 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and Efficient Multi-Channel Time Series Forecasting via Sparse Attention Mechanism
Mar 19, 2026The task of multi-channel time series forecasting is ubiquitous in numerous fields such as finance, supply chain management, and energy planning. It is critical to effectively capture complex dynamic dependencies within and between channels for accurate predictions. However, traditional method paid few attentions on learning the interaction among channels. This paper proposes Linear-Network (Li-Net), a novel architecture designed for multi-channel time series forecasting that captures the linear and non-linear dependencies among channels. Li-Net dynamically compresses representations across sequence and channel dimensions, processes the information through a configurable non-linear module and subsequently reconstructs the forecasts. Moreover, Li-Net integrates a sparse Top-K Softmax attention mechanism within a multi-scale projection framework to address these challenges. A core innovation is its ability to seamlessly incorporate and fuse multi-modal embeddings, guiding the sparse attention process to focus on the most informative time steps and feature channels. Through the experiment results on multiple real-world benchmark datasets demonstrate that Li-Net achieves competitive performance compared to state-of-the-art baseline methods. Furthermore, Li-Net provides a superior balance between prediction accuracy and computational burden, exhibiting significantly lower memory usage and faster inference times. Detailed ablation studies and parameter sensitivity analyses validate the effectiveness of each key component in our proposed architecture. Keywords: Multivariate Time Series Forecasting, Sparse Attention Mechanism, Multimodal Information Fusion, Non-linear relationship
Dynamic Dispersion Accumulation in Fiber Loops for Realizing Record-High Frequency Resolution or Ultra-Low Signal Sampling Rate in Dispersion-Based Photonics-Assisted Wideband Microwave Measurement Systems
Feb 12, 2026Dispersion-based photonics-assisted microwave measurement systems provide immense potential for real-time analysis of wideband and dynamic signals. However, they face two critical challenges: a difficulty in achieving high frequency resolution over a wideband analysis bandwidth, and a reliance on large-bandwidth-and-high-sampling-rate oscilloscopes to capture the resulting ultra-narrow pulses. We introduce a dynamic dispersion accumulation technique to overcome these limitations. By circulating the optical signal in fiber loops containing a dispersion-compensating fiber, we achieve a high accumulated dispersion of -215700 ps/nm. This high dispersion relaxes the required chirp rate of the chirped optical signal, enabling two distinct advantages: When the analysis bandwidth is fixed, a lower chirp rate enables a longer temporal period, yielding a record-high frequency resolution of 27.9 MHz; When the temporal period is fixed, a lower chirp rate enables a smaller bandwidth, generating a wider pulse and thus relaxing pulse sampling requirements at the expense of analysis bandwidth. This sacrifice in analysis bandwidth can be compensated by a duty-cycle-enabling technique, which holds the potential to extend the analysis bandwidth beyond 100 GHz. This work breaks the performance and hardware limitations in dispersion-based systems, paving the way for high frequency resolution, wideband microwave measurement systems that are both real-time and cost-effective.
Striking the Right Balance between Compute and Copy: Improving LLM Inferencing Under Speculative Decoding
Nov 15, 2025With the skyrocketing costs of GPUs and their virtual instances in the cloud, there is a significant desire to use CPUs for large language model (LLM) inference. KV cache update, often implemented as allocation, copying, and in-place strided update for each generated token, incurs significant overhead. As the sequence length increases, the allocation and copy overheads dominate the performance. Alternate approaches may allocate large KV tensors upfront to enable in-place updates, but these matrices (with zero-padded rows) cause redundant computations. In this work, we propose a new KV cache allocation mechanism called Balancing Memory and Compute (BMC). BMC allocates, once every r iterations, KV tensors with r redundant rows, allowing in-place update without copy overhead for those iterations, but at the expense of a small amount of redundant computation. Second, we make an interesting observation that the extra rows allocated in the KV tensors and the resulting redundant computation can be repurposed for Speculative Decoding (SD) that improves token generation efficiency. Last, BMC represents a spectrum of design points with different values of r. To identify the best-performing design point(s), we derive a simple analytical model for BMC. The proposed BMC method achieves an average throughput acceleration of up to 3.2x over baseline HuggingFace (without SD). Importantly when we apply BMC with SD, it results in an additional speedup of up to 1.39x, over and above the speedup offered by SD. Further, BMC achieves a throughput acceleration of up to 1.36x and 2.29x over state-of-the-art inference servers vLLM and DeepSpeed, respectively. Although the BMC technique is evaluated extensively across different classes of CPUs (desktop and server class), we also evaluate the scheme with GPUs and demonstrate that it works well for GPUs.
