 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability of Machine Learning: Recent Advances and Future Prospects
Apr 30, 2023
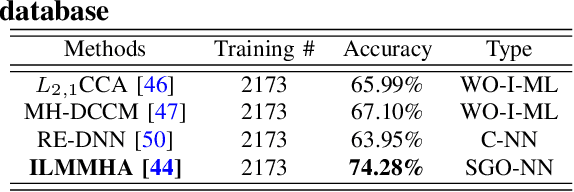
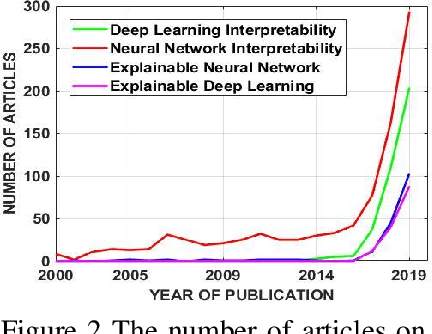
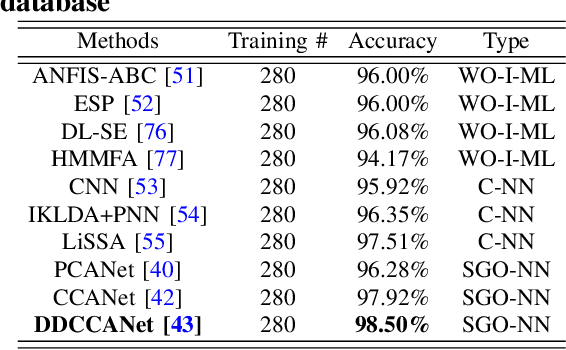
The proliferation of machine learning (ML) has drawn unprecedented interest in the study of various multimedia contents such as text, image, audio and video, among others. Consequently, understanding and learning ML-based representations have taken center stage in knowledge discovery in intelligent multimedia research and applications. Nevertheless, the black-box nature of contemporary ML, especially in deep neural networks (DNNs), has posed a primary challenge for ML-based representation learning. To address this black-box problem, the studies on interpretability of ML have attracted tremendous interests in recent years. This paper presents a survey on recent advances and future prospects on interpretability of ML, with several application examples pertinent to multimedia computing, including text-image cross-modal representation learning, face recognition, and the recognition of objects. It is evidently shown that the study of interpretability of ML promises an important research direction, one which is worth further investment in.
A GPU-accelerated Algorithm for Distinct Discriminant Canonical Correlation Network
Sep 26, 2022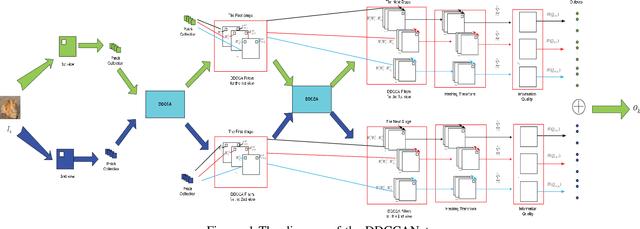



Currently, deep neural networks (DNNs)-based models have drawn enormous attention and have been utilized to different domains widely. However, due to the data-driven nature, the DNN models may generate unsatisfying performance on the small scale data sets. To address this problem, a distinct discriminant canonical correlation network (DDCCANet) is proposed to generate the deep-level feature representation, producing improved performance on image classification. However, the DDCCANet model was originally implemented on a CPU with computing time on par with state-of-the-art DNN models running on GPUs. In this paper, a GPU-based accelerated algorithm is proposed to further optimize the DDCCANet algorithm. As a result, not only is the performance of DDCCANet guaranteed, but also greatly shortens the calculation time, making the model more applicable in real tasks. To demonstrate the effectiveness of the proposed accelerated algorithm, we conduct experiments on three database with different scales. Experimental results validate the superiority of the proposed accelerated algorithm on given examples.
