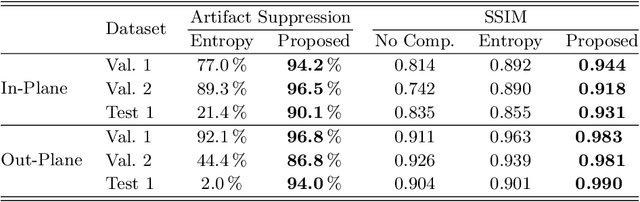
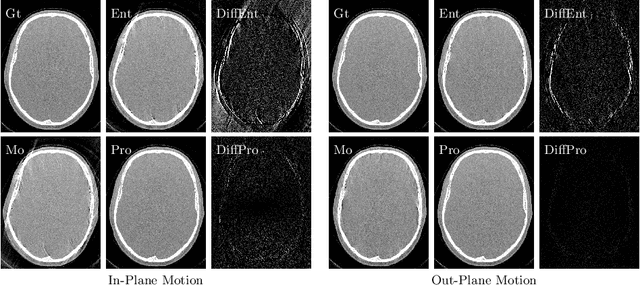
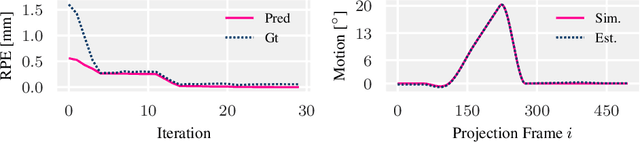
High quality reconstruction with interventional C-arm cone-beam computed tomography (CBCT) requires exact geometry information. If the geometry information is corrupted, e. g., by unexpected patient or system movement, the measured signal is misplaced in the backprojection operation. With prolonged acquisition times of interventional C-arm CBCT the likelihood of rigid patient motion increases. To adapt the backprojection operation accordingly, a motion estimation strategy is necessary. Recently, a novel learning-based approach was proposed, capable of compensating motions within the acquisition plane. We extend this method by a CBCT consistency constraint, which was proven to be efficient for motions perpendicular to the acquisition plane. By the synergistic combination of these two measures, in and out-plane motion is well detectable, achieving an average artifact suppression of 93 [percent]. This outperforms the entropy-based state-of-the-art autofocus measure which achieves on average an artifact suppression of 54 [percent].
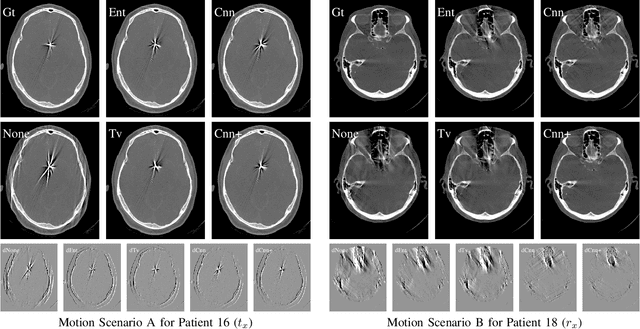
Image Quality Assessment for Rigid Motion Compensation
Oct 09, 2019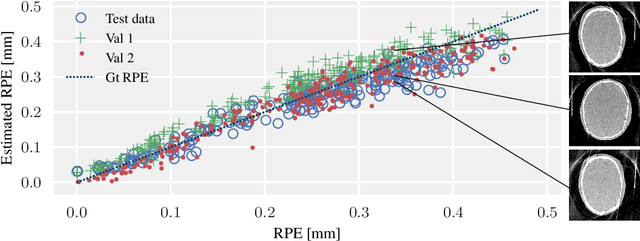
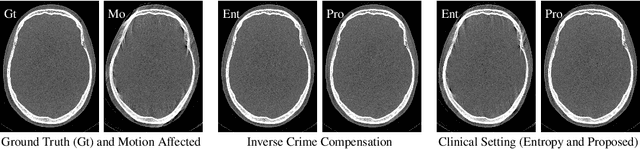
Diagnostic stroke imaging with C-arm cone-beam computed tomography (CBCT) enables reduction of time-to-therapy for endovascular procedures. However, the prolonged acquisition time compared to helical CT increases the likelihood of rigid patient motion. Rigid motion corrupts the geometry alignment assumed during reconstruction, resulting in image blurring or streaking artifacts. To reestablish the geometry, we estimate the motion trajectory by an autofocus method guided by a neural network, which was trained to regress the reprojection error, based on the image information of a reconstructed slice. The network was trained with CBCT scans from 19 patients and evaluated using an additional test patient. It adapts well to unseen motion amplitudes and achieves superior results in a motion estimation benchmark compared to the commonly used entropy-based method.