DuetServe: Harmonizing Prefill and Decode for LLM Serving via Adaptive GPU Multiplexing
Nov 06, 2025Modern LLM serving systems must sustain high throughput while meeting strict latency SLOs across two distinct inference phases: compute-intensive prefill and memory-bound decode phases. Existing approaches either (1) aggregate both phases on shared GPUs, leading to interference between prefill and decode phases, which degrades time-between-tokens (TBT); or (2) disaggregate the two phases across GPUs, improving latency but wasting resources through duplicated models and KV cache transfers. We present DuetServe, a unified LLM serving framework that achieves disaggregation-level isolation within a single GPU. DuetServe operates in aggregated mode by default and dynamically activates SM-level GPU spatial multiplexing when TBT degradation is predicted. Its key idea is to decouple prefill and decode execution only when needed through fine-grained, adaptive SM partitioning that provides phase isolation only when contention threatens latency service level objectives (SLOs). DuetServe integrates (1) an attention-aware roofline model to forecast iteration latency, (2) a partitioning optimizer that selects the optimal SM split to maximize throughput under TBT constraints, and (3) an interruption-free execution engine that eliminates CPU-GPU synchronization overhead. Evaluations show that DuetServe improves total throughput by up to 1.3x while maintaining low generation latency compared to state-of-the-art frameworks.
ViFP: A Framework for Visual False Positive Detection to Enhance Reasoning Reliability in VLMs
Aug 06, 2025In visual-language model (VLM) reasoning, false positive(FP) reasoning occurs when a model generates a correct answer but follows an incorrect reasoning path. Existing methods based on specific multi-step reasoning datasets and reinforcement learning strategies, leading to high training costs and limited generalization. In this work, we propose ViFP, a general framework for enhancing visual reasoning reliability. It improves both answer accuracy and reasoning soundness by detecting FPs. ViFP tackles the limitations of dataset dependency and poor generalization by constructing sub-question templates grounded in the core dimensions of visual reasoning, such as object localization, characteristic description, and object discovery. ViFP then builds effective reasoning paths via multi-turn QA to improve reasoning accuracy. Meanwhile, ViFP dynamically analyzes the consistency of reasoning path to identify potential FPs, and introduces a targeted chain-of-thought (CoT) mechanism that adaptively guides both FP and non-FP samples. Thereby reducing logical errors in the reasoning path while preserving accuracy. Finally, we introduce a reliability evaluation metric-VoC, which integrates answer accuracy and the FP rate, providing a quantitative tool to assess whether a VLM not only answers correctly, but also reasons reliably. Our experiments on closed-source VLMs show that ViFP consistently improves performance across three datasets: A-OKVQA, OKVQA, and FVQA. On A-OKVQA, ViFP improves accuracy by up to 5.4%, surpassing the previous state-of-the-art by 4.3%, and significantly reduces the number of FPs, validating its benefits in enhancing reasoning reliability.
