 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPN-GAN: Inducing Periodic Activations in Generative Adversarial Networks for High-Fidelity Audio Synthesis
May 14, 2025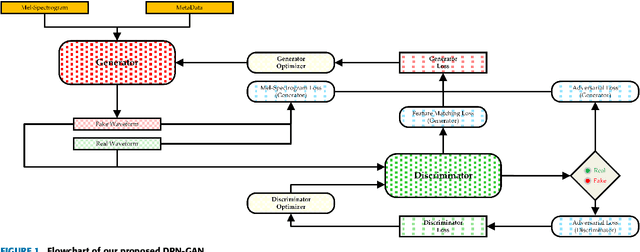

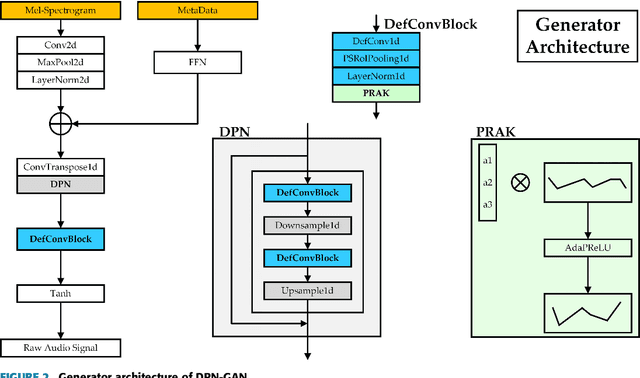

In recent years, generative adversarial networks (GANs) have made significant progress in generating audio sequences. However, these models typically rely on bandwidth-limited mel-spectrograms, which constrain the resolution of generated audio sequences, and lead to mode collapse during conditional generation. To address this issue, we propose Deformable Periodic Network based GAN (DPN-GAN), a novel GAN architecture that incorporates a kernel-based periodic ReLU activation function to induce periodic bias in audio generation. This innovative approach enhances the model's ability to capture and reproduce intricate audio patterns. In particular, our proposed model features a DPN module for multi-resolution generation utilizing deformable convolution operations, allowing for adaptive receptive fields that improve the quality and fidelity of the synthetic audio. Additionally, we enhance the discriminator network using deformable convolution to better distinguish between real and generated samples, further refining the audio quality. We trained two versions of the model: DPN-GAN small (38.67M parameters) and DPN-GAN large (124M parameters). For evaluation, we use five different datasets, covering both speech synthesis and music generation tasks, to demonstrate the efficiency of the DPN-GAN. The experimental results demonstrate that DPN-GAN delivers superior performance on both out-of-distribution and noisy data, showcasing its robustness and adaptability. Trained across various datasets, DPN-GAN outperforms state-of-the-art GAN architectures on standard evaluation metrics, and exhibits increased robustness in synthesized audio.
Machine learning approaches for automatic defect detection in photovoltaic systems
Sep 24, 2024Solar photovoltaic (PV) modules are prone to damage during manufacturing, installation and operation which reduces their power conversion efficiency. This diminishes their positive environmental impact over the lifecycle. Continuous monitoring of PV modules during operation via unmanned aerial vehicles is essential to ensure that defective panels are promptly replaced or repaired to maintain high power conversion efficiencies. Computer vision provides an automatic, non-destructive and cost-effective tool for monitoring defects in large-scale PV plants. We review the current landscape of deep learning-based computer vision techniques used for detecting defects in solar modules. We compare and evaluate the existing approaches at different levels, namely the type of images used, data collection and processing method, deep learning architectures employed, and model interpretability. Most approaches use convolutional neural networks together with data augmentation or generative adversarial network-based techniques. We evaluate the deep learning approaches by performing interpretability analysis on classification tasks. This analysis reveals that the model focuses on the darker regions of the image to perform the classification. We find clear gaps in the existing approaches while also laying out the groundwork for mitigating these challenges when building new models. We conclude with the relevant research gaps that need to be addressed and approaches for progress in this field: integrating geometric deep learning with existing approaches for building more robust and reliable models, leveraging physics-based neural networks that combine domain expertise of physical laws to build more domain-aware deep learning models, and incorporating interpretability as a factor for building models that can be trusted. The review points towards a clear roadmap for making this technology commercially relevant.