ODMTCNet: An Interpretable Multi-view Deep Neural Network Architecture for Image Feature Representation
Oct 28, 2021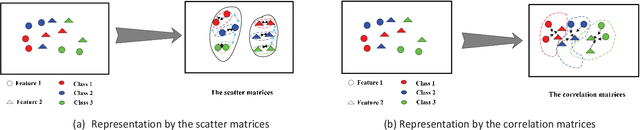
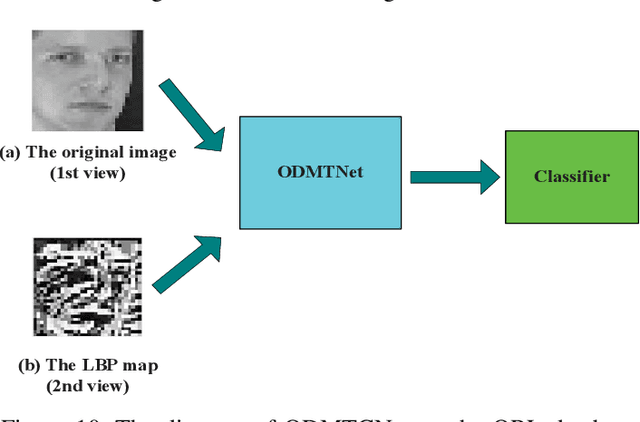

This work proposes an interpretable multi-view deep neural network architecture, namely optimal discriminant multi-view tensor convolutional network (ODMTCNet), by integrating statistical machine learning (SML) principles with the deep neural network (DNN) architecture.
ECG Heartbeat Classification Using Multimodal Fusion
Jul 21, 2021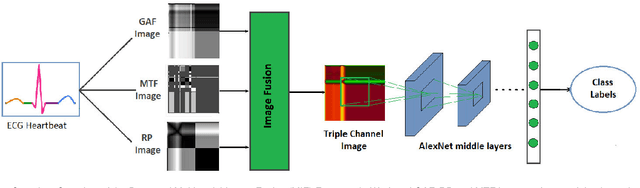
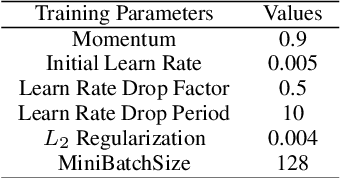
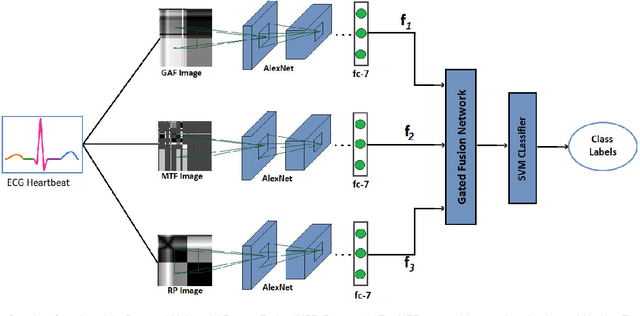
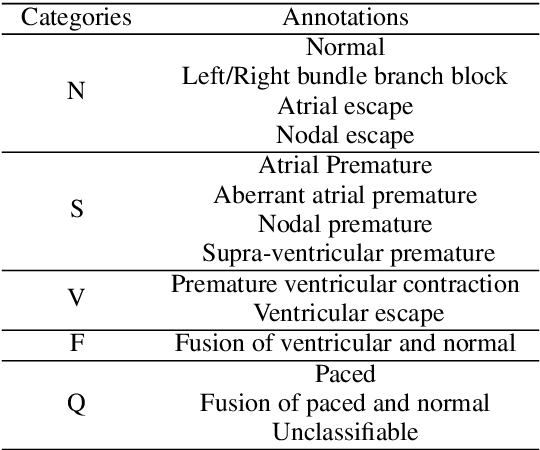
Electrocardiogram (ECG) is an authoritative source to diagnose and counter critical cardiovascular syndromes such as arrhythmia and myocardial infarction (MI). Current machine learning techniques either depend on manually extracted features or large and complex deep learning networks which merely utilize the 1D ECG signal directly. Since intelligent multimodal fusion can perform at the stateof-the-art level with an efficient deep network, therefore, in this paper, we propose two computationally efficient multimodal fusion frameworks for ECG heart beat classification called Multimodal Image Fusion (MIF) and Multimodal Feature Fusion (MFF). At the input of these frameworks, we convert the raw ECG data into three different images using Gramian Angular Field (GAF), Recurrence Plot (RP) and Markov Transition Field (MTF). In MIF, we first perform image fusion by combining three imaging modalities to create a single image modality which serves as input to the Convolutional Neural Network (CNN). In MFF, we extracted features from