HAMLET-FFD: Hierarchical Adaptive Multi-modal Learning Embeddings Transformation for Face Forgery Detection
Jul 28, 2025The rapid evolution of face manipulation techniques poses a critical challenge for face forgery detection: cross-domain generalization. Conventional methods, which rely on simple classification objectives, often fail to learn domain-invariant representations. We propose HAMLET-FFD, a cognitively inspired Hierarchical Adaptive Multi-modal Learning framework that tackles this challenge via bidirectional cross-modal reasoning. Building on contrastive vision-language models such as CLIP, HAMLET-FFD introduces a knowledge refinement loop that iteratively assesses authenticity by integrating visual evidence with conceptual cues, emulating expert forensic analysis. A key innovation is a bidirectional fusion mechanism in which textual authenticity embeddings guide the aggregation of hierarchical visual features, while modulated visual features refine text embeddings to generate image-adaptive prompts. This closed-loop process progressively aligns visual observations with semantic priors to enhance authenticity assessment. By design, HAMLET-FFD freezes all pretrained parameters, serving as an external plugin that preserves CLIP's original capabilities. Extensive experiments demonstrate its superior generalization to unseen manipulations across multiple benchmarks, and visual analyses reveal a division of labor among embeddings, with distinct representations specializing in fine-grained artifact recognition.
AcoustoBots: A swarm of robots for acoustophoretic multimodal interactions
May 12, 2025Acoustophoresis has enabled novel interaction capabilities, such as levitation, volumetric displays, mid-air haptic feedback, and directional sound generation, to open new forms of multimodal interactions. However, its traditional implementation as a singular static unit limits its dynamic range and application versatility. This paper introduces AcoustoBots - a novel convergence of acoustophoresis with a movable and reconfigurable phased array of transducers for enhanced application versatility. We mount a phased array of transducers on a swarm of robots to harness the benefits of multiple mobile acoustophoretic units. This offers a more flexible and interactive platform that enables a swarm of acoustophoretic multimodal interactions. Our novel AcoustoBots design includes a hinge actuation system that controls the orientation of the mounted phased array of transducers to achieve high flexibility in a swarm of acoustophoretic multimodal interactions. In addition, we designed a BeadDispenserBot that can deliver particles to trapping locations, which automates the acoustic levitation interaction. These attributes allow AcoustoBots to independently work for a common cause and interchange between modalities, allowing for novel augmentations (e.g., a swarm of haptics, audio, and levitation) and bilateral interactions with users in an expanded interaction area. We detail our design considerations, challenges, and methodological approach to extend acoustophoretic central control in distributed settings. This work demonstrates a scalable acoustic control framework with two mobile robots, laying the groundwork for future deployment in larger robotic swarms. Finally, we characterize the performance of our AcoustoBots and explore the potential interactive scenarios they can enable.
DEL: Context-Aware Dynamic Exit Layer for Efficient Self-Speculative Decoding
Apr 08, 2025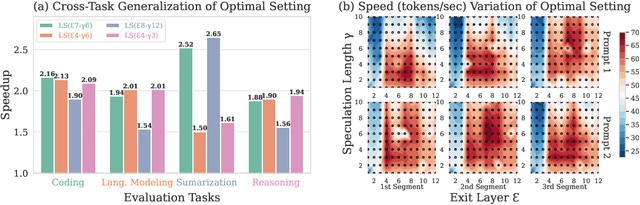
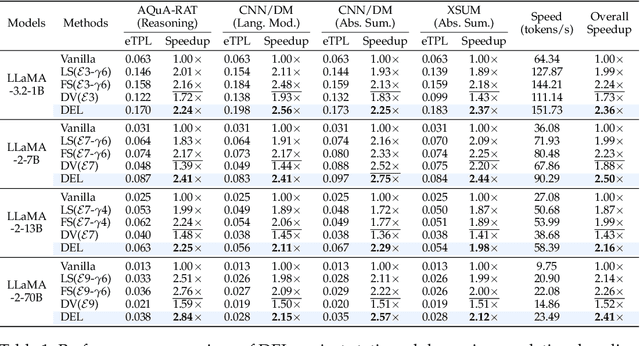
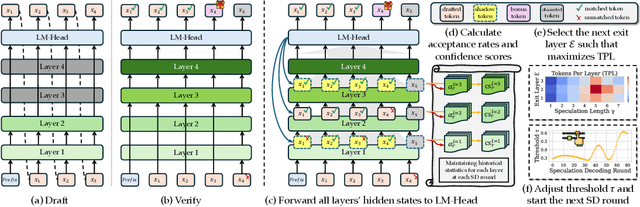

