 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Estimation of X-ray Back-Scatter and Forward-Scatter using Multi-Task Learning
Jul 08, 2020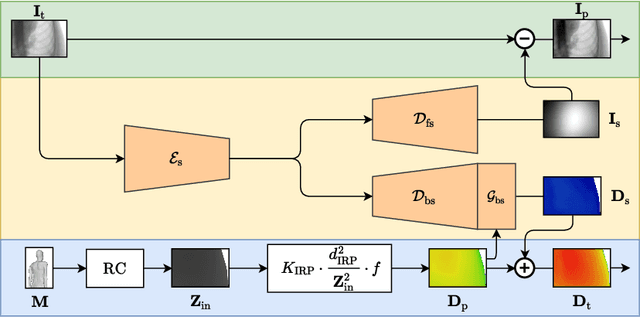
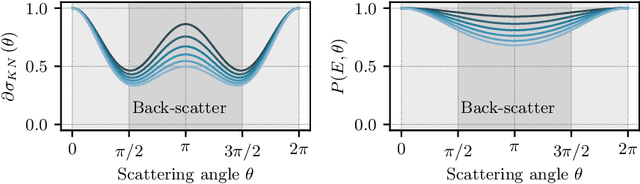

Scattered radiation is a major concern impacting X-ray image-guided procedures in two ways. First, back-scatter significantly contributes to patient (skin) dose during complicated interventions. Second, forward-scattered radiation reduces contrast in projection images and introduces artifacts in 3-D reconstructions. While conventionally employed anti-scatter grids improve image quality by blocking X-rays, the additional attenuation due to the anti-scatter grid at the detector needs to be compensated for by a higher patient entrance dose. This also increases the room dose affecting the staff caring for the patient. For skin dose quantification, back-scatter is usually accounted for by applying pre-determined scalar back-scatter factors or linear point spread functions to a primary kerma forward projection onto a patient surface point. However, as patients come in different shapes, the generalization of conventional methods is limited. Here, we propose a novel approach combining conventional techniques with learning-based methods to simultaneously estimate the forward-scatter reaching the detector as well as the back-scatter affecting the patient skin dose. Knowing the forward-scatter, we can correct X-ray projections, while a good estimate of the back-scatter component facilitates an improved skin dose assessment. To simultaneously estimate forward-scatter as well as back-scatter, we propose a multi-task approach for joint back- and forward-scatter estimation by combining X-ray physics with neural networks. We show that, in theory, highly accurate scatter estimation in both cases is possible. In addition, we identify research directions for our multi-task framework and learning-based scatter estimation in general.
Analyzing an Imitation Learning Network for Fundus Image Registration Using a Divide-and-Conquer Approach
Dec 19, 2019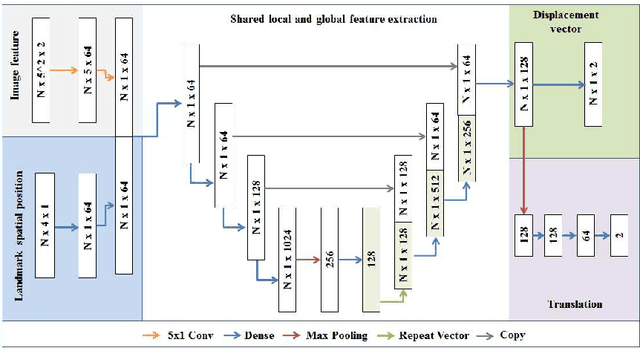
Comparison of microvascular circulation on fundoscopic images is a non-invasive clinical indication for the diagnosis and monitoring of diseases, such as diabetes and hypertensions. The differences between intra-patient images can be assessed quantitatively by registering serial acquisitions. Due to the variability of the images (i.e. contrast, luminosity) and the anatomical changes of the retina, the registration of fundus images remains a challenging task. Recently, several deep learning approaches have been proposed to register fundus images in an end-to-end fashion, achieving remarkable results. However, the results are difficult to interpret and analyze. In this work, we propose an imitation learning framework for the registration of 2D color funduscopic images for a wide range of applications such as disease monitoring, image stitching and super-resolution. We follow a divide-and-conquer approach to improve the interpretability of the proposed network, and analyze both the influence of the input image and the hyperparameters on the registration result. The results show that the proposed registration network reduces the initial target registration error up to 95\%.