penultimate layer of CNNs and fused them to get unique and interdependent information necessary for better performance of classifier. These informational features are finally used to train a Support Vector Machine (SVM) classifier for ECG heart-beat classification. We demonstrate the superiority of the proposed fusion models by performing experiments on PhysioNets MIT-BIH dataset for five distinct conditions of arrhythmias which are consistent with the AAMI EC57 protocols and on PTB diagnostics dataset for Myocardial Infarction (MI) classification. We achieved classification accuracy of 99.7% and 99.2% on arrhythmia and MI classification, respectively.
ECG Heart-beat Classification Using Multimodal Image Fusion
May 28, 2021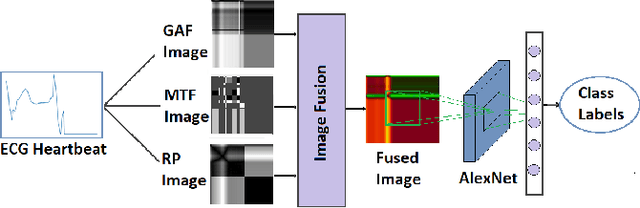
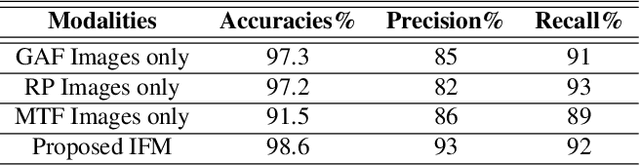

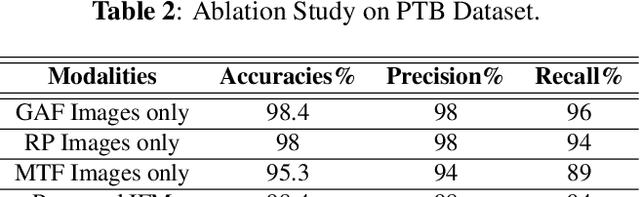
In this paper, we present a novel Image Fusion Model (IFM) for ECG heart-beat classification to overcome the weaknesses of existing machine learning techniques that rely either on manual feature extraction or direct utilization of 1D raw ECG signal. At the input of IFM, we first convert the heart beats of ECG into three different images using Gramian Angular Field (GAF), Recurrence Plot (RP) and Markov Transition Field (MTF) and then fuse these images to create a single imaging modality. We use AlexNet for feature extraction and classification and thus employ end to end deep learning. We perform experiments on PhysioNet MIT-BIH dataset for five different arrhythmias in accordance with the AAMI EC57 standard and on PTB diagnostics dataset for myocardial infarction (MI) classification. We achieved an state of an art results in terms of prediction accuracy, precision and recall.