Speculative Decoding (SD) is a widely used approach to accelerate the inference of large language models (LLMs) without reducing generation quality. It operates by first using a compact model to draft multiple tokens efficiently, followed by parallel verification using the target LLM. This approach leads to faster inference compared to auto-regressive decoding. While there are multiple approaches to create a draft model, one promising approach is to use early-exit methods. These methods draft candidate tokens by using a subset of layers of the primary model and applying the remaining layers for verification, allowing a single model to handle both drafting and verification. While this technique reduces memory usage and computational cost, its performance relies on the choice of the exit layer for drafting and the number of tokens drafted (speculation length) in each SD round. Prior works use hyperparameter exploration to statically select these values. However, our evaluations show that these hyperparameter values are task-specific, and even within a task they are dependent on the current sequence context. We introduce DEL, a plug-and-play method that adaptively selects the exit layer and speculation length during inference. DEL dynamically tracks the token acceptance rate if the tokens are drafted at each layer of an LLM and uses that knowledge to heuristically select the optimal exit layer and speculation length. Our experiments across a broad range of models and downstream tasks show that DEL achieves overall speedups of $2.16\times$$\sim$$2.50\times$ over vanilla auto-regressive decoding and improves upon the state-of-the-art SD methods by up to $0.27\times$.
Efficient LLM Inference with I/O-Aware Partial KV Cache Recomputation
Nov 26, 2024Inference for Large Language Models (LLMs) is computationally demanding. To reduce the cost of auto-regressive decoding, Key-Value (KV) caching is used to store intermediate activations, enabling GPUs to perform only the incremental computation required for each new token. This approach significantly lowers the computational overhead for token generation. However, the memory required for KV caching grows rapidly, often exceeding the capacity of GPU memory. A cost-effective alternative is to offload KV cache to CPU memory, which alleviates GPU memory pressure but shifts the bottleneck to the limited bandwidth of the PCIe connection between the CPU and GPU. Existing methods attempt to address these issues by overlapping GPU computation with I/O or employing CPU-GPU heterogeneous execution, but they are hindered by excessive data movement and dependence on CPU capabilities. In this paper, we introduce an efficient CPU-GPU I/O-aware LLM inference method that avoids transferring the entire KV cache from CPU to GPU by recomputing partial KV cache from activations while concurrently transferring the remaining KV cache via PCIe bus. This approach overlaps GPU recomputation with data transfer to minimize idle GPU time and maximize inference performance. Our method is fully automated by integrating a profiler module that utilizes input characteristics and system hardware information, a scheduler module to optimize the distribution of computation and communication workloads, and a runtime module to efficiently execute the derived execution plan. Experimental results show that our method achieves up to 35.8% lower latency and 46.2% higher throughput during decoding compared to state-of-the-art approaches.
Dynamic Multi-Objective Lion Swarm Optimization with Multi-strategy Fusion: An application in 6R robot trajectory
May 31, 2024The advancement of industrialization has fostered innovative swarm intelligence algorithms, with Lion Swarm Optimization (LSO) being notable for its robustness and efficiency. However, multi-objective variants of LSO struggle with poor initialization, local optima entrapment, and slow adaptation to dynamic environments. This study proposes a Dynamic Multi-Objective Lion Swarm Optimization with Multi-strategy Fusion (MF-DMOLSO) to overcome these challenges. MF-DMOLSO includes an initialization unit using chaotic mapping, a position update unit enhancing behavior patterns based on non-domination and diversity, and an external archive update unit. Evaluations on benchmark functions showed MF-DMOLSO outperformed existing algorithms achieving an accuracy that exceeds the comparison algorithm by 90%. Applied to 6R robot trajectory planning, MF-DMOLSO optimized running time and maximum acceleration to 8.3s and 0.3pi rad/s^2, respectively, achieving a set coverage rate of 70.97% compared to 2% by multi-objective particle swarm optimization, thus improving efficiency and reducing mechanical dither.