 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtended multi-stream temporal-attention module for skeleton-based human action recognition (HAR)
Nov 10, 2024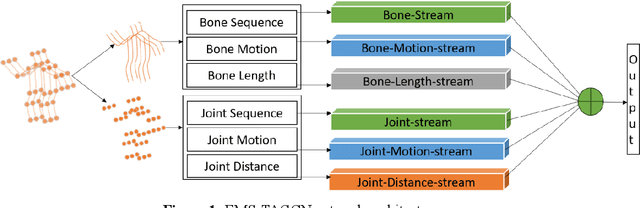
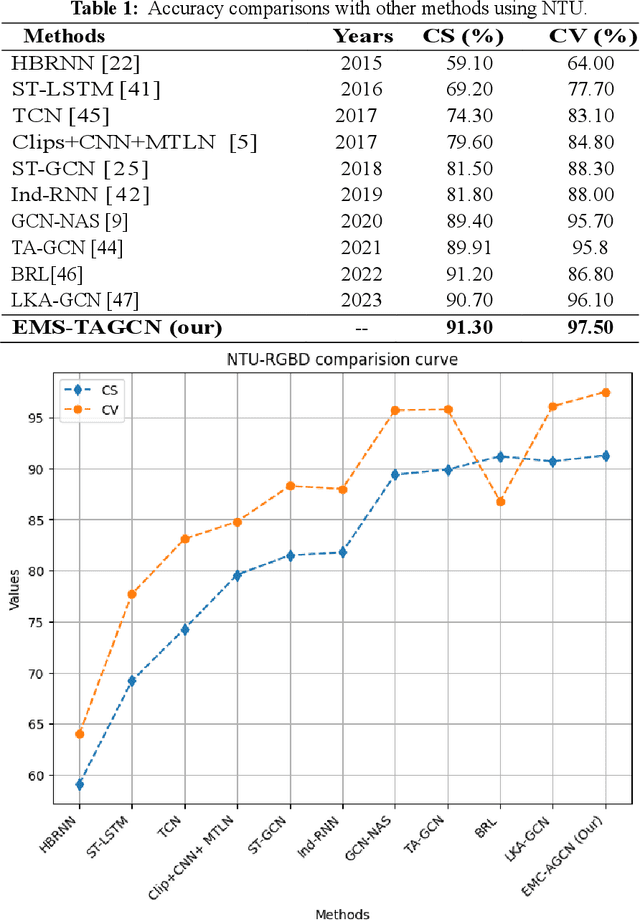
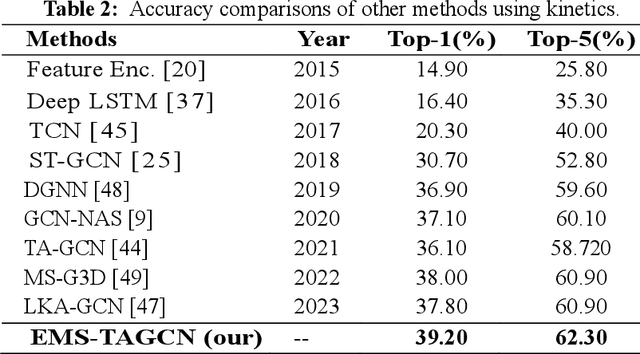
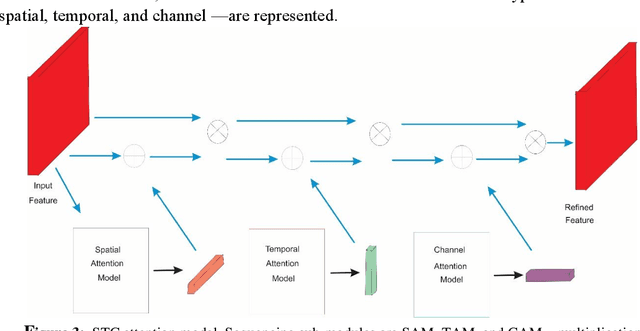
Graph convolutional networks (GCNs) are an effective skeleton-based human action recognition (HAR) technique. GCNs enable the specification of CNNs to a non-Euclidean frame that is more flexible. The previous GCN-based models still have a lot of issues: (I) The graph structure is the same for all model layers and input data.