A Discriminative Vectorial Framework for Multi-modal Feature Representation
Mar 09, 2021

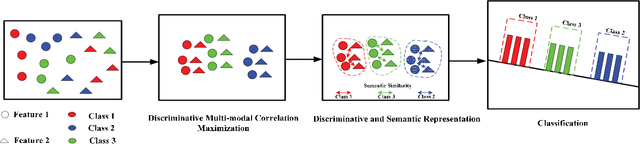
Due to the rapid advancements of sensory and computing technology, multi-modal data sources that represent the same pattern or phenomenon have attracted growing attention. As a result, finding means to explore useful information from these multi-modal data sources has quickly become a necessity. In this paper, a discriminative vectorial framework is proposed for multi-modal feature representation in knowledge discovery by employing multi-modal hashing (MH) and discriminative correlation maximization (DCM) analysis. Specifically, the proposed framework is capable of minimizing the semantic similarity among different modalities by MH and exacting intrinsic discriminative representations across multiple data sources by DCM analysis jointly, enabling a novel vectorial framework of multi-modal feature representation. Moreover, the proposed feature representation strategy is analyzed and further optimized based on canonical and non-canonical cases, respectively. Consequently, the generated feature representation leads to effective utilization of the input data sources of high quality, producing improved, sometimes quite impressive, results in various applications. The effectiveness and generality of the proposed framework are demonstrated by utilizing classical features and deep neural network (DNN) based features with applications to image and multimedia analysis and recognition tasks, including data visualization, face recognition, object recognition; cross-modal (text-image) recognition and audio emotion recognition. Experimental results show that the proposed solutions are superior to state-of-the-art statistical machine learning (SML) and DNN algorithms.
* Accepted
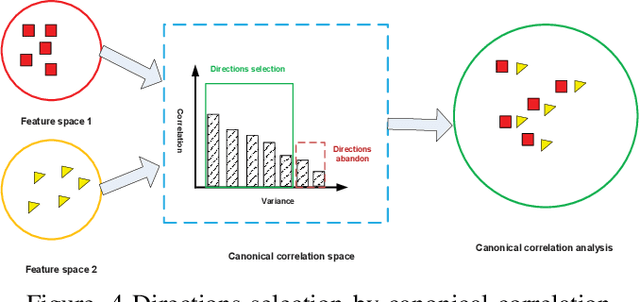
A Complete Discriminative Tensor Representation Learning for Two-Dimensional Correlation Analysis
Feb 28, 2021


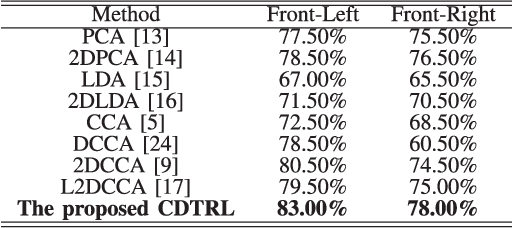
As an effective tool for two-dimensional data analysis, two-dimensional canonical correlation analysis (2DCCA) is not only capable of preserving the intrinsic structural information of original two-dimensional (2D) data, but also reduces the computational complexity effectively. However, due to the unsupervised nature, 2DCCA is incapable of extracting sufficient discriminatory representations, resulting in an unsatisfying performance. In this letter, we propose a complete discriminative tensor representation learning (CDTRL) method based on linear correlation analysis for analyzing 2D signals (e.g. images). This letter shows that the introduction of the complete discriminatory tensor representation strategy provides an effective vehicle for revealing, and extracting the discriminant representations across the 2D data sets, leading to improved results. Experimental results show that the proposed CDTRL outperforms state-of-the-art methods on the evaluated data sets.
The Property of Frequency Shift in 2D-FRFT Domain with Application to Image Encryption
Feb 28, 2021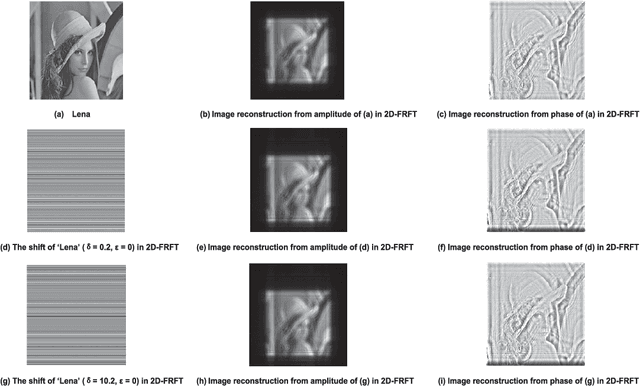

The Fractional Fourier Transform (FRFT) has been playing a unique and increasingly important role in signal and image processing. In this letter, we investigate the property of frequency shift in two-dimensional FRFT (2D-FRFT) domain. It is shown that the magnitude of image reconstruction from phase information is frequency shift-invariant in 2D-FRFT domain, enhancing the robustness of image encryption, an important multimedia security task. Experiments are conducted to demonstrate the effectiveness of this property against the frequency shift attack, improving the robustness of image encryption.