A Survey on Physiological Signal Based Emotion Recognition
May 20, 2022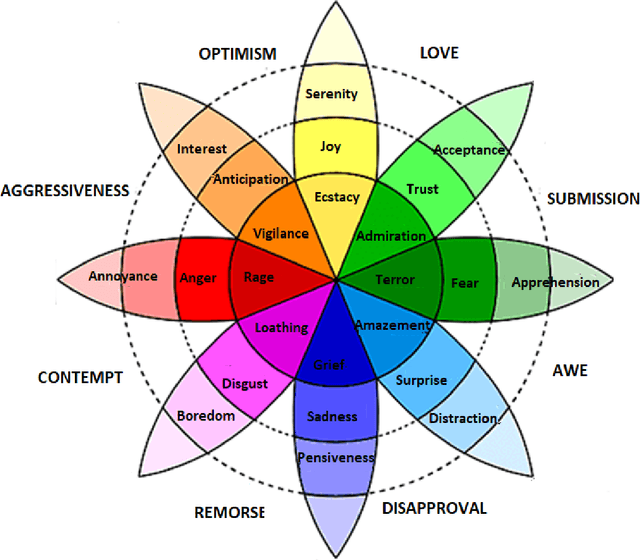
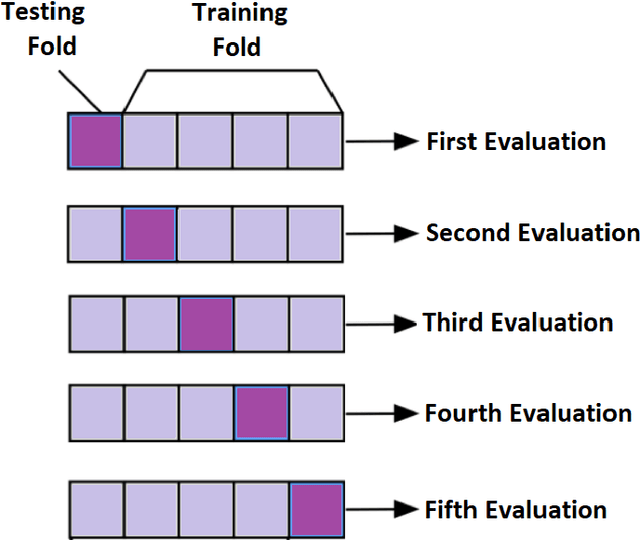
Physiological Signals are the most reliable form of signals for emotion recognition, as they cannot be controlled deliberately by the subject. Existing review papers on emotion recognition based on physiological signals surveyed only the regular steps involved in the workflow of emotion recognition such as preprocessing, feature extraction, and classification. While these are important steps, such steps are required for any signal processing application. Emotion recognition poses its own set of challenges that are very important to address for a robust system. Thus, to bridge the gap in the existing literature, in this paper, we review the effect of inter-subject data variance on emotion recognition, important data annotation techniques for emotion recognition and their comparison, data preprocessing techniques for each physiological signal, data splitting techniques for improving the generalization of emotion recognition models and different multimodal fusion techniques and their comparison. Finally we discuss key challenges and future directions in this field.
ECG Heartbeat Classification Using Multimodal Fusion
Jul 21, 2021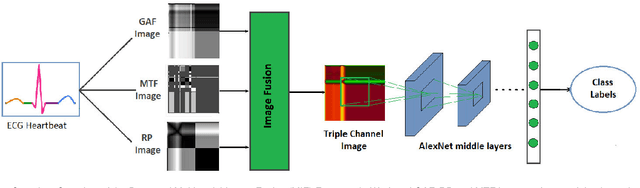
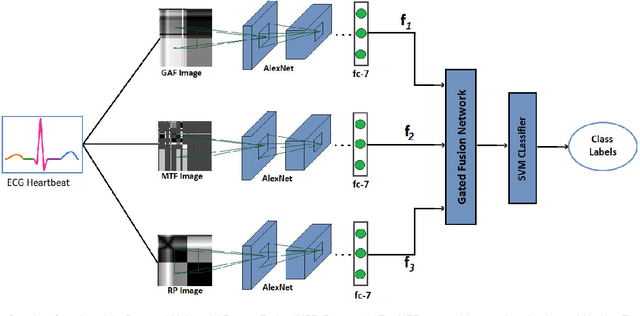
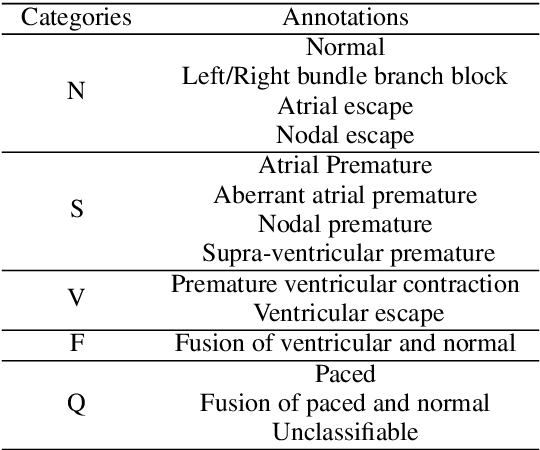
Electrocardiogram (ECG) is an authoritative source to diagnose and counter critical cardiovascular syndromes such as arrhythmia and myocardial infarction (MI). Current machine learning techniques either depend on manually extracted features or large and complex deep learning networks which merely utilize the 1D ECG signal directly. Since intelligent multimodal fusion can perform at the stateof-the-art level with an efficient deep network, therefore, in this paper, we propose two computationally efficient multimodal fusion frameworks for ECG heart beat classification called Multimodal Image Fusion (MIF) and Multimodal Feature Fusion (MFF). At the input of these frameworks, we convert the raw ECG data into three different images using Gramian Angular Field (GAF), Recurrence Plot (RP) and Markov Transition Field (MTF). In MIF, we first perform image fusion by combining three imaging