 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN based Multistage Gated Average Fusion for Human Action Recognition Using Depth and Inertial Sensors
Paper and Code
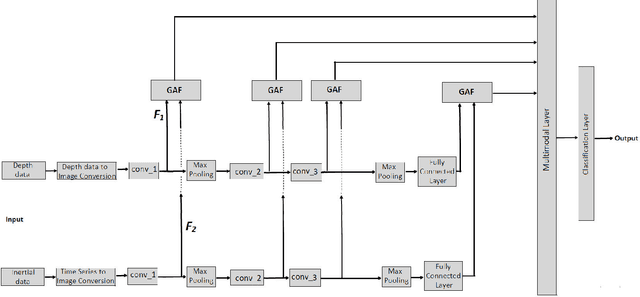
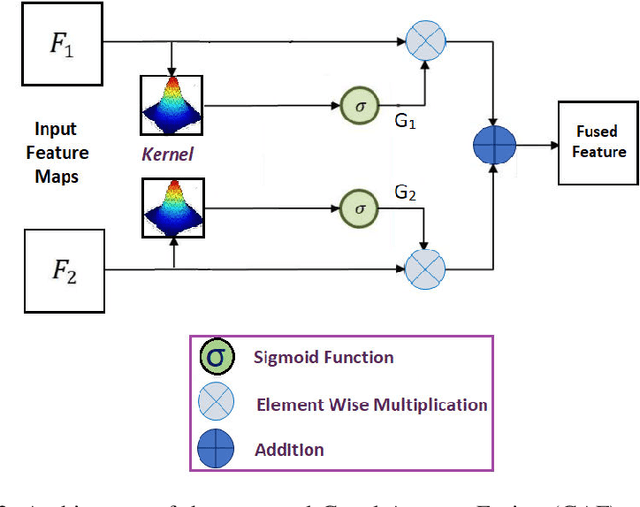
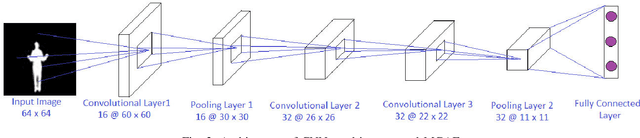

Convolutional Neural Network (CNN) provides leverage to extract and fuse features from all layers of its architecture. However, extracting and fusing intermediate features from different layers of CNN structure is still uninvestigated for Human Action Recognition (HAR) using depth and inertial sensors. To get maximum benefit of accessing all the CNN's layers, in this paper, we propose novel Multistage Gated Average Fusion (MGAF) network which extracts and fuses features from all layers of CNN using our novel and computationally efficient Gated Average Fusion (GAF) network, a decisive integral element of MGAF. At the input of the proposed MGAF, we transform the depth and inertial sensor data into depth images called sequential front view images (SFI) and signal images (SI) respectively. These SFI are formed from the front view information generated by depth data. CNN is employed to extract feature maps from both input modalities. GAF network fuses the extracted features effectively while preserving the dimensionality of fused feature as well. The proposed MGAF network has structural extensibility and can be unfolded to more than two modalities. Experiments on three publicly available multimodal HAR datasets demonstrate that the proposed MGAF outperforms the previous state of the art fusion methods for depth-inertial HAR in terms of recognition accuracy while being computationally much more efficient. We increase the accuracy by an average of 1.5 percent while reducing the computational cost by approximately 50 percent over the previous state of the art.