Human Action Recognition (HAR) Using Skeleton-based Quantum Spatial Temporal Relative Transformer Network: ST-RTR
Oct 31, 2024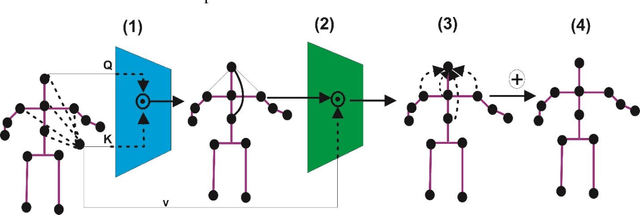
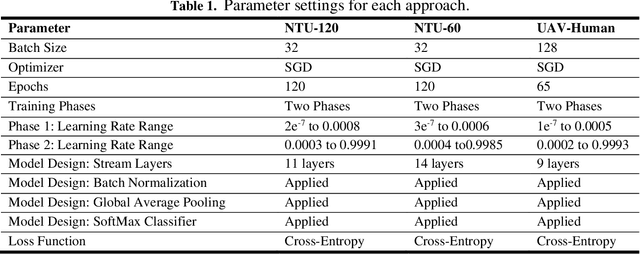
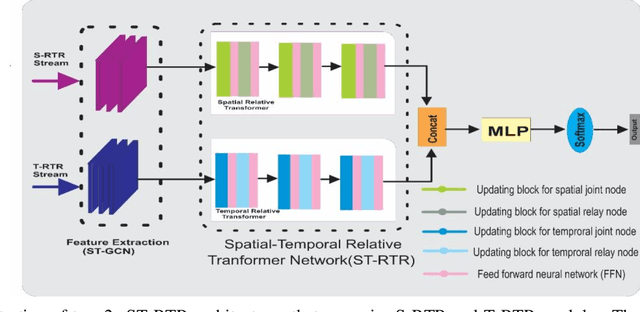
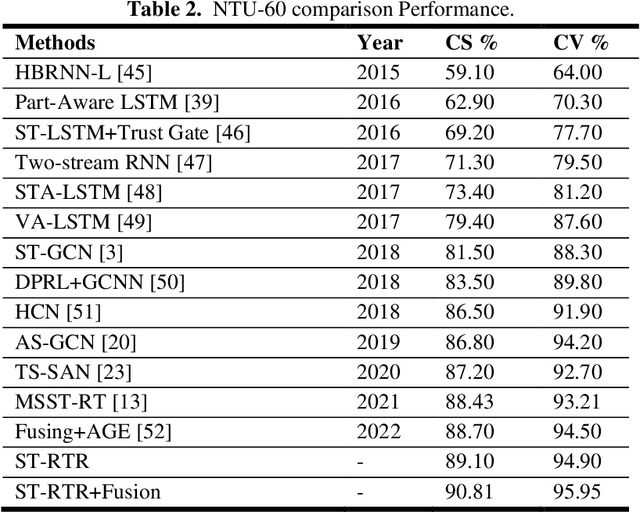
Quantum Human Action Recognition (HAR) is an interesting research area in human-computer interaction used to monitor the activities of elderly and disabled individuals affected by physical and mental health. In the recent era, skeleton-based HAR has received much attention because skeleton data has shown that it can handle changes in striking, body size, camera views, and complex backgrounds. One key characteristic of ST-GCN is automatically learning spatial and temporal patterns from skeleton sequences. It has some limitations, as this method only works for short-range correlation due to its limited receptive field. Consequently, understanding human action requires long-range interconnection. To address this issue, we developed a quantum spatial-temporal relative transformer ST-RTR model. The ST-RTR includes joint and relay nodes, which allow efficient communication and data transmission within the network. These nodes help to break the inherent spatial and temporal skeleton topologies, which enables the model to understand long-range human action better. Furthermore, we combine quantum ST-RTR with a fusion model for further performance improvements. To assess the performance of the quantum ST-RTR method, we conducted experiments on three skeleton-based HAR benchmarks: NTU RGB+D 60, NTU RGB+D 120, and UAV-Human. It boosted CS and CV by 2.11 % and 1.45% on NTU RGB+D 60, 1.25% and 1.05% on NTU RGB+D 120. On UAV-Human datasets, accuracy improved by 2.54%. The experimental outcomes explain that the proposed ST-RTR model significantly improves action recognition associated with the standard ST-GCN method.
