 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Consistent CT Reconstruction from Insufficient Data with Learned Prior Images
May 20, 2020
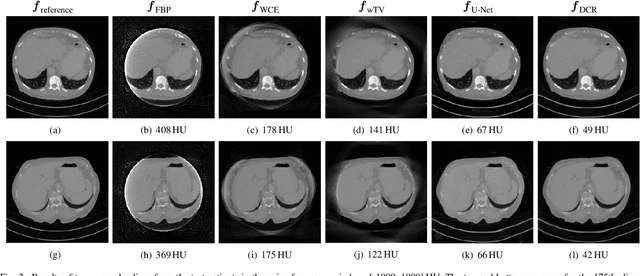

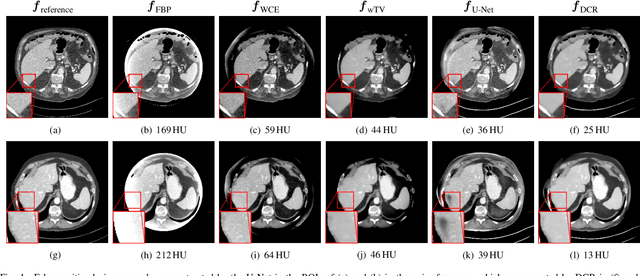
Image reconstruction from insufficient data is common in computed tomography (CT), e.g., image reconstruction from truncated data, limited-angle data and sparse-view data. Deep learning has achieved impressive results in this field. However, the robustness of deep learning methods is still a concern for clinical applications due to the following two challenges: a) With limited access to sufficient training data, a learned deep learning model may not generalize well to unseen data; b) Deep learning models are sensitive to noise. Therefore, the quality of images processed by neural networks only may be inadequate. In this work, we investigate the robustness of deep learning in CT image reconstruction by showing false negative and false positive lesion cases. Since learning-based images with incorrect structures are likely not consistent with measured projection data, we propose a data consistent reconstruction (DCR) method to improve their image quality, which combines the advantages of compressed sensing and deep learning: First, a prior image is generated by deep learning. Afterwards, unmeasured projection data are inpainted by forward projection of the prior image. Finally, iterative reconstruction with reweighted total variation regularization is applied, integrating data consistency for measured data and learned prior information for missing data. The efficacy of the proposed method is demonstrated in cone-beam CT with truncated data, limited-angle data and sparse-view data, respectively. For example, for truncated data, DCR achieves a mean root-mean-square error of 24 HU and a mean structure similarity index of 0.999 inside the field-of-view for different patients in the noisy case, while the state-of-the-art U-Net method achieves 55 HU and 0.995 respectively for these two metrics.
Data Consistent Artifact Reduction for Limited Angle Tomography with Deep Learning Prior
Aug 28, 2019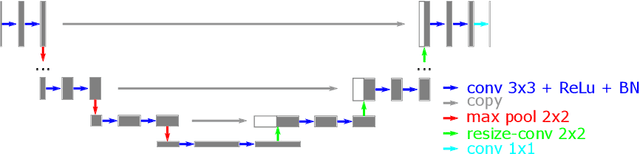
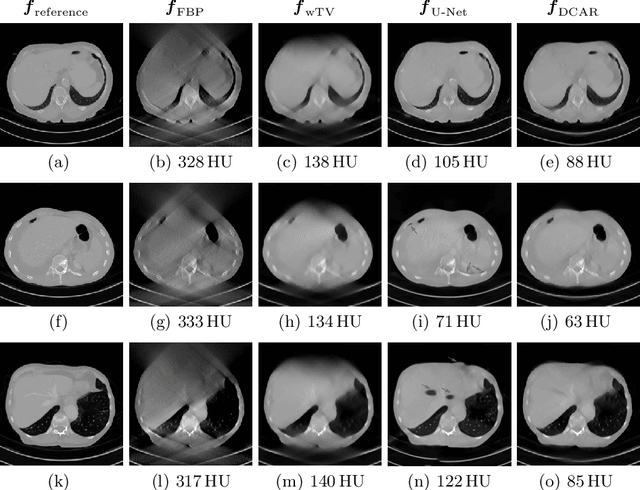
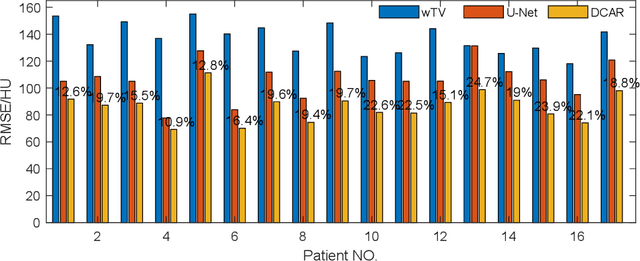