Discriminative Multiple Canonical Correlation Analysis for Information Fusion
Feb 28, 2021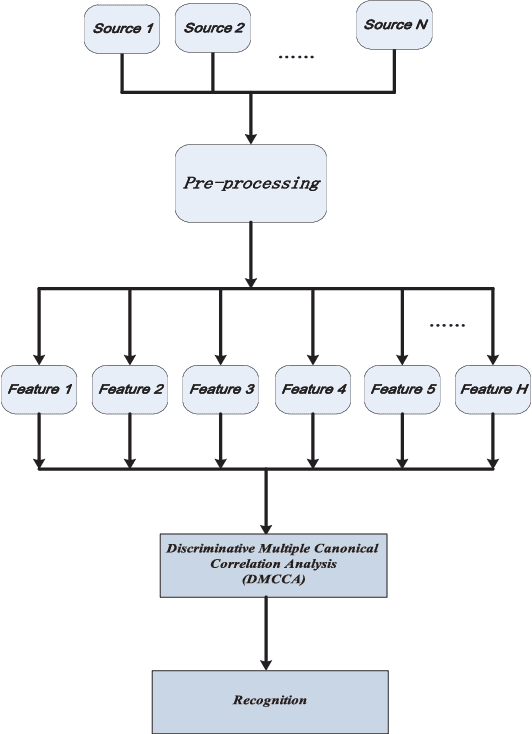
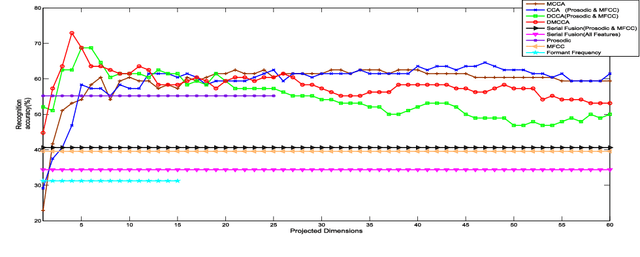
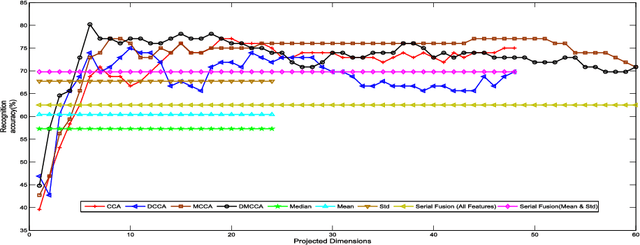
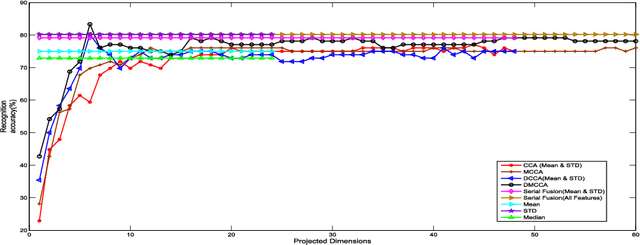
In this paper, we propose the Discriminative Multiple Canonical Correlation Analysis (DMCCA) for multimodal information analysis and fusion. DMCCA is capable of extracting more discriminative characteristics from multimodal information representations. Specifically, it finds the projected directions which simultaneously maximize the within-class correlation and minimize the between-class correlation, leading to better utilization of the multimodal information. In the process, we analytically demonstrate that the optimally projected dimension by DMCCA can be quite accurately predicted, leading to both superior performance and substantial reduction in computational cost. We further verify that Canonical Correlation Analysis (CCA), Multiple Canonical Correlation Analysis (MCCA) and Discriminative Canonical Correlation Analysis (DCCA) are special cases of DMCCA, thus establishing a unified framework for Canonical Correlation Analysis. We implement a prototype of DMCCA to demonstrate its performance in handwritten digit recognition and human emotion recognition. Extensive experiments show that DMCCA outperforms the traditional methods of serial fusion, CCA, MCCA and DCCA.