Occluded Human Pose Estimation based on Limb Joint Augmentation
Oct 13, 2024Human pose estimation aims at locating the specific joints of humans from the images or videos. While existing deep learning-based methods have achieved high positioning accuracy, they often struggle with generalization in occlusion scenarios. In this paper, we propose an occluded human pose estimation framework based on limb joint augmentation to enhance the generalization ability of the pose estimation model on the occluded human bodies. Specifically, the occlusion blocks are at first employed to randomly cover the limb joints of the human bodies from the training images, imitating the scene where the objects or other people partially occlude the human body. Trained by the augmented samples, the pose estimation model is encouraged to accurately locate the occluded keypoints based on the visible ones. To further enhance the localization ability of the model, this paper constructs a dynamic structure loss function based on limb graphs to explore the distribution of occluded joints by evaluating the dependence between adjacent joints. Extensive experimental evaluations on two occluded datasets, OCHuman and CrowdPose, demonstrate significant performance improvements without additional computation cost during inference.
Discriminative Multiple Canonical Correlation Analysis for Information Fusion
Feb 28, 2021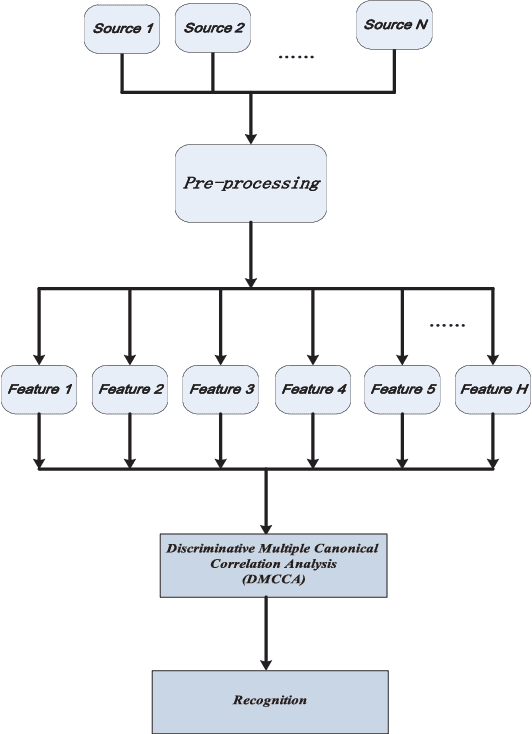
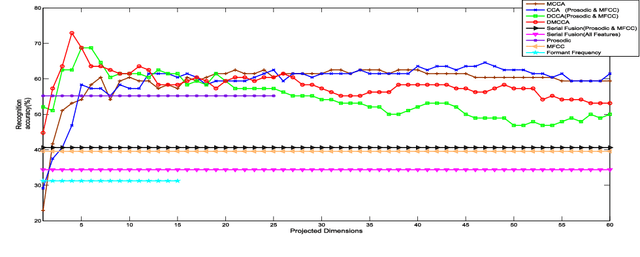
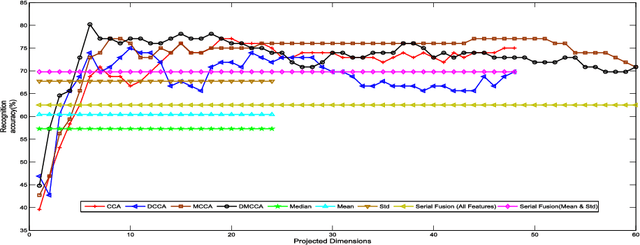
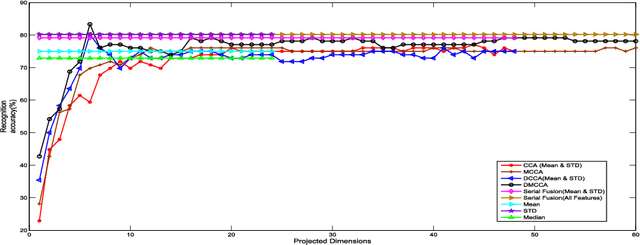
In this paper, we propose the Discriminative Multiple Canonical Correlation Analysis (DMCCA) for multimodal information analysis and fusion. DMCCA is capable of extracting more discriminative characteristics from multimodal information representations. Specifically, it finds the projected directions which simultaneously maximize the within-class correlation and minimize the between-class correlation, leading to better utilization of the multimodal information. In the process, we analytically demonstrate that the optimally projected dimension by DMCCA can be quite accurately predicted, leading to both superior performance and substantial reduction in computational cost. We further verify that Canonical Correlation Analysis (CCA), Multiple Canonical Correlation Analysis (MCCA) and Discriminative Canonical Correlation Analysis (DCCA) are special cases of DMCCA, thus establishing a unified framework for Canonical Correlation Analysis. We implement a prototype of DMCCA to demonstrate its performance in handwritten digit recognition and human emotion recognition. Extensive experiments show that DMCCA outperforms the traditional methods of serial fusion, CCA, MCCA and DCCA.