Robustness of deep learning methods for limited angle tomography is challenged by two major factors: a) due to insufficient training data the network may not generalize well to unseen data; b) deep learning methods are sensitive to noise. Thus, generating reconstructed images directly from a neural network appears inadequate. We propose to constrain the reconstructed images to be consistent with the measured projection data, while the unmeasured information is complemented by learning based methods. For this purpose, a data consistent artifact reduction (DCAR) method is introduced: First, a prior image is generated from an initial limited angle reconstruction via deep learning as a substitute for missing information. Afterwards, a conventional iterative reconstruction algorithm is applied, integrating the data consistency in the measured angular range and the prior information in the missing angular range. This ensures data integrity in the measured area, while inaccuracies incorporated by the deep learning prior lie only in areas where no information is acquired. The proposed DCAR method achieves significant image quality improvement: for 120-degree cone-beam limited angle tomography more than 10% RMSE reduction in noise-free case and more than 24% RMSE reduction in noisy case compared with a state-of-the-art U-Net based method.
Scale-Space Anisotropic Total Variation for Limited Angle Tomography
Jan 29, 2018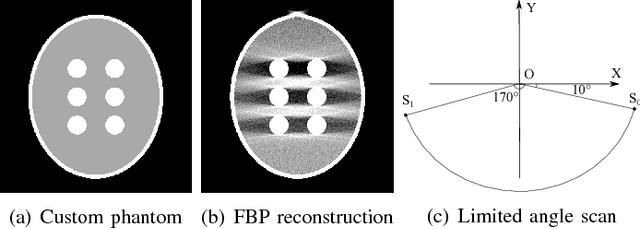
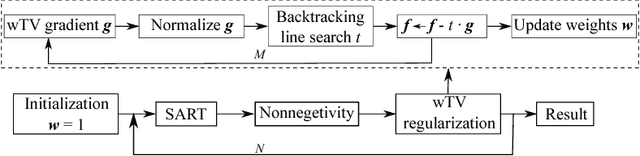
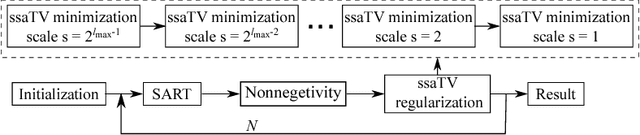

This paper addresses streak reduction in limited angle tomography. Although the iterative reweighted total variation (wTV) algorithm reduces small streaks well, it is rather inept at eliminating large ones since total variation (TV) regularization is scale-dependent and may regard these streaks as homogeneous areas. Hence, the main purpose of this paper is to reduce streak artifacts at various scales. We propose the scale-space anisotropic total variation (ssaTV) algorithm in two different implementations. The first implementation (ssaTV-1) utilizes an anisotropic gradient-like operator which uses 2s neighboring pixels along the streaks' normal direction at each scale s. The second implementation (ssaTV-2) makes use of anisotropic down-sampling and up-sampling operations, similarly oriented along the streaks' normal direction, to apply TV regularization at various scales. Experiments on numerical and clinical data demonstrate that both ssaTV algorithms reduce streak artifacts more effectively and efficiently than wTV, particularly when using multiple scales.