modalities to create a single image modality which serves as input to the Convolutional Neural Network (CNN). In MFF, we extracted features from penultimate layer of CNNs and fused them to get unique and interdependent information necessary for better performance of classifier. These informational features are finally used to train a Support Vector Machine (SVM) classifier for ECG heart-beat classification. We demonstrate the superiority of the proposed fusion models by performing experiments on PhysioNets MIT-BIH dataset for five distinct conditions of arrhythmias which are consistent with the AAMI EC57 protocols and on PTB diagnostics dataset for Myocardial Infarction (MI) classification. We achieved classification accuracy of 99.7% and 99.2% on arrhythmia and MI classification, respectively.
Multi-level Stress Assessment from ECG in a Virtual Reality Environment using Multimodal Fusion
Jul 09, 2021
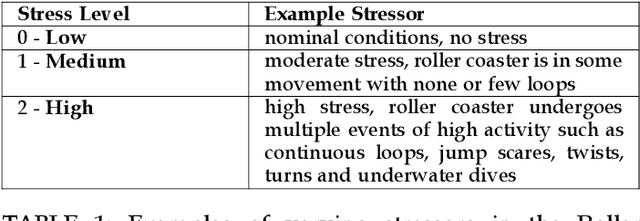

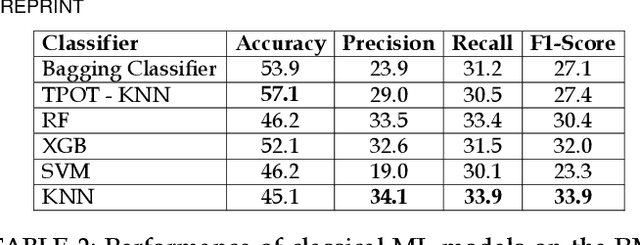
ECG is an attractive option to assess stress in serious Virtual Reality (VR) applications due to its non-invasive nature. However, the existing Machine Learning (ML) models perform poorly. Moreover, existing studies only perform a binary stress assessment, while to develop a more engaging biofeedback-based application, multi-level assessment is necessary. Existing studies annotate and classify a single experience (e.g. watching a VR video) to a single stress level, which again prevents design of dynamic experiences where real-time in-game stress assessment can be utilized. In this paper, we report our findings on a new study on VR stress assessment, where three stress levels are assessed. ECG data was collected from 9 users experiencing a VR roller coaster. The VR experience was then manually labeled in 10-seconds segments to three stress levels by three raters. We then propose a novel multimodal deep fusion model utilizing spectrogram and 1D ECG that can provide a stress prediction from just a 1-second window. Experimental results demonstrate that the proposed model outperforms the classical HRV-based ML models (9% increase in accuracy) and baseline deep learning models (2.5% increase in accuracy). We also report results on the benchmark WESAD dataset to show the supremacy of the model.