The Labeled Multiple Canonical Correlation Analysis for Information Fusion
Feb 28, 2021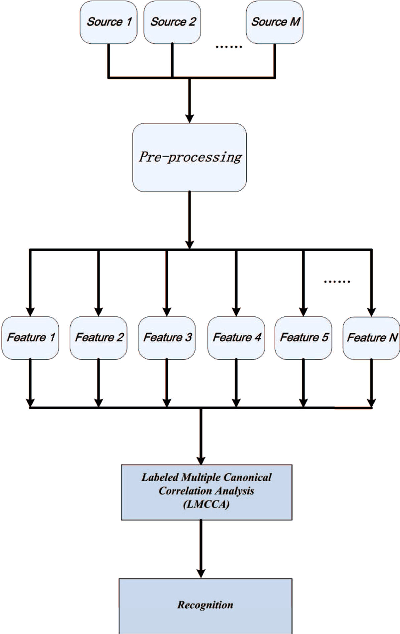
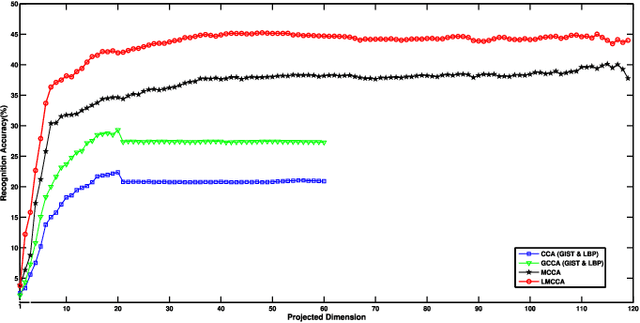

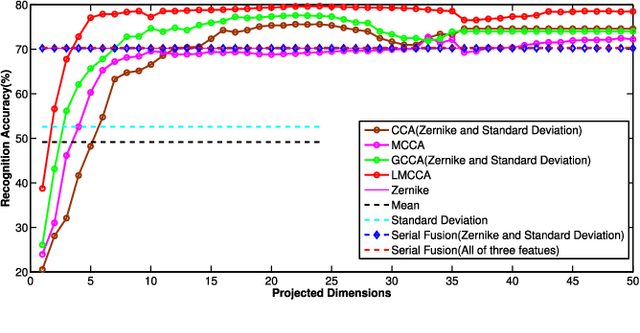
The objective of multimodal information fusion is to mathematically analyze information carried in different sources and create a new representation which will be more effectively utilized in pattern recognition and other multimedia information processing tasks. In this paper, we introduce a new method for multimodal information fusion and representation based on the Labeled Multiple Canonical Correlation Analysis (LMCCA). By incorporating class label information of the training samples,the proposed LMCCA ensures that the fused features carry discriminative characteristics of the multimodal information representations, and are capable of providing superior recognition performance. We implement a prototype of LMCCA to demonstrate its effectiveness on handwritten digit recognition,face recognition and object recognition utilizing multiple features,bimodal human emotion recognition involving information from both audio and visual domains. The generic nature of LMCCA allows it to take as input features extracted by any means,including those by deep learning (DL) methods. Experimental results show that the proposed method enhanced the performance of both statistical machine learning (SML) methods, and methods based on DL.