 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Improved Human Action Recognition Using Convolutional Neural Networks and Multimodal Fusion of Depth and Inertial Sensor Data
Paper and Code
Aug 22, 2020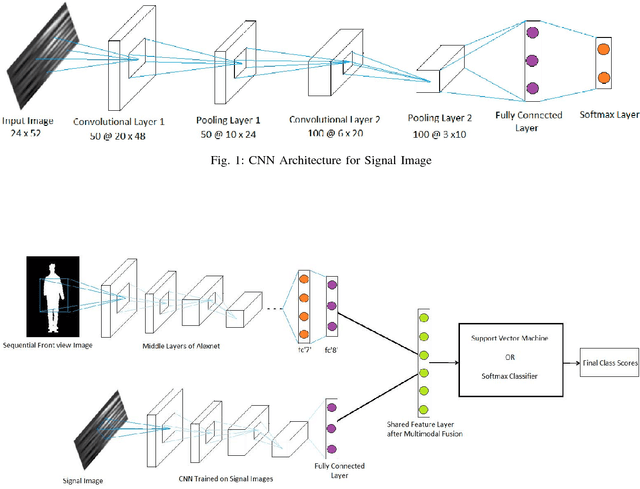


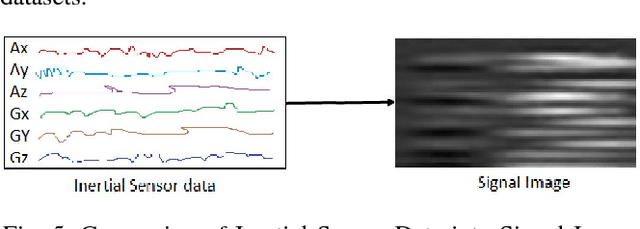
This paper attempts at improving the accuracy of Human Action Recognition (HAR) by fusion of depth and inertial sensor data. Firstly, we transform the depth data into Sequential Front view Images(SFI) and fine-tune the pre-trained AlexNet on these images. Then, inertial data is converted into Signal Images (SI) and another convolutional neural network (CNN) is trained on these images. Finally, learned features are extracted from both CNN, fused together to make a shared feature layer, and these features are fed to the classifier. We experiment with two classifiers, namely Support Vector Machines (SVM) and softmax classifier and compare their performances. The recognition accuracies of each modality, depth data alone and sensor data alone are also calculated and compared with fusion based accuracies to highlight the fact that fusion of modalities yields better results than individual modalities. Experimental results on UTD-MHAD and Kinect 2D datasets show that proposed method achieves state of the art results when compared to other recently proposed visual-inertial action recognition methods.