The Labeled Multiple Canonical Correlation Analysis for Information Fusion
Feb 28, 2021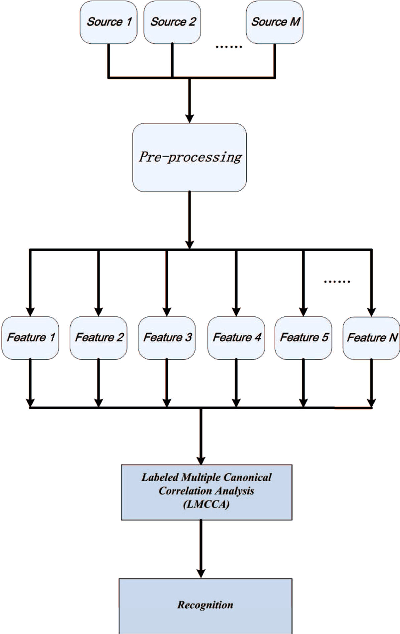
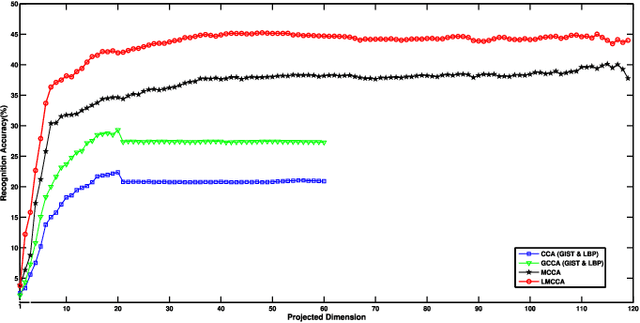

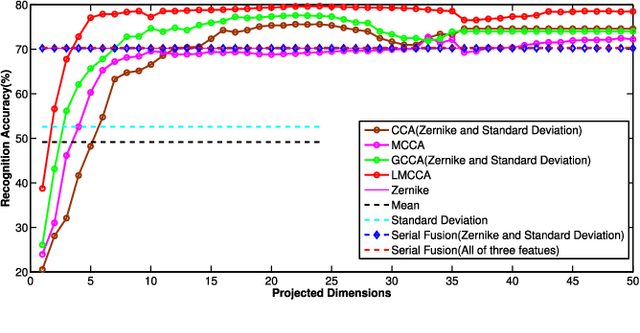
The objective of multimodal information fusion is to mathematically analyze information carried in different sources and create a new representation which will be more effectively utilized in pattern recognition and other multimedia information processing tasks. In this paper, we introduce a new method for multimodal information fusion and representation based on the Labeled Multiple Canonical Correlation Analysis (LMCCA). By incorporating class label information of the training samples,the proposed LMCCA ensures that the fused features carry discriminative characteristics of the multimodal information representations, and are capable of providing superior recognition performance. We implement a prototype of LMCCA to demonstrate its effectiveness on handwritten digit recognition,face recognition and object recognition utilizing multiple features,bimodal human emotion recognition involving information from both audio and visual domains. The generic nature of LMCCA allows it to take as input features extracted by any means,including those by deep learning (DL) methods. Experimental results show that the proposed method enhanced the performance of both statistical machine learning (SML) methods, and methods based on DL.