ECG Heart-beat Classification Using Multimodal Image Fusion
May 28, 2021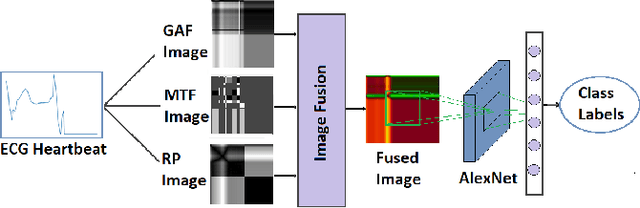
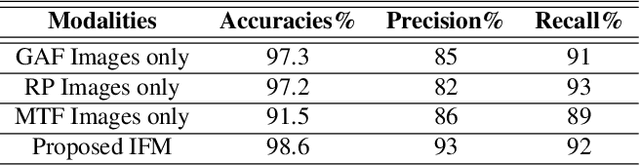

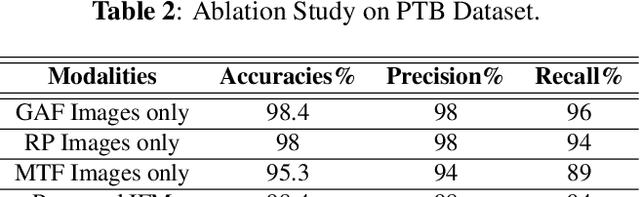
In this paper, we present a novel Image Fusion Model (IFM) for ECG heart-beat classification to overcome the weaknesses of existing machine learning techniques that rely either on manual feature extraction or direct utilization of 1D raw ECG signal. At the input of IFM, we first convert the heart beats of ECG into three different images using Gramian Angular Field (GAF), Recurrence Plot (RP) and Markov Transition Field (MTF) and then fuse these images to create a single imaging modality. We use AlexNet for feature extraction and classification and thus employ end to end deep learning. We perform experiments on PhysioNet MIT-BIH dataset for five different arrhythmias in accordance with the AAMI EC57 standard and on PTB diagnostics dataset for myocardial infarction (MI) classification. We achieved an state of an art results in terms of prediction accuracy, precision and recall.
Inertial Sensor Data To Image Encoding For Human Action Recognition
May 28, 2021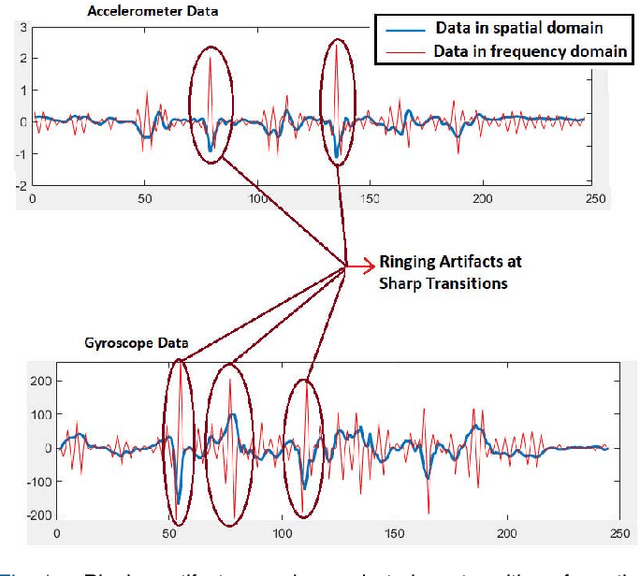
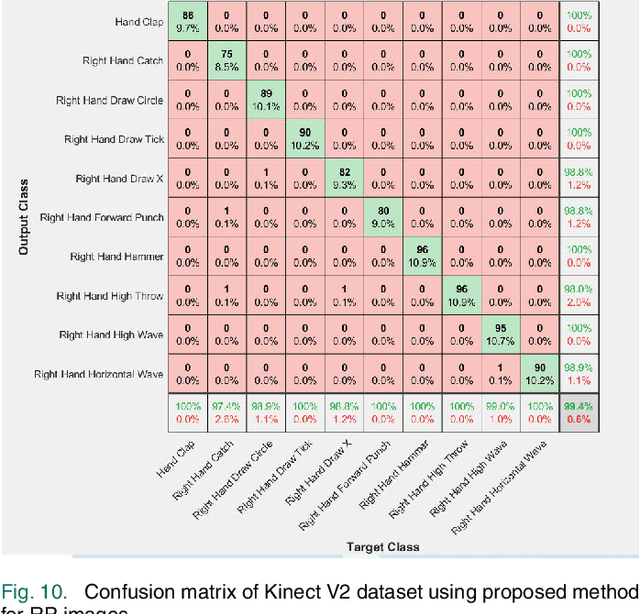
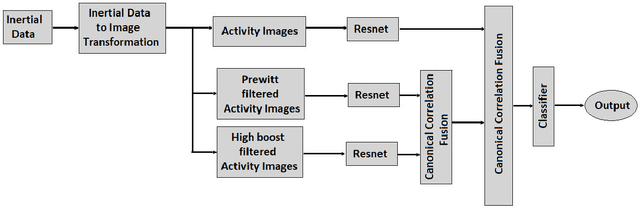

Convolutional Neural Networks (CNNs) are successful deep learning models in the field of computer vision. To get the maximum advantage of CNN model for Human Action Recognition (HAR) using inertial sensor data, in this paper, we use 4 types of spatial domain methods for transforming inertial sensor data to activity images, which are then utilized in a novel fusion framework. These four types of activity images are Signal Images (SI), Gramian Angular Field (GAF) Images, Markov Transition Field (MTF) Images and Recurrence Plot (RP) Images. Furthermore, for creating a multimodal fusion framework and to exploit activity image, we made each type of activity images multimodal by convolving with two spatial domain filters : Prewitt filter and High-boost filter. Resnet-18, a CNN model, is used to learn deep features from multi-modalities. Learned features are extracted from the last pooling layer