Action Learning for 3D Point Cloud Based Organ Segmentation
Jun 14, 2018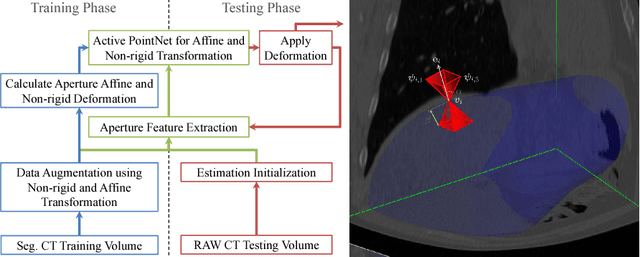

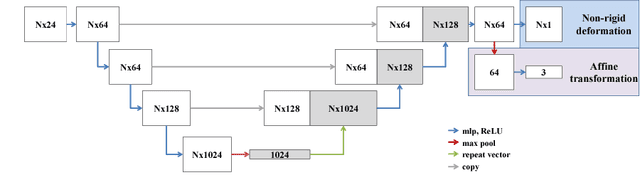
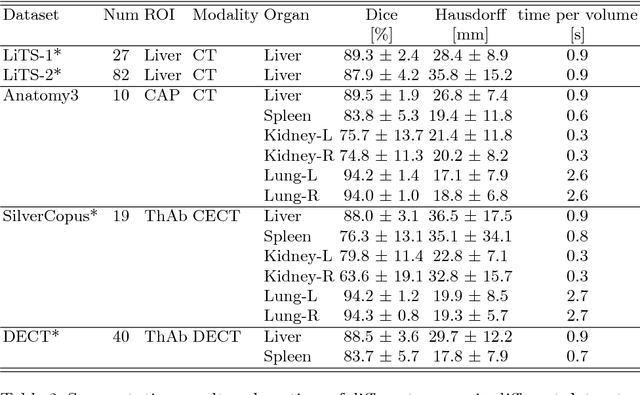
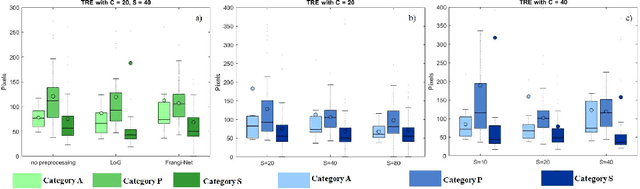
We propose a novel point cloud based 3D organ segmentation pipeline utilizing deep Q-learning. In order to preserve shape properties, the learning process is guided using a statistical shape model. The trained agent directly predicts piece-wise linear transformations for all vertices in each iteration. This mapping between the ideal transformation for an object outline estimation is learned based on image features. To this end, we introduce aperture features that extract gray values by sampling the 3D volume within the cone centered around the associated vertex and its normal vector. Our approach is also capable of estimating a hierarchical pyramid of non rigid deformations for multi-resolution meshes. In the application phase, we use a marginal approach to gradually estimate affine as well as non-rigid transformations. We performed extensive evaluations to highlight the robust performance of our approach on a variety of challenge data as well as clinical data. Additionally, our method has a run time ranging from 0.3 to 2.7 seconds to segment each organ. In addition, we show that the proposed method can be applied to different organs, X-ray based modalities, and scanning protocols without the need of transfer learning. As we learn actions, even unseen reference meshes can be processed as demonstrated in an example with the Visible Human. From this we conclude that our method is robust, and we believe that our method can be successfully applied to many more applications, in particular, in the interventional imaging space.