 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultidomain Multimodal Fusion For Human Action Recognition Using Inertial Sensors
Paper and Code
Aug 22, 2020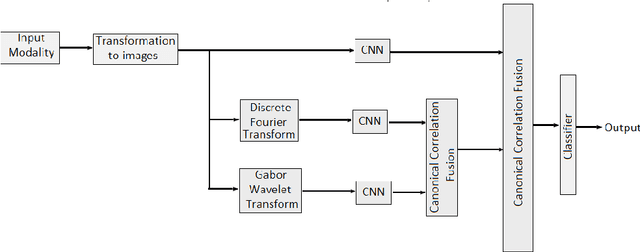

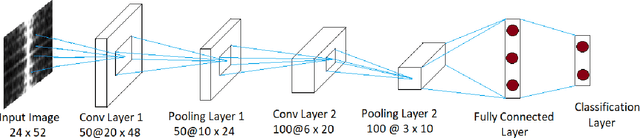

One of the major reasons for misclassification of multiplex actions during action recognition is the unavailability of complementary features that provide the semantic information about the actions. In different domains these features are present with different scales and intensities. In existing literature, features are extracted independently in different domains, but the benefits from fusing these multidomain features are not realized. To address this challenge and to extract complete set of complementary information, in this paper, we propose a novel multidomain multimodal fusion framework that extracts complementary and distinct features from different domains of the input modality. We transform input inertial data into signal images, and then make the input modality multidomain and multimodal by transforming spatial domain information into frequency and time-spectrum domain using Discrete Fourier Transform (DFT) and Gabor wavelet transform (GWT) respectively. Features in different domains are extracted by Convolutional Neural networks (CNNs) and then fused by Canonical Correlation based Fusion (CCF) for improving the accuracy of human action recognition. Experimental results on three inertial datasets show the superiority of the proposed method when compared to the state-of-the-art.