of each ReNet and then fused by canonical correlation based fusion (CCF) for improving the accuracy of human action recognition. These highly informative features are served as input to a multiclass Support Vector Machine (SVM). Experimental results on three publicly available inertial datasets show the superiority of the proposed method over the current state-of-the-art.
CNN based Multistage Gated Average Fusion for Human Action Recognition Using Depth and Inertial Sensors
Oct 29, 2020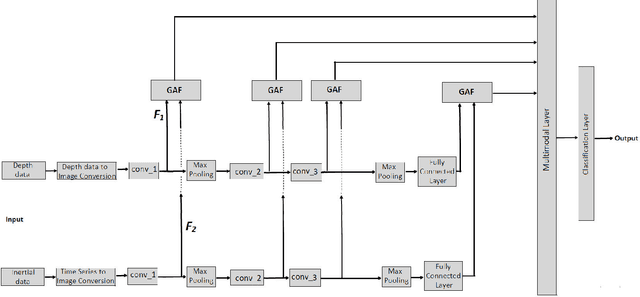
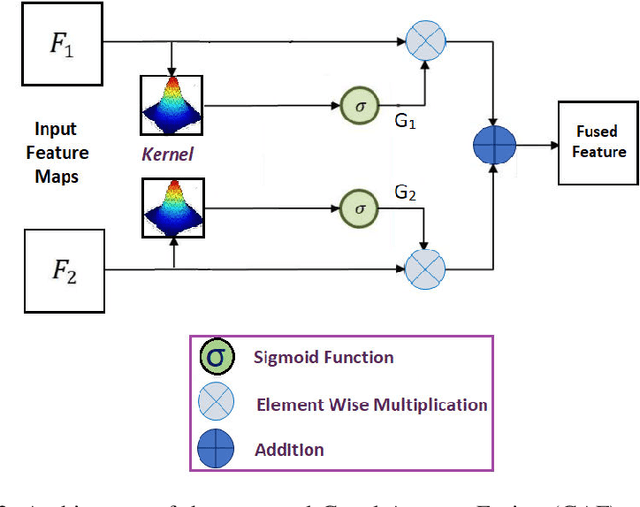
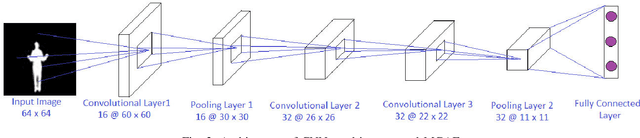

Convolutional Neural Network (CNN) provides leverage to extract and fuse features from all layers of its architecture. However, extracting and fusing intermediate features from different layers of CNN structure is still uninvestigated for Human Action Recognition (HAR) using depth and inertial sensors. To get maximum benefit of accessing all the CNN's layers, in this paper, we propose novel Multistage Gated Average Fusion (MGAF) network which extracts and fuses features from all layers of CNN using our novel and computationally efficient Gated Average Fusion (GAF) network, a decisive integral element of MGAF. At the input of the proposed MGAF, we transform the depth and inertial sensor data into depth images called sequential front view images (SFI) and signal images (SI) respectively. These SFI are formed from the front view information generated by depth data. CNN is employed to extract feature maps from both input modalities. GAF network fuses the extracted features effectively while preserving the dimensionality of fused feature as well. The proposed MGAF network has structural extensibility and can be unfolded to more than two modalities. Experiments on three publicly available multimodal HAR datasets demonstrate that the proposed MGAF outperforms the previous state of the art fusion methods for depth-inertial HAR in terms of recognition accuracy while being computationally much more efficient. We increase the accuracy by an average of 1.5 percent while reducing the computational cost by approximately 50 percent over the previous state of the art.
Multidomain Multimodal Fusion For Human Action Recognition Using Inertial Sensors
Aug 22, 2020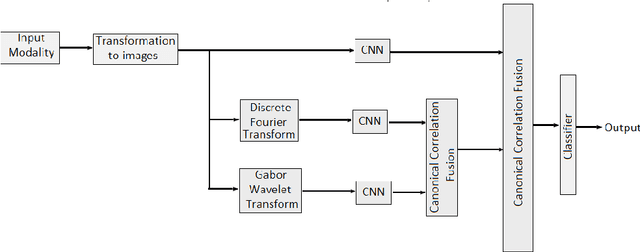


One of the major reasons for misclassification of multiplex actions during action recognition is the unavailability of complementary features that provide the semantic information about the actions. In different domains these features are present with different scales and intensities. In existing literature, features are extracted independently in different domains, but the benefits from fusing these multidomain features are not realized. To address this challenge and to extract complete set of complementary information, in this paper, we propose a novel multidomain multimodal fusion framework that extracts complementary and distinct features from different domains of the input modality. We transform input inertial data into signal images, and then make the input modality multidomain and multimodal by transforming spatial domain information into frequency and time-spectrum domain using Discrete Fourier Transform (DFT) and Gabor wavelet transform (GWT) respectively. Features in different domains are extracted by Convolutional Neural networks (CNNs) and then fused by Canonical Correlation based Fusion (CCF) for improving the accuracy of human action recognition. Experimental results on three inertial datasets show the superiority of the proposed method when compared to the state-of-the-art.
Towards Improved Human Action Recognition Using Convolutional Neural Networks and Multimodal Fusion of Depth and Inertial Sensor Data
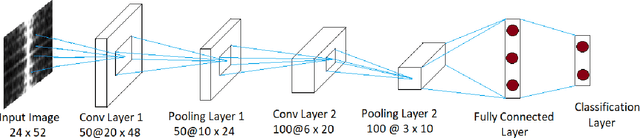
Aug 22, 2020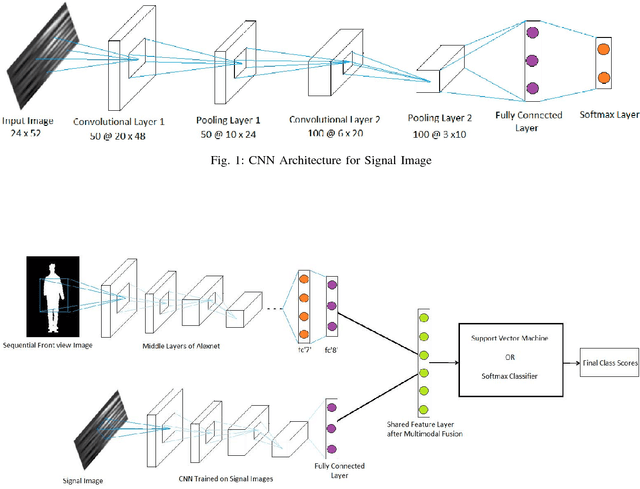


This paper attempts at improving the accuracy of Human Action Recognition (HAR) by fusion of depth and inertial sensor data. Firstly, we transform the depth data into Sequential Front view Images(SFI) and fine-tune the pre-trained AlexNet on these images. Then, inertial data is converted into Signal Images (SI) and another convolutional neural network (CNN) is trained on these images. Finally, learned features are extracted from both CNN, fused together to make a shared feature layer, and these features are fed to the classifier. We experiment with two classifiers, namely Support Vector Machines (SVM) and softmax classifier and compare their performances. The recognition accuracies of each modality, depth data alone and sensor data alone are also calculated and compared with fusion based accuracies to highlight the fact that fusion of modalities yields better results than individual modalities. Experimental results on UTD-MHAD and Kinect 2D datasets show that proposed method achieves state of the art results when compared to other recently proposed visual-inertial action recognition methods.